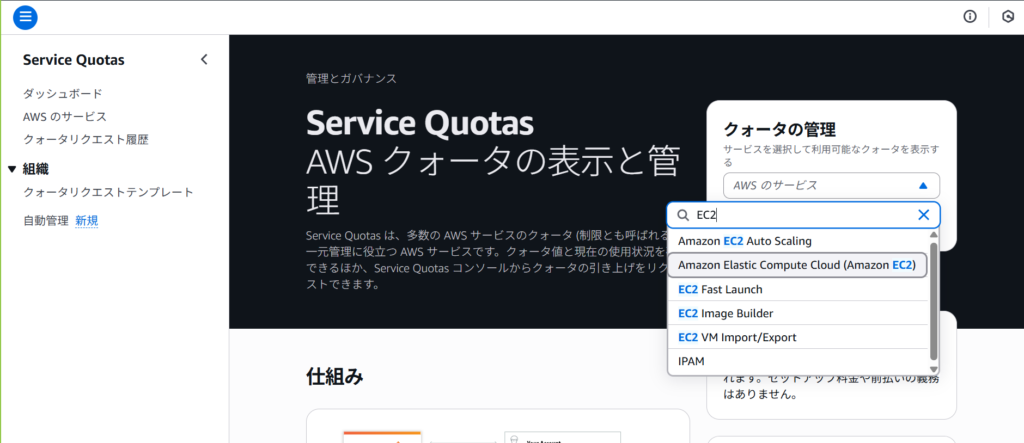
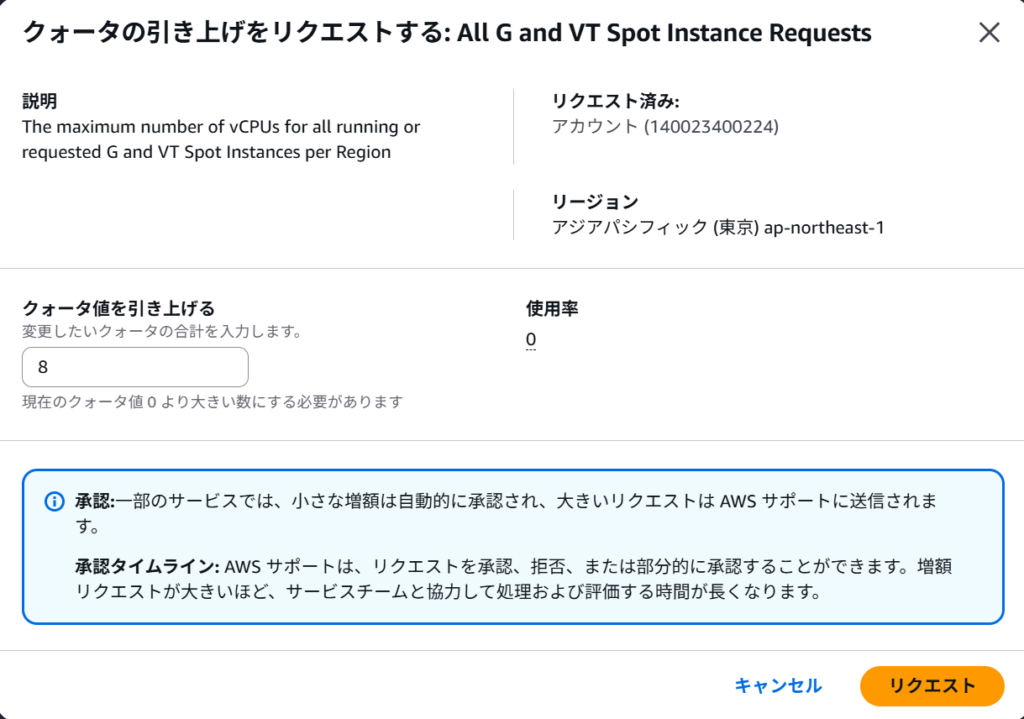
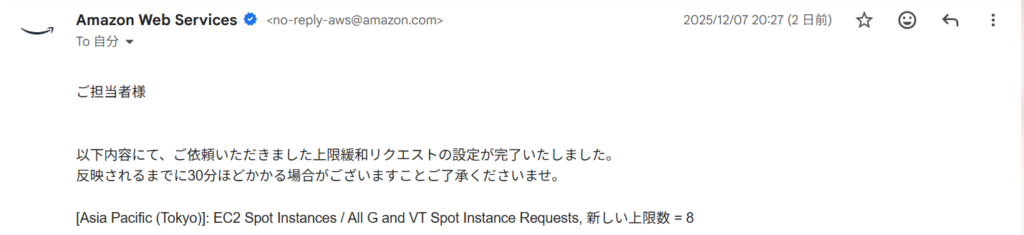
Power Platform
組織チームのメンバーはサービスの直感的なローコード / ノーコード セットを使用して独自のソリューションを構築できる。構築プロセスを簡略化
[公式:Power Platform ]
★開発コーディングについて…・ノーコード :ソースコードを全く書かない・ローコード :最小限のソースコードで開発を行う手法
・Azure サービス を Power Platform と共に使用する
●管理センター
Microsoft Power Platform 管理センター Power Apps、Power Automate、Microsoft Dataverseなど 、Power Platform全体の管理 Microsoft 365 管理センター Microsoft 365アプリやサービス(例: Outlook、Power Appsなど) のライセンス管理、ユーザー管理、セキュリティ設定を行うためのポータル。ユーザーにPower Appsのライセンスを割り当てられる。
★一般データ保護規則(GDPR) ユーザーから個人情報へアクセスするための利用条件の同意を得る ユーザーが未成年かを識別し、未成年の場合はブロックする
◇ビジネスバリュー
[情報を展開する]
従業員の期待の変化 ミレニアル世代や Z 世代に時代が遷移する中、各組織はそれら世代の能力を有効活用するためによりカスタムかつ合理化され、コラボレーションに対応したデジタル エクスペリエンスを提供できる必要がある。すなわち移り変わりゆく世代ユーザに触れてもらうようなリソースを提供する必要がある。 カスタムアプリケーション開発のコスト上昇 開発するための初期コストだけでなく、メンテナンス コストも考慮すること。 より俊敏性を高める必要性 ビジネス戦略とニーズがすばやく変化するため、組織は変化するニーズに基づいてソリューションを(マイナーリリースなど)迅速に構築できる必要があります。 開発を効率的にスケーリングする必要性 開発プロセスの一部に市民開発者 (パワー ユーザー) を責任ある方法で組み込むことにより、組織全体の成長を可能にするハイブリッドな開発チームを組織できます。
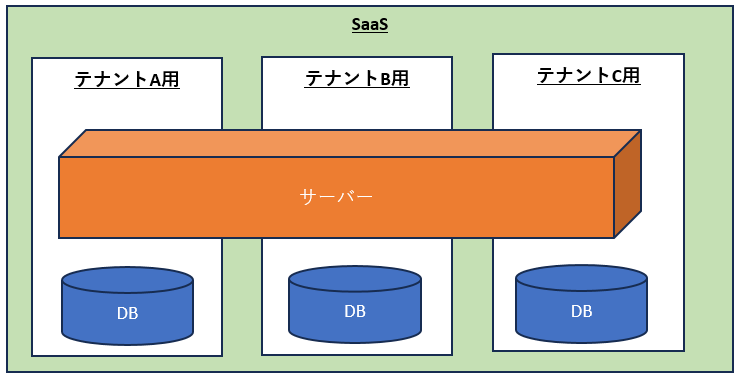
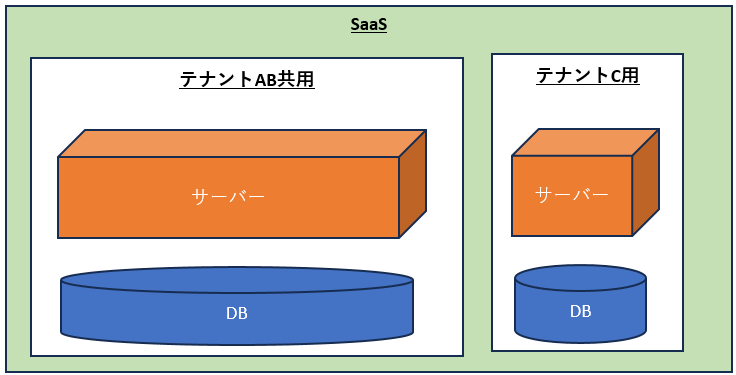
◇ Power Platform 環境
[情報を展開する]
環境を複数作成し、開発用 、テスト用(SandBox) 、および実稼働用 の環境 を 1 つずつ設定することで、ソリューション開発やデータ ストレージの管理を効果的に行うことができる。
★環境とは… テストと本番の環境を別々に管理することでアプリやデータを安全に展開することができる エンドユーザーに地理的に近い環境を配置することで高速な応答時間を実現できる
Microsoft Azure AD テナント 環境はそれぞれ、Azure AD テナントに作成。テナント内のユーザーだけが、環境内のリソースにアクセスできる。環境は地理的な場所 (米国など) にバインドされる。 Dataverse データベース 環境ごとに1 つプロビジョニング 。Microsoft Dataverse 環境を使用すると、そのデータベースに関連付けられたユーザー アクセス、セキュリティ設定、およびストレージを管理できる。データベースは、その地理的場所にあるデータセンター内に作成される。その環境で作成したすべての項目 (接続、ゲートウェイ、Power Automate を使用しているフローなどを含む) も、その環境の場所にバインドされる。
※既定値 環境 権限を付与されていなくても
※ドメイン 環境 :Power Apps の機能を実証する
●マネージド環境 【環境制御】 分析情報
共有を制限 ユーザーによる キャンバスアプリの共有範囲 を管理者 週ごとの使用分析情報 分析結果がメールボックスに毎週配信される。分析には、上位のアプリ、影響の大きいメーカー、安全にクリーンアップできる非アクティブなリソースの詳細 などの情報が含まれる。 データポリシー データを共有できる 消費者コネクタ を定義することで、データの管理方法 Power Platform のパイプライン 作成した環境 を必要な数だけ関連付けて、パイプライン を管理または実行するユーザーとアクセスを共有できる。ソリューションチェッカー ソリューションの高度な静的分析チェックを、一連のベスト プラクティス ルールに従って実行して、問題となり得るパターンを特定できる。
◇ トリガー
[情報を展開する]
ポーリングトリガー 定期的に指定された情報源をチェックして、新しいデータや変更がないかを確認 プッシュトリガー 情報源から即時に通知を受け取り、ワークフローを起動する。
◇ アクセス制御
[情報を展開する]
●ポリシー
テナントレベル Power Platformの全体的なセキュリティ ポリシーを管理できる。すべてのユーザーや環境に適用される広範なポリシー。これにより、顧客データの共有制限やデータソースへのアクセスを制限することができ、テナント全体でセキュリティを強化できる。 環境レベル Power Platformの特定の環境内でデータのアクセス 制御やセキュリティポリシーを設定できる機能。特定の環境内でのユーザーのデータ共有やデータソースへのアクセスを細かく制御することができる。ユーザーは管理者によって明示的に許可されたデータソースにのみ接続できるように設定できる。 データ損失防止 (DLP) ユーザーが意図せず組織のデータを公開する ことを防ぐガードレール。環境レベル またはテナント レベルで定義することができ、保護と生産性のバランスが適切に取れた実用的なポリシーを柔軟に策定することができる。
●アクセス制御
ロールベース ユーザーの役割ごとに全体的な権限を付与 レコードベース 個々のレコードに対して権限を付与する フィールドベース 一定の属性(フィールド)へのアクセスを制御するための機能 アプリケーションベース アプリ全体のアクセス権を管理する
・組織内のコネクタの使用を管理および制御する際に役立つ。 コネクタは以下のように分類できる。
ビジネス : ビジネス用データをホストするコネクタ非ビジネス : 個人用のデータをホストするコネクタブロック済み : 1 つまたは複数の環境での使用を制限するコネクタ
◇ データ保護(暗号化)
[情報を展開する]
【暗号化】 ユーザーのデバイス とMicrosoft データセンター 間で転送されるデータは、業界標準のトランスポート層セキュリティ(TLS)を使用してすべてのパブリックエンドポイントが保護される。API アクセス
★TLS…
◇ 連携機能
[情報を展開する]
Microsoft AppSource ビジネス向けのソリューションと拡張機能のマーケットプレイス。多様な業界やビジネスニーズに対応した機能が掲載されており、Microsoftの各種プラットフォームやサービス(Power BI、PowerApps、Dynamics 365など)と連携できる製品が多数ある。 Microsoft Azure Marketplace Power BIに加えて、他の企業が提供するサービスを統合し Microsoft Store 個人向けのアプリやゲームのダウンロードに特化。ビジネスソリューションはない。
◇ Microsoft Teamsとの連携
[情報を展開する]
★Teamsとは…
Teams の主な利点の 1 つは、その拡張性と適応性。これは、組織でユーザーのニーズに基づく Teams 用カスタムアプリケーションを構築することが可能になることを意味する。
Power Platform は、ローコードの属性を活かしてTeams対応アプリを迅速に構築するための革新的なゲートウェイ になる。そのためすべての Power Platform コンポーネントは、Microsoft Teams で使用できる。
※後述のコネクタにより、すべての Power Platform ソリューションは、Teams などの Microsoft 365 アプリと統合できる。この統合により、ユーザーは Teams 内で Power Apps を使用
【承認状況確認】
Power BI Teams ワークスペースでのレポート機能がサポートされ、対話型の Power BI コンテンツの共有や、Teams のチャネルまたはチャットを使った他のユーザーとの共同作業が可能になる。パッケージ化された Power BI アプリコンテンツをアプリとして配布したり、Power BI でテンプレートアプリを作成したりすることができる Power Apps アプリ開発者はTeams 内でアプリやワークフローを作成および編集するために必要なリソース類を統合されたプラットフォームの中で実行できる。これにより、メンバーは、複数のアプリやサービスを切り替えることなくアプリを迅速に公開し、チーム メンバーと共有することが可能になる。ユーザーがインシデントを報告する必要がある場合、Microsoft Teams を使用しながらインシデントを報告することができる Power Automate 繰り返しの作業タスクを自動化するフローを Teams 環境内で直接作成できる Copilot Studio 会話型エージェントの作成、管理、および公開を Teams 内から簡単に実行できる Dataverse for Teams Dataverse for Teams は、組み込みローコード データ プラットフォームであり、ユーザーは Power Apps および Power Automate を使用して、Microsoft Teams でカスタム アプリ、ボット、フローを直接構築できる
Power Apps 【アプリ開発】
ノーコード/ローコード のアプリ開発プラットフォーム で、Excel の式の概念 を活用してアプリを構築 できる。高度な機能 を活用してカスタマイズでき、紙ベースのプロセスをデジタル化 し、Microsoft Dataverse やオンライン/オンプレミスのデータソース と連携し、数百のコネクタ
[公式:Power Apps ] [リソース詳細:Power Apps ]
・すべてのデバイスで動作する Web アプリケーションやモバイルアプリケーションを作成できるオンライン
【その他構成要素】
式(Expressions) アプリケーション内での計算やデータ操作を行うための機能 数式 フィールドの条件に基づいた動的な表示を設定するために使用されるコンポーネント データゲートウェイ オンプレミスのSQL ServerデータベースやSharePointサイトなど、クラウドではないデータソースのサービス Power Apps Maker Portal アプリケーションを作成し、環境に関連付けられた Dataverse インスタンスを管理する アクセシビリティ チェッカー Power Appsで作成したアプリが多くの人に使いやすいかどうかを確認するためのツール
◇ レコードレベルの権限
[情報を展開する]
Create (作成) 新しいレコードを作成する権限 Read (読取) レコードを読む権限 Write (書き込み) 既存のレコードを更新する権限 Delete (削除) レコードを削除する権限 Append (追加) 現在のレコードを他のレコードに関連付ける権限 Assign (アサイン) レコードの所有権を他のユーザーに移譲する権限 Share (共有) レコードに対するアクセスを他のユーザーに共有する権限
◇ 2つのアプリ構成
[情報を展開する]
【作成判断基準:どちらのアプリで作成するか】 データソースは何か ユーザーインターフェースはカスタマイズが必要か
【2つのアプリの違い】 ユーザーの操作を考慮したアプリ設計 が求められ、「キャンバスアプリ」 と「モデル駆動型アプリ 」の2つのタイプがある。
キャンバス モデル駆動型 各アプリの違い 画面レイアウトを自由に設計できる Dataverseのデータモデルに基づき、UIの多くが自動的に生成される。 データソース Dataverse駆動ではない Dataverse駆動 アプリの目的 タスクまたはスクリーン向け バックオフィス/プロセス向け UI カスタム UI レスポンシブ/一貫性のある UI デバイス統合 ユーザーのパーソナル化 簡単に埋め込み可能 データ リレーションシップの操作 UI のセキュリティ トリミング
◇ キャンバスアプリ
[情報を展開する]
電話や紙のフォームを使った煩雑なプロセス をMicrosoft Power Apps のキャンバスアプリ で特定の業務タスクをスムーズに実行できる独自アプリを構築できる。組織の業務に合わせたアプリを作成できる。以前のバージョンを復元できる機能もある )
※Power Pagesに組み込むことができない
●コレクション機能
【特徴】
自由なレイアウト 開発者がドラッグ&ドロップで画面デザインやUIを自由にカスタマイズできる さまざまなデータソースに接続 Excel、SharePoint、SQL Server
・ Excel や SharePoint のデータからアプリを作成 したり、Figma のデザイン を Power Apps に変換 可能埋め込み先 :Teams、SharePoint、モデル駆動型アプリ
・Power Fx 数式を使用して、画面の視覚要素と、データの取得や表示などのアクションを制御する。フォーム処理と物体検出のための AI コントロールを含めることができる。
【環境】 ・ブラウザーやモバイルデバイス で実行 できる作成者の言語に合わせて 表示される日付や数字のフォーマット はエンドユーザーのデバイス に合わせて表示される
●Power Apps Studio
【コントロール】
閲覧画面(Browse Screen) データソースからのレコードの一覧を表示するために使用される。ユーザーはここで目的のレコードを探し、選択して情報を表示できる。 詳細画面(Details Screen) 閲覧画面で選択されたレコードの詳細情報を表示するために使用される。詳細情報の閲覧に適している。 編集と作成の画面(Edit and Create Screen) 新しいレコードを作成したり、既存のレコードを編集したりするために使用される。
【構築の流れ】
①アプリの形式を選択 ※後からの変更は不可 ②データと接続 データ接続を設定し、1,000以上のコネクタを活用して外部データと統合する。 ③画面設計 ・ギャラリーコントロール:データ表示としてレコード一覧を表示 ④入力コントロール追加 テキスト入力、ボタン、ドロップダウンなどの入力コントロールを追加し、アプリの操作性を向上させる。 ⑤高度な機能利用 カメラやバーコードスキャナーなどのハードウェア連携や、AIを活用した名刺リーダー・物体検出などを導入可能。 ⑥関数活用 データ処理やアニメーションの追加が可能。Excelのような関数を活用し、複雑なコード不要で柔軟な設計ができる。 ⑦レスポンシブデザイン適用 アプリのレイアウトはレスポンシブデザインを採用し、異なるデバイスに適応させることができる。 ⑧Copilotの利用 Copilotを活用して、AIがアプリ設計をサポートし迅速な構築を実現。
◇ モデル駆動型アプリ
[情報を展開する]
Microsoft Dataverse との構成が基本データ管理の効率化と業務プロセスの改善に優れた アプリ。サイトマップ
・ExcelへのエクスポートやPower BI 統合によるデータ分析 ・レポート作成 複数の外部データソースとの統合に制限
【特徴】
標準化されたインターフェース データとプロセスに基づいた設計に最適 Microsoft Dataverseとの統合が強力 Dataverseをデータソースとして使い、複雑なビジネスプロセスやワークフローを自動化 データ管理重視 顧客管理やサプライチェーン管理など、データ管理が中心のシステムに最適
【主なコンポーネント】
●データコンポーネント
テーブル データを記録するアイテム で、テーブルは複数のレコード(顧客)を一括して表示できる。標準テーブル が多数用意されており、カスタマイズ可能 。必要に応じてカスタムテーブル をいちから作成できる。●アカウントテーブル :顧客、ベンダー、従業員などのエンティティに関する情報を格納するために使用されるテーブル。列 テーブル内のデータの種類を定義 する要素であり、入力や選択できるデータの種類 を決める。データ型には、テキスト、数値、日付と時刻、通貨、ルックアップ (他のテーブルとの関係を作成)など。リレーションシップ 複数のテーブル間の関係性を定義 。主な種類には、1:N(一対多)、N:1(多対一)、N:N(多対多)がある。ルックアップ列 を追加すると、2つのテーブル間に新しい 1:N のリレーションシップ が作成され、それをフォームに追加 することでデータの関連付けを簡単に行える。選択肢 事前に定義されたオプション の中からユーザーが選択できるコントロールを表示。各オプションには数値とラベル を設定可能で、単一または複数の値を選択 できる柔軟な設計になっている。
●UIコンポーネント
サイトマップ アプリのナビゲーションを指定するエリア (Area): サイトマップの最上位の要素で、主要なセクションやカテゴリーを表す。グループ (Group): エリア内で関連するサブエリアをまとめるための要素。エリア内の中間的なカテゴリーやセクションを定義する。サブエリア (Subarea): サイトマップの具体的なアイテムやページを指し、リソースへのリンクを示す。 フォーム 単一の ビュー 特定のテーブルの行の一覧がアプリケーションでどのように表示されるかを定義する
※サイトマップのサブエリア
●フォームコンポーネント
メイン(Main) 一般的なフォームであり、エンティティの各レコードに対する主要なインターフェース。多くのケースで使用され、レコードの新規作成や編集に適する。 簡易作成(Quick Create) 新しいレコード 簡易表示(Quick View) 一つのエンティティから別のエンティティへの参照で使用される。関連するエンティティのデータをメインフォームで簡単に表示できる。 カード(Card) モバイルデバイス用
●ロジックコンポーネント
ビジネスプロセスフロー 従業員が順番にタスクを進められるように プロセスを可視化し、ユーザーが統一された対応をできるようにする。ビジネスルール フォームの入力を制御し、特定の条件に基づいて フィールドの表示 、非表示 、必須化など を設定できる
【アプリ内のビュー変更方法】 1. フィルターの設定 ビュー内で表示されるデータ をフィルタリング する条件を設定。特定の属性や値に基づいてデータを制限する。
2.ソート順の設定
Power Appsサイト 【ビュー変更 GUI】 モデル駆動型アプリの作成、編集、公開のための主要なインターフェイス 。ビューを作成または変更するためのGUI ソリューションエクスプローラー モデル駆動型アプリの構造 とコンポーネント を閲覧および編集するためのツール。ここでビューのプロパティを調整し、フィルター、ソート、および表示されるフィールドなどを変更できる。アプリデザイナー 【アプリ構成編集】 モデル駆動型アプリに含まれるテーブル、ビュー、フォームなどの構成要素を編集・管理できるツール。開発者やカスタマイザーがノーコードでアプリの設計を行うために用いられる。ビューを追加、削除、変更できるだけでなく、ビューの表示順序やソートの基準なども簡単に設定できる。ダッシュボード
【アプリ作成手順】
Power Appsにサインし、環境を選択 ソリューションを作成してテーブルを追加 モデル駆動型アプリの作成 アプリにページを追加(コンポーネントとしてのページを設定) アプリを保存 アプリを公開
Power Automate
複数のアプリケーションやサービスを統合して自動化するためのワークフローを作成 繰り返される業務プロセスの自動化 を支援。
[公式:Power Automate ] [リソース詳細:Power Automate ]
※個々のユーザー向けの自動化だけでなく、エンタープライズレベルのプロセス自動化も提供。シンプルなインターフェイス によって、あらゆるレベルの技術的スキルを持つユーザー (初心者から熟練の開発者まで) が作業タスクを自動化できる。
◇ 機能
[情報を展開する]
トリガー 何がフローを開始するかを定義する アクション フローが何を行うかを決める(フローで実行される個々のタスク) 変数 データを一時的に保存しておくために使用する 条件 特定の条件が満たされた場合に異なるアクションを実行する機能 ループ リストやコレクションの各項目に対して繰り返し処理を行う
【トリガーのオプション】
変更があった場合 データが変更されたときに実行される スケジュールに従う 1 日の特定の時刻に、繰り返しでトリガーされるフローを設定できる ボタンを押すとき オンデマンドでのフローの「実行」を制御できるトリガー方法
【その他機能】
●[アクション アイテム] メニュー
●ビジネスイベント
●プロセス マイニング さまざまなプロセスを視覚化
◇ ワークフロー
[情報を展開する]
・組み込みテンプレートのフローを追加したりアクションを削除することができるコードを書かずGUIのみでフローを作成することができる
【ワークフローの種類】
ビジネスプロセスフロー これらのフローはモデル駆動型アプリ で使用される。一連の決められたタスクを順番に対応するような業務プロセスを段階的に到達まで クラウドフロー 最も使用されるフロー。トリガーされると、クラウドフローは、コネクタを使用してさまざまなサービスとやり取りをする。指定した日付と時刻(スケジュール)に自動的に開始できる API呼び出しに基づいてアクションを実行する 自動フロー インスタントフロー 予定フロー デスクトップフロー アプリケーション Web サイト
※クラウドフローの変更
【テスト】
フローチェッカー テスト機能 主な目的 フローのエラーや問題点を特定し、改善提案 フローの動作を実際にテストする 使用時の状況 フローを実行する前、または問題が発生した場合にフロー内の問題を特定するために使用する フローを実行してその動作を確認したい場合、特に変更や新しいフローを作成した後にその動作をテストするために使用する 提供する情報 エラーや警告とその理由、そして修正の提案 フローが実際にどのように動作するか、どのアクションがトリガーされるか、どの条件が満たされるか等の実行結果の情報
◇ アプリケーション
[情報を展開する]
Power Automate ポータル 【フロー管理】 作成者にとって単一のアクセスポイント となり、Power Automate フローの設計・作成、および作成したフロー の管理 監視 Maker Portal : Power Automate で使用できるすべての要素にアクセスできる Power Automate Mobile 【携帯デバイスからアクセス】 外出時に Power Automate の機能にアクセス できる。Android デバイスと iOS デバイス両方で利用でき、最適化されている。デスクトップ用 Power Automate 【ローカル自動化】 デスクトップで繰り返されるすべてのプロセスを自動化 Windowsオペレーティングシステムにインストールする必要がある
【Power Automate Mobileでできること】 Power Automate モバイルアプリケーション では以下のことができる。
インスタント フローを実行 作成したインスタントフローはここで使用することができる。フローを選択すると実行される 活動を管理する 承認が必要な項目と通知に簡単にアクセスできる 新しいフローを作成 アプリケーション内から直接新しいクラウド フローを作成できる 既存のフローを管理 作成したクラウドフローを簡単に監視でき、変更を加えられる
◇ Microsoft 365との連携
[情報を展開する]
【例1】
【例2】 Power Automate デスクトップ フロー
Power BI
データの分析と視覚化を行うビジネス分析サービス。データ分析のプロセスを簡素化 し、レポートとダッシュボードを構成するデータの可視化
[公式:Power BI ] [リソース詳細:Power BI ]
【その他要素】
サブスクライブ Power BIでダッシュボードやレポートの最新情報を自動的にメールで受け取るための機能。 使用状況メトリック 作成したレポートやダッシュボードが実際にどれくらい閲覧されているかを見るためのツール。 クエリエディター 複数のテーブルにまたがるデータを統合して分析可能な形に整える。 Q&A 機能 自然言語 Power BIに取り込んだデータを基に適切なグラフや表などの視覚的な回答を得る ことができる機能。自然言語 コーディング不要で直感的に操作できる。非技術者でも簡単にデータの可視化が可能。また、Q&Aビジュアルは、ダッシュボードやレポートに追加することができ、ユーザーが自分の言葉でデータを探索することを支援する。 Phone ビュー Power BI モバイル アプリでレンダリングされるビュー。複数のページを含めることができるのはレポートのみ。Power BI Desktop または Power BI モバイル アプリを使用してダッシュボードを作成することはできない。
◇ コンポーネント
[情報を展開する]
Power BI は以下の 3 つの主要コンポーネントで構成されている。
Power BI Desktop (Windows向けデスクトップアプリ)ローカル環境でデータのモデリング、計算列、変換、レポート作成を行う。 Power BI サービス (オンラインSaaS)作成レポートをクラウド上で共有・公開し、組織内外でアクセスできるようにする。基本的なレポート作成と編集が可能だが 、高度なデータ変換や計算列の作成などはできない モバイル Power BI アプリ (スマートフォンやタブレット向け)
【データコネクタ一覧確認:[Power BI Desktop]】 「データの取得(Get Data)」メニュー を使用することで、利用可能なすべてのデータコネクタ(Excel、SQL Server、SharePoint、Web API など)を一覧で確認できる。
【ストレージモード:[Power BI Desktop]】
インポートモード データソースからデータを取り込んでPower BI Desktopに保存する。データ量がそれほど多くない、または高速なパフォーマンスが必要な場合に適する。 DirectQueryモード データは元のデータソースにそのまま残る。レポートやダッシュボードを見る人が何かをクリックするたびに、Power BIはリアルタイムでそのデータソースに問い合わせる。大量のデータを扱う、または常に最新のデータが必要な場合に最適。 デュアルモード このモードは上記の2つを組み合わせたもので、インポートとDirectQueryの両方の利点を活かすことができる。
◇ 構成要素
[情報を展開する]
〇容量(キャパシティ)
コンテンツをホスト・配信するためのリソースを 容量(キャパシティ) と呼ぶ。● 共有キャパシティ● 専用キャパシティ
〇ワークスペース
Power BI の ダッシュボード、レポート、データセット、データフロー を管理するためのコンテナ 。●マイ ワークスペース (個人専用)個人用で、所有者のみがアクセス可能。 ダッシュボードやレポートを共有できる ● ワークスペース共同作業を行う場所 。ダッシュボード や データセット を共有でき、メンバーの大半には Power BI Pro ライセンス が必要 。また、ワークスペースは 組織の Power BI アプリの作成・管理 にも利用される。アプリはダッシュボードやレポートのコレクション で、閲覧者は編集できない。アプリの利用には Pro ライセンスが必須ではない。
【ワークスペースからアプリを発行する 】
〇セマンティックモデル
レポート作成と視覚化の準備 ができたデータソース データフローからのデータ取得 も可能。
【ワークスペースで共有 】 ワークスペースに関連付けられる ほか、複数のワークスペースで共有可能 。ワークスペースを開くと、関連セマンティック モデルが セマンティック モデル タブ に一覧表示される。例えば、OneDrive の Excel ブックや、オンプレミス SSAS モデル、Salesforce データなど、さまざまなデータ ソースが統合可能。
【共有セマンティックモデル 】 「信頼できる 唯一の情報源」 を構築できる。組織のデータモデラー が最適なセマンティックモデルを作成・共有し、レポート作成者はそのデータを利用して精度の高いレポートを作成できる。Power BI のレポート作成により、組織の意思決定をサポートする一貫したデータ活用が可能になる。
〇レポート
折れ線グラフやマップなど視覚的 な分析情報をまとめたページデータセットと接続 し、レポートを新規作成、インポート、または自動生成 できる。
・ダッシュボードが最初に表示され、ダッシュボードのタイルをクリックすると、関連する レポートへアクセス できる。ワークスペース から、関連するレポートがリスト表示でき、各レポートは 1 つのデータセット に基づいている。レポートを選択すると、詳細を確認できる。
【レポートの操作モード】 ●閲覧表示(既定) :レポートの閲覧のみが可能●編集表示(編集権限がある場合) :レポートの構成や見た目を変更できる
〇ダッシュボード
タイル とウィジェット を含む単一のキャンバスレポートや Q&A からピン留めされた視覚エフェクト を示し、レポートページ全体を 1 つのタイルとして追加することも可能。
・所有者 は、基になるデータセットやレポートを編集可能 共有されたダッシュボード は 閲覧・操作可能だが、変更保存不可
●ピン留め(Pin)
◇ その他構成要素
[情報を展開する]
〇データセット
ストリーミングデータセット プッシュデータセット リアルタイムデータをPower BIのダッシュボードに表示するために最適。速度 : 非常に高速。データは瞬時に反映。用途 : リアルタイムのデータモニタリング保存 : データは一時的にしか保存されず、過去のデータを後から見れない 速度 : 高速だが、ストリーミングに劣る用途 : リアルタイムとバッチ処理両方で使用可能保存 : データはPower BIサービスに保存され、後から参照することができる
〇集計機能
大量のデータを要約し、簡単にアクセスできる形に変換する。・大量のデータを処理するのに向いている ・テーブルのサイズを小さくすることでパフォーマンスを向上させる
〇フィルター
※詳細は参照先サイトにて 【主なフィルター】
自動フィルター レポートのビジュアル間の連動や選択操作によって自動的に適用 手動フィルター レポートのビジュアル間の連動や選択操作によって自動的に適用 ドリルダウン フィルター 階層構造を持つデータ(例:年 → 月 → 日)を段階的に掘り下げて分析できる機能
〇テンプレートアプリ
レポート、ダッシュボード、データセットなどを含むアプリとしてパッケージ化されており、外部ユーザーが自分のPower BIテナント内でインストールし、接続情報やフィルターなどを設定して自社向けに活用することが可能 。ほぼコード不要 で Power BI アプリを構築し、顧客向けに展開できる。すぐに利用可能な コンテンツを作成し、自身で公開可能。
【顧客向けの利便性】 自分のアカウントに接続して使用可能 で、専門家がビジネスユーザー向けに 簡単にデータへアクセスできる 環境を提供
◇ 異なるデータの統合
[情報を展開する]
Power BI のデータ変換 とクリーニング 概要
データの統合の課題 クリーニングと変換 が必要になる。
【Power BI Desktop でのデータ処理】 レポートビュー :クエリを作成し、視覚化を設定・共有可能データビュー :データモデルに基づき、メジャーの追加やリレーションシップの管理が可能モデルビュー :データ間の関係をグラフィカルに表し、管理・変更が可能
◇ 分析情報機能
[情報を展開する]
Power BI は AI を活用した複数の分析情報機能を提供している。
レポート データの異常や傾向をレポート上で特定 ビジュアル データポイントの変動を分析・説明 ダッシュボード タイル データをインタラクティブに可視化 データセットのクイック データセットの分析情報を自動生成 Power Query の AI Insights Azure の機械学習モデルを活用してデータ分析
〇通知
レポートやビジュアルを操作すると、自動で分析情報が実行 される。異常 や傾向 を検出すると確認または無視を選択 できる。
【メリット】 売上や業務の変化 を見逃さない 「上位の分析情報」 が提供されるアラートを受け取れる
●Insights ペイン レポートやビジュアルの分析情報 を詳しく確認する場合、Insights ペインから、さらに詳しい情報を得ることができる。
【Insights ペイン情報の種類 】
異常 予想とは異なるデータの急激なる変化(例:通常72°Fの温度が100°Fに急上昇) 傾向 時系列データにおけるパターン(例:売上が4月全体で増加) KPI 分析 設定した目標値に対する現状の評価(例:売上目標120万に対し現在100万)
●異常の分析情報 予期しない急上昇や急降下 を検出し、異常としてマークされる。Power BI は 異常と相関するデータの変動 を分析し、強い影響を持つ要因をリストアップします。
重大な異常 異常スコアが高く、通常の範囲から大きく逸脱 最近の異常 メジャー内で最新の異常 異常の要約 複数の異常をまとめて表示
〇傾向
データを平滑化・補間・サンプリング して傾向の統計的有意性を分析し、季節性や外れ値などのノイズを除去する。傾向が検出されると、Power BI は 傾向に影響を与えたカテゴリを特定 し、それぞれの 相対的な貢献度をランク付け する。【主要な 4 つの傾向】
長い傾向 最も長期間続くパターン 急こう配の傾向 最も急な増加または減少 最近の傾向 直近に発生した変化 傾向の反転 以前と逆方向の変化
〇KPI分析
Power BI は 予想より高い・低い値を持つカテゴリを特定 し、説明を提示する。
ターゲット付きKPI分析 設定された目標値に対する 現在の値の差異 を分析し、区分ごとに高低を判定。目標値との差異を Z スコアに基づきランク付け。 ターゲットなしKPI分析 値自体を評価し、他のセグメントと比較して高低を判定。値自体の Z スコア に基づきランク付け。
◇ セキュリティ要素
[情報を展開する]
●行レベルのセキュリティ (RLS) 特定のユーザー データアクセスを制限 できる。 フィルターでは行レベルでデータ アクセスが制限され、ロール内でフィルターを定義することができる。
Power Pages
Microsoft Dataverse に格納された同じ共有ビジネスデータを使用して、外部向け Web サイト ブラウザーやデバイスを問わず 、シームレスに動作する。
[公式:Power Pages ] [リソース詳細:Power Pages ]
・豊富でカスタマイズ可能なテンプレート、再考されたデザインスタジオによる流動的なビジュアルエクスペリエンス、独自のビジネス ニーズに合ったサイトを迅速に構築するための統合学習ハブが用意されている。
・PCI DSS(Payment Card Industry Data Security Standard)準拠の支払い処理をサポート しており、StripeやPayPalなどの支払いゲートウェイと連携することで、安全な決済を実現できる。
・Power Pages サイトにはフォームを含めることができる。外部ユーザーは、これらのフォームを使用して Dataverse データにアクセスし、Dataverse テーブル内の行を作成、表示、編集できる。
主要機能 ・カスタマイズ可能なテンプレート で簡単にサイト作成技術基盤 ブートストラップ に基づく設計で、モバイル対応・レスポンシブデザイン を実現。異なるデバイス向け に 個別のサイトを構築する必要がなく、最適なユーザーエクスペリエンスを提供。
◇ コンポーネント
[情報を展開する]
フォーム Dataverseから1つのレコード(顧客情報や注文情報など)を表示、編集するためのコンポーネント。フォームを使うことで、データの詳細な情報を表示したり、ユーザーがそのデータを編集できるようにします。 リスト Dataverseから複数のレコードを一度に表示するためのコンポーネント。リストを使用すると、複数のエントリを一目で確認でき、詳細な操作(フィルタリング、ソートなど)も可能。
◇ サイトテンプレート
[情報を展開する]
ウェブサイトを作成する際の基盤となるテンプレート。これにより、開発者やデザイナーは時間と労力を大幅に節約でき、また一貫したデザインと機能を維持することができる。
【サイトテンプレート】
空白のページ 特定の事前設定されたレイアウトや機能がなく、すべての要素をゼロから作成する場合に使用。自由度が高く、任意の内容や機能を追加できますが、その分、設定や構築には高いスキルが要求される。 シナリオベース 特定の ビジネスシナリオ サイト設計 Power Pagesにおいてヘッダー・フッター・ナビゲーション・セクションレイアウトなど、一般的なウェブサイト構築に必要な基本構造やデザイン要素をあらかじめ提供。
【Dynamics 365 Power Pages サイト テンプレート】
パートナー 情報の共有、連絡先の管理、タスクの割り当てなど、パートナーとのコミュニケーションをスムーズにするための機能が備わってる。 コミュニティ ブログ投稿やフォーラム、Q&Aセクションなど、コミュニティとのインタラクションを重視したポータルを作成するのに適している。
※その他テンプレート
【テンプレートの初期構成】
ホームページ サイトの入口となるページで、全体の概要や主要なリンクを提供 検索結果ページ ユーザーがサイト内で情報を検索した際に、その結果を表示する お問い合わせページ ユーザーが質問やフィードバックを送信するためのフォーム
◇ デザインスタジオ
[情報を展開する]
Power Pages のサイト構築ツール 。ページの作成・編集、Dataverse への接続 、セキュリティ設定 を簡単に行える。各機能はワークスペースに分かれている。ページの作成、テーマやレイアウトのカスタマイズ、データフォームの構成、サイトのプレビュー、そして公開操作までを一貫して行える統合ツール 。
【主要な 4 つのワークスペース】
ページ Web ページの作成・編集・並べ替え スタイル設定 サイトのデザインや操作性をカスタマイズ データ Microsoft Dataverse のデータ管理・変更 設定 サイトの管理全般
◇ サイト作成手順
[情報を展開する]
手順1:Power Pagesに移動する 手順2:Microsoft Dataverse環境を選択する 手順3:テンプレートを選択する 手順4:デフォルトのサイト名とWebアドレスを入力する
サポートツール 上の製品に加えて、Power Platform で作成したソリューションを強化する他のツールがある。
Microsoft Copilot Studio 【AIコンパニオン】
チャットインターフェースを通じて人間の会話をシミュレート し、顧客の問題に対する 迅速な回答と調整 を提供する。ノーコード環境でコパイロット(AI ボット)を作成・編集 できるツール。トピックの作成・管理により、自然な会話フローを設計 できる。
[公式:Copilot ]
問題に関連するキーワードを認識 し、適切な回答を返す
顧客の質問に継続的に対応 し、解決策を最適化
※Copilot Studioで作成されたチャットボットは、以下プラットフォームにデプロイできる。Facebook / Microsoft Teams / Azure Bot Framework 」
●作成キャンバス(Authoring canvas)
◇ 主要機能
[情報を展開する]
トピック管理 ユーザーとボットの対話を制御するための基本的なユニット。トリガーフレーズや会話ノード を設定。 自然言語理解(NLP) AIがユーザーの意図を解析し、適切な回答を提供 エンティティ認識 電話番号や住所などの情報を特定。【例】学生エンティティ であれば、属性(学年、学部…)認証機能は有していない アクションの実行 Microsoft Power Automate を利用して業務プロセスを自動化 生成 AI 複雑な質問に対応する高度な会話エクスペリエンスを提供 公開機能 WebサイトやMicrosoft Teams、Facebookなど複数のチャネルで展開可能 認証機能 Microsoft Entra ID や OAuth2 プロバイダーを利用したサインイン対応
◇ トピック
[情報を展開する]
ユーザーとボットとの対話を制御するための基本的なユニット 。あいさつ、会話のエスカレート、終了 標準トピック
●フォールバックトピック
【トピックの構成要素】 ・トリガーフレーズ :ユーザーが入力する可能性のある言葉(例:「いつ営業していますか?」)・会話パス :入力に応じた応答ルートを定義する要素
【主な会話ノード】
◇ アプリの作成の簡素化
[情報を展開する]
●Copilot in Power Apps AIがユーザーの代わりにアプリを設計 する 。自然言語
新しいアプリケーションを作成する場合、AI アシスタントは Power Apps ホーム画面に表示される。収集して追跡する必要がある情報の種類を AI アシスタントに伝えると、アシスタントは Dataverse テーブルを生成し、そのテーブルを使用してキャンバスアプリ を作成する。
◇ クラウドフローデザイナー
[情報を展開する]
自分の自然言語を複数の会話ステップで使用して、ワークフローの合理化に役立つ自動化を作成できる。設計を簡略化し、以下の処理を実行する。
フローおよび製品に関する質問に答える
ユーザーが指定したシナリオ プロンプトに基づいてフローを作成する
ユーザーの代わりに接続を設定する
プロンプトに基づいて、必要なパラメーターをフロー内で適用する
アクションの更新や置換などの変更をフローに加える
【併用:Power Automate】
コパイロットの機能であるクラウド フロー デザイナーを使用すると、Power Automate フローの構築を簡単に始めることができる。
コネクタ 【パイプライン】
クラウドのアプリ、データ、およびデバイスに接続し、データソースと Power Platform の間
[公式:コネクタ ] [リソース詳細:コネクタ ]
※Power Platform 900 以上のコネクタ を備えているSalesforce、Office 365、Twitter、Dropbox、Google サービスなど
【データコネクタは Power Platform 全体で使用】
【キャンバスアプリ のコネクタ】
アクション コネクタが提供する機能の一つで、外部サービスやデータソースに対して特定の操作を実行するために使用される。 テーブル コネクタが提供する機能の一つで、データソース内の特定のテーブルにアクセスし、そのデータを表示・更新できるようにする。
◇ 構成要素
[情報を展開する]
トリガー Power Automate でのみ使用されワークフローをいつ実行するかを指定するには、必ずトリガーを作成する必要がある 。アクション Power Automate および Power Apps で使用される 。アクションはユーザーまたはトリガーから要求され 、データソースとの対話を何らかの関数によって行うことができる。たとえば、アクションとしてワークフローまたはアプリにメールを送信したり、データ ソースに新しい行を書き込んだりすることができる。
【データソースとの対話処理】
◇ データソースのタイプ
[情報を展開する]
表形式 構造化された表形式のデータ これらのテーブルを直接読み取って表示 関数ベース 関数を使用してデータ ソースと対話する。データのテーブルを返すために使用できるが、メールの送信、アクセス許可の更新、またはカレンダー イベントの作成など、より広範囲のアクションを提供する。
◇ コネクタの種類
[情報を展開する]
事前構築済みコネクタ Power Platform(Power AppsやPower Automateなど)を使って、Microsoft 365、SharePoint、Dynamics 365など 、一般的なアプリケーションやデータソースに接続するため に使う。特別なカスタマイズや開発が不要で、すぐに使えるもの。プレミアコネクタ 使用するには、アプリとユーザーの追加のライセンスの取得が必要。また、適切なスタンドアロンプランを利用している必要がある。プレミアムコネクタの主な利点は、多数のサービスに接続できること。大部分のプレミアムコネクタは、Salesforce、DocuSign、Survey Monkey、Amazon などの外部アプリケーションに対応している。プレミアムコネクタは、プレミアムスタンプで識別できる。 カスタムコネクタ 標準のコネクタが提供されていない 独自の API やサービス と接続するために使う。開発者がAPIエンドポイントを指定し、認証やコールをカスタマイズして、独自のコネクタを作成する必要がある。特定のビジネスシステムや、サードパーティ製のソリューションに接続する際に役立つ。Power Apps 、Power Automate や Azure Logic Apps などのさまざまなプラットフォームで使用できる
◇ コンポーネント
[情報を展開する]
各コネクタは、アクション トリガー
●アクション
●トリガー
【トリガーの種類】
ポーリング トリガー 指定された頻度でサービスを呼び出して、新しいデータをチェックする。新しいデータが利用可能になると、データを入力としてワークフロー インスタンスを新規に実行。 プッシュトリガー イベントの発生を待機する。このイベントが発生すると、ワークフロー インスタンスが新たに実行される。プッシュ タイプのトリガーのサポートは、今後のリリースで追加される。
[引用元サイト ]
AI Builder 【AI機能の追加】
ユーザーや開発者は、作成および使用するワークフローや Power Apps に AI 機能を追加 ワークフローやアプリにインテリジェンスを容易に追加
Microsoft Power Platform の AI 機能 で、ビジネスプロセスの最適化と自動化 Power Apps や Power Automate と連携し、データからインサイトを得ることが可能。
・画像の認識や形状の検出、テキストの読み取りなどの機能が含まれている
※対応可能なユースケースについて
【主な特長】
コーディング不要 で AI を活用可能カスタム AI モデル を作成し、業務に合わせて調整事前構築済み AI モデル を利用し、一般的なビジネス課題を解決
◇ AI Builder モデルの種類
[情報を展開する]
以下分類により、「企業は迅速な導入」か「高度なカスタマイズ」のどちらかを選択でき、最適な AI 活用が実現できる。
事前構築済みモデル データ収集やトレーニングなしで、アプリやフローにすぐに カスタムモデル 特定の ビジネス要件に合わせた AI ソリューション を構築でき、一から設計可能。
◇ モデルのライフサイクル
[情報を展開する]
下書き(Draft) :モデルの初期状態。データのインポートや構成が可能。トレーニング(一時的) :トレーニング処理が実行中。トレーニング済み(Trained) :トレーニングが完了し、モデルの精度をテスト可能。公開済み(Published) :他のPower Platform製品でモデルが利用可能な状態。非公開(一時的) :公開状態から戻す操作中。
◇ AIハブ
[情報を展開する]
AI 関連の機能にアクセスできる集中管理領域 で、以下の 3 つの主要エリアを提供する。・ドキュメント自動化 :ドキュメント処理を効率化する自動化ソリューション・ プロンプト・AI モデル :ビジネス要件に応じたカスタムモデルを定義
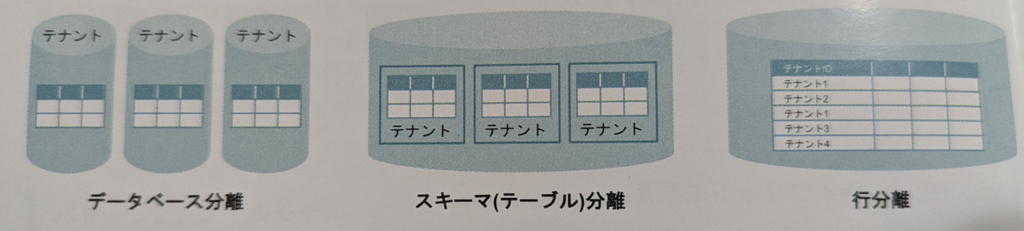
Dataverse 【拡張 データ管理】
拡張可能 データサービス およびアプリプラットフォームであり、ユーザーは複数のソースからのデータを組織で安全に格納および管理できる。データのセキュリティを保護 する、データを検証
[公式:Dataverse ]
●Dataverseコネクタ
●Dataverse のデータレイヤー 複雑な式なし で必要なビジネス成果を実現できる。
【設計】 中央リポジトリ として設計されている。セキュリティ、ロジック、データ、およびストレージが、一元的に管理される場所に組み込まれる。サーバー上でのスタンドアロン用途としては設計されていないため、アクセスと使用にはインターネット接続が必要
◇ 性能概要
[情報を展開する]
セキュリティ 【Microsoft Entra】 Microsoft Entra を使用して認証を行うことで、条件付きアクセスと多要素認証を可能にする。また、行レベルや列レベルでの承認をサポートしており、豊富な監査機能を提供する。ロジック 【データルール】 データレベルでビジネス ロジック簡単に適用できる。ユーザーがどのようにデータを操作するかに関係なく、同じルールが適用される。 これらのルールは、重複データ検出、ビジネス ルール、ワークフロー などに関連付けることができる。 データ 【検証・分析】 データを処理するための制御を提供しており、データの検出、モデル化、検証、レポートを行うことができる。 この制御により、データがどのように使用されるかに関係なく、データは適切に表示される。 ストレージ 【Azure Cloud】 Dataverse は、Azure 上でデータを管理するため、物理的な場所やデータ量に関する心配は不要。自動的にスケーリングし、必要なリソースを確保する。「インスタンスごとの上限」ではなく、組織全体で保有している Power Platformのストレージ容量(Dataverse 容量・ファイル容量・ログ容量など)に応じて柔軟に拡張可能。Microsoftのライセンス体系により、利用可能な容量は増減するが、特定の「インスタンスあたりの最大容量」といった固定上限はない。 統合 【多数接続方法】 さまざまな方法で接続してビジネスニーズをサポートする。API、Webhook、イベント、データ エクスポートにより、データの入出力の柔軟性が高まる。
【スケーラビリティ】
◇ サービス機能
[情報を展開する]
ビジネス(データ)ルール 【データルール】 データの入力に使用されるフォームに関係なく、ルールを適用したり、値を設定したり、データを検証したりするための、強力な手段。データの精度を高めたり、アプリケーション開発を簡素化したり、エンドユーザーに表示されるフォームを合理化したりする場合にも効果的。 データフロー 【データ処理プロセス】 Dataverse 環境、Power BI ワークスペース、または組織の Azure Data Lake Storage アカウントに対して、データの取り込み、変換、読み込みを行う。(Power Query を使用して作成される。)トリガー して実行できる。ストレージに保存 され、他のサービスも操作することができる。 Common Data Model 【データ形式の統一】 データを構造化して、ビジネスアプリケーションに統合し、ユーザーの使いやすさと一貫性を確保する相互運用ができる 。
◇ 構成リソース
[情報を展開する]
テーブル Dataverse のデータはテーブルに格納される。テーブルは一連の行と列。テーブルの各列には、名前、場所、年齢、日付、給与など、特定のタイプのデータが格納される。 インスタンス 取引先企業、取引先担当者、活動など、一般的なビジネスシナリオをカバーする標準テーブル の基本セット ソリューションの構築を始めるために必要な時間を節約 することができる。また、組織の固有のニーズに合わせてカスタム テーブルを作成して、データを入力することもできる。 ライセンス ライセンスされたすべてのユーザー間でプールされるため、作成したソリューションごとに、必要に応じてストレージを割り当てることができる。標準ライセンスで提供される容量よりも多くのストレージが必要な場合は、追加のストレージを購入できる。
【テーブルの種類】
標準 Microsoft Dataverseに含まれる既成のテーブルで、アカウント、部署、連絡先、タスク、ユーザーなどが含まれている。標準テーブルのほとんどはカスタマイズできる。 アクティビティ 予定、タスク、電子メール、電話など、アクティビティベースのデータを管理するための特別なテーブル 仮想 Dataverse外の外部ソースからデータを取得するためのテーブル エラスティック 数千万行を超える大規模なデータセットを格納するためのテーブル カスタム カスタム テーブルは、管理されていないソリューションからインポートされた管理されていないテーブル、または Dataverse 環境で直接作成された新しいテーブル。
◇ アクセスセキュリティ
[情報を展開する]
【セキュリティモデル】
セキュリティモデル 説明 適用対象 ロールベースのセキュリティ ユーザーやチームにセキュリティロールを割り当てて、操作権限(CRUDなど)を制御 テーブル・レコード単位 フィールドレベルのセキュリティ 特定の列 に対して 列(フィールド)単位 レコードレベルのセキュリティ レコードの所有者や共有設定に基づいてアクセスを制御 個別レコード単位 アプリケーションベースのセキュリティ 特定アプリに対するアクセス権を制御。アプリごとに専用ロールを設定可能。API 用ユーザーも管理可 アプリ・API アクセス単位 チームベースのセキュリティ チームにロールを割り当て、チームメンバーに権限を付与 チーム単位 部署(Business Unit)ベースのセキュリティ 組織階層に基づいてアクセス範囲を制限(部署、部署配下、組織全体など) 組織構造単位 アクセスチーム(Access Teams) 一時的なレコード共有に使われる柔軟なチーム構成 レコード単位の例外処理 Microsoft Entra ID(旧Azure AD)との連携 セキュリティグループと連携してユーザー管理やロール割り当てを効率化 ユーザー・グループ管理
◇ 明確なメリット
[情報を展開する]
管理が容易 メタデータとデータのどちらもクラウドに保存 保護が容易 ロールベースのセキュリティにより、組織内のさまざまなユーザーのテーブルへのアクセスを制御できる リッチメタデータ データ型およびリレーションシップは、Power Apps 内で直接利用される ロジックと検証 計算列、ビジネス ルール、ワークフロー、ビジネス プロセス フローを定義して、データの品質を確保する 生産性向上ツール 生産性を高め、データのアクセシビリティを確保するために、Microsoft Excel のアドインでテーブルを使用できる
◇ 連携サービス
【併用:コネクタ】
Power FX 【ローコード言語】
Microsoft Power Platform 全体で使用されるローコード言語。
◇ 記述形式
[情報を展開する]
Microsoft Excel で数式を作成する場合と同じような方法でオブジェクトをバインドする。
“希望価格” という名前のコントロールで式 If(IsBlank(“Property Name”.Text),false,true) を使用すると、”プロパティ名” という名前のコントロールにテキストが含まれているかどうかを評価する処理になる。
【イメージ】
Managed Environments
Power Platform 内で選択され、セキュリティで保護された分離環境です。 マネージド環境を使用すると、組織では、データやリソースに対する制御を維持しながら、アプリケーションを構築、テスト、展開できる。
Dynamics 365 について
Microsoftが提供する統合型の業務アプリケーション群。CRM(顧客関係管理)とERP(基幹業務管理)を一つのプラットフォームで動かせる。営業、マーケティング、サービス、財務、在庫管理、人事など、企業の日常業務をサポートするソリューションがまとめて使用できる。
・Microsoft製品との連携 :Teams、Power BI、Outlook、Excelとスムーズに連携Power Platformと統合可能 :Power Apps、Power Automate、Dataverseを活用して柔軟なカスタマイズが可能クラウドベース :どこからでも利用でき、セキュリティとアップデートも安心モジュール型構成 :必要な機能だけを選んで使えるので、導入や運用が効率的
【その他機能】
データ管理フレームワーク Dynamics 365アプリケーションに関連して使用されるフレームワークの一つ。データのエクスポートやインポートを簡単にする ためのツールセットである。この機能を使用するとデータパッケージを作成し、それを他の環境へインポートすることができる。 Lifecycle Services 認証処理の詳細なログやエラー のスタックトレースを取得 できる。これにより、ユーザーのDataverse上の登録状態、外部 ID プロバイダーとの接続状況、AADの設定ミスなど、根本原因の特定に必要な情報を得ることが可能。Dynamics 365 for Phones スマートフォンからDynamics 365のデータにアクセスできる専用のモバイルアプリ。
【Dynamics 365の主なアプリケーション】
アプリケーション名 主な用途 Sales 顧客管理・営業支援 Customer Service 問い合わせ対応・サポート管理 Marketing キャンペーン実施・リード育成 Field Service 現場作業・メンテナンス管理 Finance 財務・会計・請求書処理 Supply Chain Management 在庫管理・物流・調達 Human Resources 人事管理・従業員情報の一元管理 Project Operations プロジェクト計画・コスト管理 Business Central 中小企業向けERP
その他用語 Azure AI サービス Microsoft が提供するAI(人工知能)のサービス群です。プログラミングの知識が少ない人でも容易にAIの機能を利用することができる。・ドキュメントをスキャンしてテキストデータを抽出し、分析 が可能・ユーザーの入力した内容から感情分析 が可能 Azure Data Factory 大規模なデータの移動や変換を実行する Azure Machine Learning 機械学習モデルの開発・運用に特化 Azure PowerShell クラウドリソースの管理に使用されるツール Microsoft Entra Connect オンプレミスのActive DirectoryをMicrosoft Entra ID(旧:Azure AD)と同期するツール Power Query Dataverseへの取り込み処理の中で使用でき、フィルター・列の分割・型変換など柔軟なデータクレンジング(不整合修正)機能を提供。Excel や Power BI など多くの Microsoft 製品に搭載されているデータ接続/準備機能。●Power Query エディター データの整形・変換 データを準備 できる。複数の列を結合して1つの列にまとめることが簡単にするようなこともできる。
個人的苦手まとめ フォールバックトピック ユーザーの入力をチャットボットが理解できない場合に適切な応答を補完する。 トピック ユーザーの質問に対する会話の流れを設計する。システムには あいさつ、会話のエスカレート、終了 標準トピック データゲートウェイ(PowerApp) クラウドではないデータソースのサービス ギャラリー / フォーム(PowerApp) ギャラリーで一覧表示、フォームで一行分のデータを詳細編集 エンティティ(PowerApp) 電話番号や住所などの情報を特定。【例】学生エンティティ であれば、属性(学年、学部…) 感情分析 感情分析=Azure AI サービス PowerQuery フィルター・列の分割・型変換。データの整形・変換 RLS制御(Power BI) 特定のユーザー データアクセスを制限 できる。 フィルターでは行レベルでデータ アクセスが制限され、ロール内でフィルターを定義することができる。
Microsoft Learn 確認問題 ・[Microsoft Dataverse について説明する]
・[Microsoft Power Apps の基本機能を特定する]
・[ Microsoft Power Apps の機能を実演する ]
・[Microsoft Power Automate のコンポーネントを特定する]
・[Microsoft Power Automate の機能を実演する]
・[Microsoft Power Pages の機能について説明する]
・[Microsoft Power Pages サイトを作成する]
・[Microsoft Power Platform を使用してビジネス ソリューションを拡張することのビジネス バリューについて説明する]
・[Microsoft Power Platform サービスのビジネス バリューについて説明する]
・[キャンバス アプリを構築する]
・[モデル駆動型アプリを構築する]
・[Microsoft Power Platform 環境を管理する]