| Category | Tutorial Title | 概要 |
| アカウントの管理 | Increase account service quotas with Service Quotas | Service Quotasを使用したクォータ緩和申請方法、現在までのリクエスト確認。 |
| ※入門 | Getting Started with the AWS Management Console | コンソールホーム、アカウント情報、AWS リージョンを切り替、コンソールホームでの操作方法 |
| Visualize data in Amazon RDS for SQL Server using Amazon QuickSight | ||
| Build a training dataset with Amazon SageMaker Ground Truth | ||
| Create business intelligence dashboards with Amazon QuickSight | ||
| Optimizing Amazon EMR clusters for cost and scale with EC2 Spot Instances and Amazon EMR | ||
タグ: AWS
Machine Learning

基礎知識
●RAG(Retrieval-Augmented Generation:検索拡張生成)
外部の知識データベースから情報を検索し、それを使って自然言語を生成する仕組み。
(わからないことは調べてから回答するAI)
①検索(Retrieval):ユーザーの質問に対して、外部のデータベースやドキュメントから関連情報を検索。
②生成(Generation):検索結果をもとに、AIが文脈に沿った回答を生成。
[メリット]
- 最新情報に対応:学習済みモデルでは扱えない新しい情報も検索で補える。
- ハルシネーション対策:信頼できる情報源を参照することで、誤った回答を減らせる。
- 企業独自の知識活用:社内文書やFAQなどを活用して、業務に特化した回答が可能。
●ハイパーパラメーター
機械学習モデルの学習プロセスや構造を制御するために、事前に設定するパラメータ。人間が設計段階で決める設定値。
(モデルが自動で学習する「パラメータ(重みやバイアス)」とは異なる)
[学習プロセス]
・学習率:重みの更新幅。大きすぎると発散、小さすぎると収束が遅い。機械学習における「学習率」は学習の安定性にどう影響するかを意味する。学習率を適切に下げることで損失の振動を抑え、学習を安定させることができる。
- 学習率が高い場合の問題点
モデルの学習が大きく進みすぎるため、損失(モデルの誤り度合い)が安定せず、下がったかと思うとまた上がるという「振動」が発生します。これは、損失が最も小さくなる最適解の地点を通り過ぎてしまうことが原因。 - 学習率を下げることの効果
学習率を下げると、モデルはパラメータをより慎重に少しずつ調整するようになります。これにより、損失の振動が抑えられ、安定して最小値に向かって学習が進みます。その結果、モデルの性能も向上する。
・バッチサイズ:一度に学習するデータの数。
・エポック数:データセットを何回繰り返して学習するか。
[チューニング方法(アルゴリズム)]
| 手法名 | 探索方法 | 計算コスト | 特徴 | 向いている場面 |
|---|---|---|---|---|
| グリッド サーチ | 全組み合わせを網羅的に試す | 高い | 確実だが非効率。パラメータ数が多いと爆発的に試行数が増える | パラメータが少なく、計算資源に余裕があるとき |
| ランダム サーチ | パラメータ空間からランダムに抽出 | 中程度 | 意外と効率的。最適解に近い組み合わせに早く到達することもある | パラメータが多く、ざっくり良い結果を得たいとき |
| ベイズ 最適化 | 過去の試行結果から次の候補を予測 | 低~中 | 賢く探索。少ない試行回数で高精度に到達可能 | 評価に時間がかかる/試行回数が限られるとき |
| ハイパーバンド | ランダム探索+早期停止の組み合わせ | 低 | 効率的にリソース配分。性能が悪い試行は早期に打ち切る | 大規模な探索でリソース節約したいとき |
[ハイパーパラメータとパラメータの違い]
- パラメーター:モデルが学習によって自動的に決定する値(例:重みやバイアス)
- ハイパーパラメータ:学習前に人が設定する調整項目(例:学習率やエポック数)
◇学習モデル
データとラベルを使ってパターンを学習する。以下4種が存在する。
| モデル名 | 説明 | 代表的なアルゴリズム / モデル |
|---|---|---|
| 教師あり学習 例:売上予測、画像分類、スパム検出 | 正解となるラベル(教師データ)が付与されたデータセットを用いて学習する。入力データに対する正解を予測する。主に「分類」と「回帰」の2つのタスクに利用される。 | ・決定木 ・ロジスティック回帰 ・サポートベクターマシン ・ナイーブベイズ ・ランダムフォレスト |
| 教師なし学習 例:顧客セグメント分析、次元削減、異常検知 | 正解ラベルのないデータから、データに潜む構造やパターンを自律的に見つけ出す。データのクラスタリング(グループ分け)や次元削減(データの圧縮)などを行う。 | ・クラスタリング ・次元削減 ・自己符号化器 |
| 強化学習 例:ゲームAI、ロボット制御、広告最適化 | エージェントが環境の中で試行錯誤し、報酬を最大化するように学習する手法。環境と相互作用しながら最適な行動戦略を見つけます。 | |
| 深層学習 (ディープラーニング) | ニューラルネットワークを多層にしたもので、データから特徴量を自動的に学習。教師あり、教師なし、強化学習のいずれのフレームワークでも使用される。 | ・畳み込みニューラルネットワーク ⇒ 画像認識に特化 ・リカレントニューラルネットワーク ⇒ 時系列データ、自然言語処理に特化 ・トランスフォーマー ⇒ 自然言語処理、生成AIで広く利用 |
教師アリ
●分類
ラベル付きデータを使ってカテゴリを予測(例:スパム判定、画像分類)
| Accuracy(正解率) | 正解の予測数の割合を測定。 |
| Precision(適合率) | 正と予測されたもののうち、実際に正である割合を測定。 |
| Recall(再現率) | 実際に正であるもののうち、正と予測された割合を測定。 |
| F1-Score(F1スコア) | PrecisionとRecallの調和平均。バランス良く評価できる。 |
| ROC-AUC(ROC曲線下面積) | ROC曲線の下の面積を測定し、モデルの判別能力を評価。 |
| Logarithmic Loss(ロジ損失) | 予測確率の精度とクラス間の誤差を測定。 |
| Confusion Matrix(混同行列) | 各クラス間の予測結果を表形式で表示。 |
※混同行列(Confusion Matrix)
機械学習では、以下の4つの分類結果を混同行列で整理する。
| 実際のクラス | 予測が陽性 | 予測が陰性 |
|---|---|---|
| 陽性(True) | 真陽性(TP) | 偽陰性(FN) |
| 陰性(False) | 偽陽性(FP) | 真陰性(TN) |
分類問題(二値分類)では「偽陽性」と「偽陰性」はモデルの性能を評価するうえで非常に重要。
- 偽陽性(False Positive)
実際には「陰性(例:スパムではない)」なのに、モデルが「陽性(例:スパム)」と予測してしまうこと。
[例] 通常のメールをスパムと誤判定 → ユーザーが重要なメールを見逃す可能性あり。
[影響] 誤検出。不要なアラートや誤った処理が発生する。 - 偽陰性(False Negative)
実際には「陽性(例:スパム)」なのに、モデルが「陰性(例:通常メール)」と予測してしまうこと。
[例] スパムメールを通常メールと誤判定 → ユーザーが危険なリンクをクリックする可能性あり。
[影響] 見逃し。本来検出すべき対象を見逃す。
※偽陰性の予測コストが高い時、「再現率」を優先して向上させると改善の傾向にある
●回帰
数値の連続値を予測(例:売上予測、気温予測)
- 線形回帰分析(Linear Regression)
回帰線は直線であり、連続値を予測するタスク。入力変数(特徴量)に基づいて数値で表される目標変数(出力値)を推定する。評価には平均絶対誤差(MAE)や平均二乗誤差(MSE)などの指標が使われ、予測値と実際地の誤差を測定する。
・目的:連続値の予測(例:価格、点数、身長など)
・数式:出力 y は実数値(例:住宅価格が 42,000 USD) - 分類回帰分析(Logistic Regression)
回帰曲線はS字型(シグモイド)であり、カテゴリを予測するタスク。入力変数(特徴量)に基づいて、離散的なラベルやクラスを割り当てる。評価には正解率、F1スコア、ROC-AUCなどが使われ、予測モデルの正確さや判断能力を測定する。出力を閾値(例:0.5)で分類。コスト関数はクロスエントロピー(Log Loss)。
・目的:カテゴリ分類(例:Yes/No、陽性/陰性、スパム/非スパム)
・数式(シグモイド関数):出力 y は確率値(0〜1)
| Mean Absolute Error(平均絶対誤差) | 実測値と予測値の絶対差の平均。モデルがどれだけ正確に対象の価格を予測できているか、具体的な金額単位で直感的に把握できる。また、他の指標に比べて外れ値の影響を受けにくい。これは外れ値を含む可能性のあるデータセットにおいて、信頼性の高い評価ができる点で非常に適している。 |
| Mean Squared Error(平均二乗誤差) | 実測値と予測値の二乗誤差の平均。 |
| 二乗平均平方根誤差(RMSE) | MSEの平方根。 |
| R²(決定係数) | モデルがデータの分散をどれだけ説明するかを評価。 |
●時系列予測
過去のデータから未来を予測(例:株価、需要予測)
| Mean Absolute Percentage Error(MAPE、平均絶対百分率誤差) | 実測値に対する予測誤差の割合を測定。 |
| 平均重み付き分位点損失 (wQL) | P10、P50、P90 の分位点で精度を平均して予測を評価。値が小さいほど、モデルの精度が高くなる。 |
| 重み付き絶対誤差率 (WAPE) | 絶対目標値の合計で正規化された絶対誤差の合計で、予測値と観測値との全体的な偏差を測定。値が小さいほどモデルの精度が高いことを示し、WAPE = 0 はエラーのないモデル。 |
| 二乗平均平方根誤差 (RMSE) | 平均の二乗誤差の平方根。RMSE 値が小さいほどモデルの精度が高いことを示し、RMSE = 0 はエラーのないモデル。 |
| 平均絶対スケーリング誤差 (MASE) | 単純なベースライン予測法の非平均絶対誤差で正規化された予測の平均絶対誤差。値が小さいほどモデルの精度が高いことを示し、MASE < 1 はベースラインよりも精度が高いことを示し、MASE > 1 はベースラインよりも精度が引くことを示す。 |
| Root Mean Squared Logarithmic Error(RMSLE、平方平均対数二乗誤差) | 対数スケールで誤差を測定。 |
教師アリ+深層学習
●翻訳
入力文と対応する訳文を使って学習(例:Transformer、Seq2Seq)
| BLEU(BLEUスコア) | 生成された翻訳と参照翻訳のn-gram一致率評価。 |
| ROUGE(ROUGEスコア) | BLEUに単語と語形変化への対応を加えた指標。 |
| ROUGE(ROUGEスコア) | 生成テキストのリコール指標。 |
| BERTScore(BERTスコア) | 埋め込みモデルを用いて、生成文と参照文の意味的類似度を評価。 |
| Perplexity(困惑度) | 生成された文の予測精度を評価。 |
●画像認識
CNNなどを使って画像からラベルを予測(例:顔認識)
| Intersection over Union(IoU、交差面積比) | 検出領域と、予測領域と実際の領域の重複率を評価。 |
| Mean Average Precision(mAP、平均適合率) | 複数クラスの検出タスクでの精度を評価。 |
教師アリ+生成モデル
●生成(自然言語生成など)
GAN、VAE、拡散モデルなどで新しいデータを生成
| BLEU(BLEUスコア) | 翻訳同様、生成されたテキストの品質を評価。 |
| ROUGE(ROUGEスコア) | 翻訳同様、生成テキストの品質を評価。 |
| BERTScore(BERTスコア) | 翻訳同様、生成テキストの品質を評価。 |
教師ナシ
●クラスタリング
ラベルなしデータをグループ化(例:顧客セグメント分析)
| Silhouette Score(シルエットスコア) | クラスタリングの品質を評価、クラスタ間の距離とクラスタ内の密集性を考慮。 |
| Davies-Bouldin Index(デイビス・ボルダン指数) | クラスタリングの分離度と緊密さを評価。 |
| Adjusted Rand Index(調整ランド指数) | クラスタリング結果と実際のラベル間の一致度を評価。 |
強化学習
教師アリ+教師ナシ+強化学習
●推薦システム
協調フィルタリングや強化学習を組み合わせることが多い。
| Mean Reciprocal Rank(MRR、平均逆順位) | 正解の候補が結果リストでどれだけ上位にあるかを評価。 |
| Normalized Discounted Cumulative Gain(NDCG、正規化割引累積利得) | 関連度に基づいて推薦結果の品質を評価。 |
| Hit Rate(ヒット率) | 推薦リストに正解が含まれるかを測定。 |
●ドリフト
※別称:「モデルドリフト」、「モデルの陳腐化」
機械学習において、何らかの「予期せぬ変化」が原因で、モデルの予測性能が時間経過とともに劣化していく現象を指す。
| コンセプトドリフト | 入力データ(特徴量)と正解ラベル(目的変数)との関係性自体が、モデルを訓練した時から変化してしまうことを意味する。このドリフトが起こると、モデルは新しいデータのパターンを正確に予測できなくなり、「F1スコア」のような品質評価指標が低下する。「何(入力)から何を(出力)予測するかのルール自体が変わってしまう」こと。 |
| データ ドリフト | モデルを訓練した時の入力データの統計的な分布と、実際にモデルが使用される本番環境での入力データの統計的な分布がズレてしまうことを指します。「特徴量ドリフト」や「共変量シフト」とも呼ばれる。「入力されるデータの傾向が変わってしまう」こと。 |
●特微量エンジニアリング
| ※特微量とは… モデルにとって意味のあるデータの属性(列),モデルの予測精度に大きく影響するため、非常に重要な要素。 [例] 年齢、性別、購入履歴、Webサイトの滞在時間など |
機械学習モデルの性能を向上させるために、入力データ(特徴量)を加工・変換・選択するプロセスのこと。
・高性能なモデルでも、入力データが悪ければ精度は上がらない
・特徴量エンジニアリングによって、モデルの学習効率や予測精度が大幅に向上する
・特にKaggleなどのデータ分析コンペでは、最終順位を左右する要因になることも多い
[特徴量の学習プロセス]
| プロセス | 内容 |
|---|---|
| データ理解と探索 (EDA) | ・データの構造・分布・欠損・外れ値を把握 ・目的変数との関係性を可視化(ヒートマップ、散布図など) |
| 特徴量の作成 (Feature Creation) | 生データから新しい特徴量を生成 ・例: 年と月→年月 ・売上 = 単価 × 数量 |
| 特徴量の変換 (Feature Transformation) | ・スケーリング(標準化・正規化) ・対数変換、ビニング、ラベルエンコーディングなど |
| 特徴量の選択 (Feature Selection) | ・相関係数、情報利得、Lassoなどで重要な特徴量を選定 ・不要な特徴量を除去して過学習を防止 |
| モデル学習 (Model Training) | ・選定した特徴量を使ってモデルを構築 ・学習アルゴリズムに応じて特徴量の影響が変化 |
| モデル評価と特徴量の再設計 | ・精度・再現率・F1スコアなどで評価 ・特徴量の改善点を洗い出し、再設計 |
| 本番環境への導入とモニタリング | ・特徴量の生成ロジックをパイプライン化 ・データの変化に応じて特徴量を更新 |
[手法一覧]
| 欠損値処理 | ・平均・中央値補完:df.fillna(df.mean()) ・KNN補完:近傍データから推定 ・欠損フラグ追加:欠損の有無を新たな特徴量に |
| カテゴリ変数の変換 | ・ワンホットエンコーディング:カテゴリを0/1のベクトルに変換。機械学習を使う際の前処理の1つ。 たとえば、 “性別” という特徴量は、男 / 女の2種類の値をもつ。これをカテゴリ変数と呼ぶ。しかし値が文字になっているため、そのままだと機械学習の学習器に入れることができないため、”オリジナルの特徴量”_”値” で新しくヘッダを作り、値を 1 or 0 で表現することで、機械学習の学習器に入れることが可能となる。この新しく 1 or 0 で表現する方法を、one-hot エンコーディングという。 ・ラベルエンコーディング:カテゴリを整数に変換 ・ターゲットエンコーディング:目的変数の平均でカテゴリを数値化 |
| 数値変数の変換 | ・標準化(Zスコア):平均0・分散1に変換 ・正規化(Min-Max):0〜1の範囲にスケーリング ・対数変換: np.log1p(x)でスケール圧縮 |
| 外れ値処理 | ・IQR法:四分位範囲で検出 ・Zスコア法:標準偏差から逸脱を検出 ・外れ値フラグ化:外れ値かどうかを特徴量に |
| 時系列データの特徴量化 | ・ラグ特徴量:過去の値を現在の特徴に ・移動平均・差分:トレンドや変化量を抽出 ・曜日・月・時間帯:周期性の抽出 |
| テキストデータの処理 | ・Bag-of-Words / TF-IDF:単語頻度ベース ・Word2Vec / BERT:意味ベースの埋め込み ・文字数・単語数・記号数:構造的特徴量 |
| 特徴量の組み合わせ・生成 | ・交互作用項:例:売上 × 広告費・合成特徴量:例: 年と月→年月・条件付き特徴量:例: 雨の日の売上 |
| 次元削減・選択 | ・PCA(主成分分析) ・Lasso / Ridgeによる選択 ・相関係数・情報量による選択 |
●Min-Max正規化
データ全体を最小値0~最大値1の範囲に変換する方法。機械学習では、学習時と予測時でデータのスケールを揃えることが非常に重要であり、そのためにMin-Max正規化などの手法が一貫して適用される必要がある。
・正規化の目的: データのスケール(単位)を扱いやすいものに整えること。
・一貫性の重要性: モデルの予測精度を保つため、学習データと本番(予測)データで同じ方法・同じ統計値(最小値と最大値)を使って正規化する必要がある。
※Glue DataBrewの活用: このツールを使うと、学習データから計算した最小値・最大値の統計情報を保存し、本番データにも再利用できるため、一貫した前処理が保証され、データスキュー(データの偏り)を防ぐことができる。
◇過学習の防止方法
早期停止
学習が十分に進み、それ以上やると逆に性能が落ちそうになる一番良いタイミングで、賢くトレーニングをストップさせる手法。トレーニングを進めながら、モデルの性能を別途用意した「検証データセット」で常に監視します。そして、検証データセットに対する性能が向上しなくなった、あるいは悪化し始めた時点で、トレーニングを自動的に終了させる。
[メリット]
- 過学習の防止: モデルの性能が最大化された最適なタイミングで学習を止められる。
- 時間とコストの節約: 無駄なトレーニングを続けることを防ぎ、計算時間を短縮できる。
ドロップアウト
モデルのトレーニング中に、各層のニューロン(ノード)を一定の確率でランダムに無効化(一時的に無視)しながら学習を進める手法。この処理により、モデルが特定のニューロンや特徴の組み合わせに過度に依存することを防ぐ。
ネットワークは、より頑健で冗長性の高い表現を学習するようになり、未知のデータに対する予測性能である「汎化性能」が向上する。過学習を防ぐための効果的な「正則化」の手法として広く利用されている。
◇推論(予測)
学習済みの機械学習モデルに新しいデータを入力し、予測結果を得るプロセス。「学習」はデータから知識やパターンを学び、「推論」は学習済みの知識を使って新しいデータに予測や判断を行うプロセス。学習はモデルを「作る」段階、推論は作ったモデルを「使う」段階と考えることができる。
以下、推論処理の方式の種類。
[サポートされている出力形式]
application/json , application/x-recordio-protobuf , text/csv
| モデルタイプ | 出力内容 | 説明 |
|---|---|---|
回帰モデル (regressor) | score | 数値的な予測値(例:価格、温度など) |
| 分類モデル ( binary_classifier, multiclass_classifier) | score, predicted_la | scoreは予測の確信度、predicted_labelは予測されたクラス(例:スパム or 非スパム) |
| 推論方式 | 特徴 | 主な用途 |
|---|---|---|
| 同期推論 | 入力→即座に出力を待つ ⇒小規模モデル、リアルタイム応答が必要な場面 リクエストに対して即座にレスポンスを返す。リアルタイム性が高いが、待機時間が発生しやすい。 | チャットボット、音声認識、リアルタイム制御 |
| 非同期推論 | 入力→処理中に他の作業→後で出力を受け取る ⇒大規模モデル(GPT、BERT、画像生成モデルなど) | 画像生成、長時間推論、バッチ処理 |
| サーバーレス推論 | ・インフラの管理(サーバーの選択、設定、スケーリングなど)不要で機械モデルをデプロイ。 ・トラフィックの量に応じて、必要なコンピューティングリソースを自動で起動・停止。 ※CPUバースト用途に利用されることが多い ・ MaxConcurrency(同時実行リクエスト数)を1に設定することで、同時リクエスト数を制限できる。使用用途:予測する頻度が低い、トラフィックが断続的・予測不能なユースケースに最適。 コスト:従量課金制。リクエストがない時はリソースをゼロまでスケールダウン。(イベント駆動) | API連携、イベントベース処理、軽量推論 |
| バッチ推論 | 複数の入力をまとめて一括処理。効率的だがリアルタイム性は低い。 | レコメンド、ログ解析、定期処理 |
| ストリーム推論 | データストリームに対して継続的に推論。低レイテンシ処理に強い。 | IoT、センサーデータ、金融取引監視 |
| オンデバイス推論 | モバイルやエッジデバイス上で推論。通信不要で高速。 | スマホアプリ、ロボット、AR/VR |
●XG Boost(eXtreme Gradient Boosting)
勾配ブースティングを効率的に実装した オープンソースの機械学習アルゴリズム 。「弱いモデル(主に決定木)」を多数組み合わせて「強い予測モデル」を作る アンサンブル学習手法 の一種。
※簡単なイメージ
1本の決定木は「弱い予測器」だが、たくさんの木を「順番に」「誤差を修正しながら」作り足していくことで、精度の高い「強い予測器」を構築する。
| ディシジョンツリー (決定木) | データを段階的に分割し、分類や予測を行うシンプルなアルゴリズム。 ・ max_depth は決定木の深さを制御するパラメータ。・値が大きいとモデルが複雑になり過学習のリスクが高まる。 ・値を小さくすると複雑さが抑えられ、過学習を防止できる。 ・適切な max_depth を選ぶためにはクロスバリデーションが有効。・適切に制御することでモデルの汎化性能(未知データへの予測精度)が向上する。 |
| ※補足 | ・決定木の深さ(max depth):木の複雑さを制御。 ・隠れ層の数とユニット数(neural network):モデルの表現力に影響。 ・正則化係数(L1/L2):過学習を防ぐためのペナルティ。 |
[特徴]
| 高い精度 | 多くの機械学習コンペティション(Kaggleなど)で優勝に使われるほど精度が高い。 |
| 高速処理 | 並列処理やメモリ効率を工夫しており、大規模データでも学習が速い。 |
| 柔軟性 | 回帰、分類(二値・多クラス)、ランキング問題など幅広いタスクに対応。 |
| 過学習への対策 | max_depth や subsample など多数のハイパーパラメータでモデルの複雑さを制御できる。 |
| アルゴリズム | ・弱いモデルを組み合わせて正確な予測を行うアンサンブル学習手法。 ・多様なデータ型や分布、関係に対応可能で、ハイパーパラメータの微調整もしやすい。 |
[XGBoost ハイパーパラメータ分類表(完全版)]
| 分類 | パラメータ | 説明 |
|---|---|---|
| ツリーベースモデル用 (gbtree / dart) | max_depth | 木の最大深さ |
min_child_weight | 子ノードに必要な最小サンプル重み | |
gamma | 分割に必要な損失減少量(大きいほど単純な木になる) | |
subsample | 学習に使うデータの割合 | |
colsample_bytree | 各木の構築に使う特徴量の割合 | |
colsample_bylevel | 各階層で使う特徴量の割合 | |
colsample_bynode | 各ノード分割で使う特徴量の割合 | |
| ブースティング全般 | learning_rate(eta) | 各木の寄与度(学習率) |
n_estimators | 作成する木(モデル)の数 | |
booster | モデル種類(gbtree, gblinear, dart) | |
lambda(reg_lambda) | L2 正則化項 | |
alpha(reg_alpha) | L1 正則化項 | |
scale_pos_weight | クラス不均衡データへの重み付け | |
| 学習タスク | objective | 学習タスク(例: 回帰、分類、多クラス分類) |
eval_metric | 評価指標(例: rmse, logloss, auc) | |
seed | 乱数シード | |
| DART 特有 | sample_type | サンプリング方式 |
normalize_type | 正規化方式 | |
rate_drop | 木を間引く割合 | |
skip_drop | ドロップをスキップする確率 | |
| 線形モデル用 (gblinear) | updater | 学習アルゴリズム(例: shotgun, coord_descent) |
feature_selector | 特徴選択手法(例: cyclic, shuffle, random, greedy, thrifty) | |
top_k | 特徴選択で利用する上位 k(greedy のとき有効) |
Sage Maker

機械学習の構築。すべての開発者とデータサイエンティストに機械学習モデルを迅速に構築、トレーニング、デプロイできる手段を提供。PyTorchなどの主要なNL(自然言語)フレームワークに対応した事前作成済みコンテナイメージを提供しており、ユーザーは自作のPythonスクリプトをそのまま実行できる。
| 項目 | リアルタイム推論 [リアルタイム] | サーバーレス推論 [リアルタイム] | 非同期推論 [マイクロバッチ] | バッチ変換 [バッチ] |
|---|---|---|---|---|
| リアルタイム | リアルタイム | マイクロバッチ | バッチ | |
| 特徴 | 常時稼働するエンドポイント。低レイテンシ・高スループット対応。 | インフラ管理不要。使用時のみ課金。 | 長時間処理や大きなペイロードに対応。 | 大量データを一括処理。非同期で実行。 |
| 実行モード | 同期 | 同期 | ハイブリッド(同期/非同期) | 非同期 |
| 予測レイテンシー | 秒以下 | 秒以下 | 数秒~数分 | 不定 |
| 実行頻度 | 可変 | 可変 | 可変 | 可変/固定 |
| 呼び出しモード | 連続ストリーム/APIコール | 連続ストリーム/APIコール | イベントベース | イベント/スケジュールベース |
| 推論データサイズ | 小(<6MB) | 小(<6MB) | 中(<1GB) | 大(>1GB) |
| ユースケース | リアルタイムで推論結果が必要なケース、例えば、商品レコメンドなど | たまにしか推論しないケース、例えばドキュメントからのデータの抽出や分析など | 中規模のデータに対して非同期で推論ケース。例えばコンピュータビジョン、物体検知など | 大規模のデータに対して非同期で推論するケース。例えば、NLPなどデータサイズや推論処理が長いケースなど |
[Sage Maker 非同期推論について]
ペイロードサイズが大きく (最大 1 GB)、処理時間が長い (最大 1 時間)、ほぼリアルタイムのレイテンシー要件があるリクエストを処理できる。推論リクエストが処理されるまでの間、受信リクエストを「非同期キュー」に保存し、完了後に結果を S3 バケットに保存することで、処理が完了するのを待つ必要がなくなる。処理するリクエストがない場合、インスタンスカウントをゼロに Auto Scaling することによりコストを節約できるため、エンドポイントがリクエストを処理している場合にのみ料金が発生します。
・スケーリングポリシーを設定することで、リソースの使用状況に応じた「Auto Scaling」が可能となる。
機能性
| スクリプト モード | オンプレミス環境で作成した既存のスクリプトを最小限の変更で実行できる。これにより、独自のドメイン知識を反映したモデルを迅速にAWS上へ移行でき、運用コストや学習の手間を最小限に抑えられる。 「スクリプトモード」とは、SageMakerで用意されたアルゴリズムやコンテナを使うのではなく、独自のコンテナやライブラリを利用して学習処理を記述する方法のことである。 |
| バッチ変換 | 大規模なデータセットに対する非同期推論を効率的に処理するためのサービスであり、ジョブのスケジュール管理とスケーラブルな推論をサポートしている。この仕組みにより、要求された非同期処理要件を満たすことができる。 |
| ライフサイクル設定(LCC) | SageMakerのノートブックインスタンスが作成または起動されるたびに、あらかじめ用意したシェルスクリプトを自動的に実行させる。すべてのノートブックインスタンスに対して一貫した設定(パッケージのインストール、セキュリティ設定など)を自動で適用でき、手動での作業や運用上の負担を大幅に削減できる。 |
| バリアント 機能 | 1つのエンドポイントに複数のモデルや構成を同時にデプロイして、柔軟な推論運用を可能にする仕組み。特にA/Bテストやモデル比較に非常に有効。 ・Production Variant(バリアント) エンドポイントにデプロイされるモデルの構成単位。モデル名、インスタンスタイプ、インスタンス数、トラフィック重みなどを定義する。 ・マルチバリアントエンドポイント 複数のバリアントを同時にホストするエンドポイント。トラフィックを分散して複数モデルを評価できる。 ・TargetVariant 推論リクエスト時に、特定のバリアントを明示的に指定するためのパラメータ。 |
| シャドウ テスト | ユーザーからのリクエストを、本番環境で稼働中の機械学習モデル(本番稼働用バリアント)と新しいモデル(シャドウバリアント)の両方に送信することでパフォーマンスを実際のトラフィックで評価するための機能。 ユーザーへの影響なし: ユーザーには本番稼働中モデルからのレスポンスのみが返されるため、ユーザー体験を損なわずテストが可能。 データ収集: 新しいモデルのレスポンスは、S3などの内部的な場所に保存される。保存されたデータを分析することで、本番環境のデータを使って新しいモデルのパフォーマンス(推論のレイテンシーや正確性など)を評価し、本番環境にデプロイしても問題ないかを確認。 |
| マネージドウォームプール | 起動時間の短縮: 一度使ったインフラをすぐに再利用できるように待機させておくことで、次からのジョブの開始を速くする機能。トレーニングジョブに必要なインフラストラクチャを事前に準備しておき、ジョブが完了した後もそのインフラを保持。 この機能はSageMakerによって完全に管理されるため、ユーザーがインフラのセットアップや管理について負担を感じる必要はない。 |
| 分散 トレーニング | 分散トレーニングで、インスタンス間の通信遅延(レイテンシー)を減らすためには、以下の2点によりトレーニング時間の短縮と通信コストの削減につながる。 ①インスタンスを同じ場所に配置する トレーニングに使うすべてのインスタンスを、同じVPCサブネットに配置することで、ネットワーク経路が短縮され、通信のオーバーヘッドが減る。 ②データとインスタンスを同じ場所に配置する トレーニング用のデータを、インスタンスが稼働している同じAWSリージョンおよびアベイラビリティーゾーンに保存。これにより、トレーニング中のデータ転送時間が最小限になり、ネットワーク効率が向上する。 |
[暗号化]
| 暗号化の対象 | トレーニングクラスター内のノード間の通信は暗号化が可能。 |
| 暗号化されない通信 (サービスプラットフォーム内部) | サービスコントロールプレーンとトレーニングジョブインスタンス(顧客データではない)間のコマンドとコントロールの通信。分散処理ジョブや分散トレーニングジョブのネットワーク間のノード間通信。バッチ処理のためのノード間通信。 |
エンドポイント
動作:エンドポイントにリクエストを送ると、モデルが推論を実行し、結果を返す。
目的:トレーニング済みモデルをホスティングし、リアルタイムまたは非同期で推論リクエストを受け付ける。
[エンドポイントの種類]
| エンドポイント種別 | 特徴 | ユースケース |
|---|---|---|
| リアルタイム推論エンドポイント | 常時稼働。低レイテンシで即時応答。 | Webアプリ、API連携、チャットボットなど |
| 非同期推論エンドポイント | 長時間処理や大きなペイロードに対応。SNS通知も可能。 | 画像生成、音声処理、大規模データ分析など |
| バッチ変換 (Batch Transform) | エンドポイント不要。一括処理に特化。 | オフライン予測、事前データ処理 |
| サーバーレス推論エンドポイント | インフラ管理不要。使用時のみ課金。 | トラフィックが断続的なアプリケーション |
| マルチモデルエンドポイント | 複数モデルを1つのエンドポイントで管理。 | モデル切り替えが頻繁なシステム |
| マルチコンテナエンドポイント | 異なるコンテナを同時ホスト可能。 | 複数フレームワークの混在処理 |
| 推論パイプラインエンドポイント | 前処理・推論・後処理を連結。 | 複雑な処理フローやデータ変換付き推論 |
| 推論コンポーネント (Inference Components) | 生成AI向けの新機能。リソース効率化。 | Llama 3 や Mixtral などの大規模モデル推論 |
非同期推論では、結果はS3に保存され、SNSで通知を受け取ることも可能。
●リアルタイム推論エンドポイント
・利用シーン:リアルタイム、インタラクティブ、低レイテンシーが求められる推論に最適。
・Auto Scaling 対応:リクエスト数や需要の変動に応じてインスタンス数を自動調整。
・最適化された応答:リクエストサイズ(1KB~3MB)に対応し、低レイテンシーで推論。
・マネージドサービス提供:高可用性を確保し、運用負担を軽減。
●マルチモデルエンドポイント
複数の機械学習モデルを単一のエンドポイントでホスティングできる機能。これにより、推論コストの削減と運用効率の向上が可能になる。
[特徴と利点]
| 単一エンドポイントで複数モデルを管理 | モデルごとに個別のエンドポイントを作成する必要がなくなる |
| コスト効率が高い | 使用頻度の低いモデルも同じインスタンスでホスティングできるため、リソースの無駄が減る |
| スケーラブルな設計 | モデル数が増えてもエンドポイントの数は変わらず、運用が簡素化される |
| CPU/GPU 両方に対応 | 高速な推論が必要なモデルには GPU を割り当て可能 |
●SageMaker 推論コンポーネント
機能: 推論コンポーネントを利用することで、1つのSageMakerエンドポイントに対して複数のモデルを分離してデプロイできます。
メリット: リアルタイム応答を必要とするユースケースに適しており、柔軟かつ高可用な推論環境を実現できる。
[スケーリングの柔軟性]
- モデルごとに異なるスケーリングポリシーを適用できます。
- 推論コンポーネントの
minReplicaCountを $1$ 以上に設定することでコールドスタートの発生を防ぎ、少なくとも1つのインスタンスを常に稼働させることが可能。 - エンドポイントに紐づくコンポーネントごとに Auto Scaling ポリシーを設定できるため、モデルの負荷に応じた拡張性が確保されます。
アルゴリズム
SageMakerの組み込みアルゴリズムは、扱うデータの種類や解決したい課題に応じて、以下のようなカテゴリに分けられている。
| 表形式データ (Tabular) | 売上予測や顧客の解約予測など、表形式のデータを扱うためのアルゴリズム。 ・XGBoost:非常に人気があり、高い予測性能を持つ勾配ブースティングアルゴリズム。 ・Linear Learner:線形回帰やロジスティック回帰に使用される。入力された高次元ベクトル x とラベル y のペアから、線形関数または線形しきい値関数を学習し、x を y の近似値にマッピングする。クラス不均衡を取り扱う。・LightGBM:XGBoostと同様に勾配ブースティングの一種で、高速に動作するのが特徴。 ・Factorization Machines:クリック率予測や推薦システムに適している。 |
| テキスト (Text) | 自然言語処理(NLP)に関連するタスクのためのアルゴリズム群。 ・BlazingText:Word2Vec(単語のベクトル化)やテキスト分類を高速に実行する。 ・Sequence-to-Sequence:機械翻訳や文章の要約などに使われる。 ・Latent Dirichlet Allocation (LDA):文章のトピックを抽出するのに用いられる。 ・Object2Vec:テキストだけでなく、様々なオブジェクトをベクトル化できる汎用的なアルゴリズム。 |
| コンピュータビジョン (Vision) | 画像や動画を扱うためのアルゴリズム。 ・Image Classification::画像をカテゴリに分類する。 ・Object Detection:画像内の物体の位置と種類を特定する。 ・Semantic Segmentation:画像のピクセル単位で、それが何であるかを分類する。 |
| 時系列 (Time-series) | 株価や気象データなど、時間とともに変化するデータを予測するためのアルゴリズム。 ・DeepAR Forecasting:複数の関連する時系列データを用いて、精度の高い予測を行う。 |
| 教師なし (Unsupervised) | 正解ラベルがないデータから、パターンや構造を見つけ出すためのアルゴリズム。 ・K-Means:データをいくつかのクラスター(グループ)に分割する。 ・Random Cut Forest (RCF):データの中から異常な値(異常検知)を見つけ出す。 ・Principal Component Analysis (PCA):データの特徴を要約し、次元を削減するために使われる。 |
| オブジェクト検出アルゴリズム | 画像内に存在する複数の物体(オブジェクト)の「種類」と、その具体的な「位置(座標)」を特定するアルゴリズムです。検出された各オブジェクトは、その位置を示す四角い囲み(バウンディングボックス)で表示されます。 単一のディープニューラルネットワークを使用した教師あり学習アルゴリズムです。 SSD(Single Shot MultiBox Detector) というフレームワークを採用しています。 ベースネットワークとしてVGGとResNetをサポートしています。 ImageNetデータセットで事前トレーニングされたモデルを利用することも可能です。 |
※target_precision の詳細
主に binary_classifier に使用する。分類モデルが指定した精度(Precision)を達成するようにFalse Positive を減らす方向に予測しきい値を調整する。
注意点:指定値が必ず達成されるわけではなく、Recallとのトレードオフが発生する可能性あり
メトリクス / パラメータ
[メトリクス]
| メトリクス | CloudWatch Namespace | 主用途 | 適用対象 | 備考 |
| ModelSetup Time | AWS/ SageMaker | サーバーレス & バッチ推論でコンテナ起動〜ロード完了に要した合計時間を計測 | 単一モデル/サーバーレスエンドポイント | 値が高いと cold-start が原因のレイテンシー増加と判断できる |
| ModelLoading WaitTime | AWS/ SageMaker | Multi-Model Endpoint で、同一コンテナが別モデルをロードし終えるまでリクエストが待機した時間を計測 | MME(複数モデル同居) 専用 | サーバーレス単一モデルでは発生せず、起動遅延とは無関係 |
| Model Monitor 品質メトリクス | AWS/ SageMaker | 入力分布・予測結果の品質ドリフトやバイアスを検出 | エンドポイント全般 | レイテンシーではなくデータ品質の監視目的。起動時間は出力されない |
[パラメータ]
・EnableInterContainerTrafficEncryption
分散トレーニングにおけるノード間通信をTLSで保護できる。
リソース
| リソース | 目的 | 主な特徴 | 制限 |
| AWS::SageMaker::Model | Amazon SageMaker でホストされる機械学習モデルを定義。 | 推論用のモデルアーティファクトやコンテナイメージへのリンクを提供。 | エンドポイントやその編成を管理しない。 |
| AWS::SageMaker::Endpoint | 機械学習モデルをホストして予測を提供するエンドポイントを作成。 | デプロイされたモデルを使用して予測を呼び出すためのエントリーポイントを提供。 | 基盤となるモデルを作成または管理できない。 |
| AWS::SageMaker::NotebookInstance | モデルの構築とテスト用のインタラクティブな開発環境を提供。 | モデル構築や実験用の Jupyter Notebook をサポート。 | 本番環境のモデルホスティングや提供には適していない。 |
| AWS::SageMaker::Pipeline | データ準備、トレーニング、デプロイなどの機械学習ワークフローを自動化。 | 機械学習ワークフローの一連のステップを定義。 | 推論用のモデルを直接ホスティングまたは提供しない。 |
サービス連携
[セルフサービスで安全なデータサイエンス]
Service Catalog、SageMaker、Key Management Service (KMS) を連携させることで、データサイエンティストが煩雑な設定に触れずに、安全なセルフサービス環境で機械学習を活用する方法が紹介されている。
- 出力先の Amazon S3 バケット も KMS キーで暗号化し、モデルの成果物の安全性を確保。
- AWS Service Catalog を使って、あらかじめ設定された KMS キー付きの製品を提供し、ノートブックインスタンスのストレージを暗号化。
- セキュリティチームやインフラチームが事前に設定した製品で、統制のとれた環境を実現。
- SageMaker のノートブックやトレーニングジョブ作成時に、KMS キー ID を指定して暗号化を適用。
つまり、AWS の複数サービスを活用することで、コストとセキュリティの両立を図りながら、柔軟かつ安全にデータサイエンスを展開できるようにしている
[参照サイト]
◆派生サービス機能
[情報を展開する]
Autopilot
機械学習の専門知識がなくても、データセットから機械学習モデルの構築、トレーニング、デプロイのプロセスを自動化する機能(AutoML)。データの分析・前処理から、モデルの選択、ハイパーパラメータの最適化、デプロイまでを自動で実行。
[実行する主なタスク]
- データ分析と前処理
- モデルの選択
- ハイパーパラメータの最適化
- モデルのトレーニングと評価
- モデルのデプロイ
主な機能と利点
| ワークフローの自動化 | データの前処理、特徴量エンジニアリング、モデルのトレーニング、チューニングといった一連のプロセスを自動で実行 |
| 工数の削減 | ユーザーは最小限のコード作成で、高品質な予測モデルを迅速に得る |
| パフォーマンス評価 | モデルの性能を評価し、レポートとして提供するため、開発の手間を大幅に削減 |
サービス連携
| SageMaker JumpStart | 専門知識が不要: JumpStartで土台となるモデルを選び、Autopilotでトレーニングやチューニングを自動化するため、データサイエンスの深い知識がないユーザーでも高性能なモデルを構築できます。 効率化とコスト削減: コーディングを最小限に抑え、ワークフロー全体を自動化することで、効率的かつ効果的なソリューションを実現します。 |
Batch Transform
大量のデータに対して一括で推論(予測)を行うための機能。リアルタイムではなく、事前に用意したデータをまとめて処理するのに向いている。
[特徴]
| バッチ処理向け | リアルタイム推論ではなく、事前に用意したデータを一括で処理。 |
| 入力形式 | CSV、JSON Lines、または画像ファイルなど。 |
| 出力形式 | 予測結果を S3 に保存。 |
| スケーラブル | 複数のインスタンスで並列処理が可能。 |
Canvas

プログラミング(コーディング)なしで、クリック操作だけで機械学習の予測モデルを構築できるツール。顧客がサービスを解約する可能性(カスタマーチャーン)の予測在庫の計画や価格の最適化テキストや画像の分類文書からの情報抽出など。
Apache Parquet形式
データを列ごとに保存する列指向のストレージ形式であり、大量のデータを効率的に圧縮・処理するために設計された、高性能なファイル形式。
[なぜParquet形式のサポートが重要なのか]
ビジネスユーザーでも下記により大規模なデータを、より高速かつ効率的に扱って、精度の高い機械学習モデルを自分で作れるようになった。
- 分析に必要な列のデータだけをピンポイントで読み込めるため、無駄なデータの読み込みがなくなり、処理が非常に高速。
- データ処理時間を最小限に抑えられる。特に大量のデータを扱う場合、この高速化の恩恵は非常に大きく、モデルのトレーニングなどが素早く完了する。
機械学習モデルの利用
SageMaker Canvas のユーザーが機械学習モデルを利用するための前提条件と、そのモデルが必ず 「SageMaker Model Registry」に登録されている必要がある。
- Canvas を Model Registry と統合することで、モデルのバージョン管理やアクセス制御が可能になる。これにより、Canvas ユーザーに共有されるモデルが整理され、他の SageMaker サービスとの連携もスムーズになる。
- SageMakerの外部でトレーニングしたモデルでも、Model Registryに登録すればCanvasユーザーがインポートして予測に利用できる。
※外部で開発されたモデルを利用するには、モデルアーティファクトが保存されている S3 バケットへのアクセスが必要。このアクセス権限が設定されていない場合、Canvas ユーザーはモデルアクセスにアクセスできず、モデルのロードやチューニング操作を実行できない。S3バケットのアクセス制限を設定する際は s3:Getobject 権限を含む適切なIAMポリシーを設定する必要がある。
Clarify
機械学習モデルの入力データおよび推論結果に潜むバイアスや精度低下の原因となるデータ内の傾向を評価・特定。これにより、ユーザー層毎の予測パフォーマンスのばらつきや不公平な結果の原因を分析し、改善するための具体的な洞察を得ることができる。
分析機能
機械学習モデルに対して以下の2つの観点から分析を行う。
| バイアス検出 (Bias Detection) | ・データセットやモデルに潜在するバイアス(性別・年齢・人種など)を検出 ・公平性の観点からモデルの健全性を評価 |
| 説明可能性(Explainability) | ・モデルの予測に対して、どの特徴量がどのように影響したか可視化 ・SHAP値(SHapley Additive exPlanations)を用いた詳細な分析 |
主な機能とオプション
| 機能カテゴリ | 機能名 | 説明 |
| バイアス分析 | Pre-training bias | 学習前のデータセットに潜むバイアスを検出 |
| Post-training bias | 学習後のモデル出力に潜むバイアスを検出 | |
| 説明可能分析 | SHAP値分析 | 各特徴量が予測に与えた影響を定量化 |
| グローバルSHAP | 全体的な特徴量の重要度を表示 | |
| ローカルSHAP | 個別予測に対する特徴量の影響を表示 | |
| レポート出力 | Bias Report | バイアスの統計と可視化 |
| Explainability Report | SHAP値に基づく特徴量の影響レポート | |
| 統合機能 | SageMaker Studio | GUIベースでClarifyジョブを作成・実行 |
| SageMaker Pipelines | MLOpsパイプラインに組み込み可能 |
Data Wrangler
機械学習(ML)で使うためのデータの準備から異常検出、特徴量エンジニアリングまでの一連のデータ準備プロセスを効率化し、迅速かつ正確に実行できるようになる。また結果の可視化を単一のツールで効率的に実行。特に、データの不均衡や特徴量間の相互依存性といった問題に、「組み込みの異常検出機能」や「可視化機能」を用いて迅速に対応。
主な機能
| データの統合(Import) | 複数の異なる場所にあるデータをインポートし、1つのデータフレームにまとめることができます。S3, Athena, Redshift, Snowflake, Databricksなど、多様なデータソースに接続してデータをインポートできます。 |
| データクレンジング | データの「お掃除」機能です。欠けている値の補充、重複データの削除、極端におかしい値(外れ値)の処理などができます。 |
| エンリッチメント(データ加工)変換 (Transform) | 既存のデータをもとに、新しいデータ項目(変数)を追加したり、データを変換したりできます。テキストや日付の処理、欠損値の埋め込み、カテゴリ別エンコーディングなど、300以上の組み込み変換機能を使用してデータセットをクリーンアップし、特徴量を作成できます。 |
| 簡単な操作とカスタマイズ性 | たくさんの「組み込みの変換機能」が用意されており、コーディングなしで直感的に操作できます。 さらに高度な処理が必要な場合は、PySparkやPython、pandasなどを使って独自のカスタム変換を追加することも可能です。 |
| 効率的な処理 データフロー (Data Flow) | 一度の操作で複数の列をまとめて削除するなど、効率的に作業を進められます。 ただし、「数値の処理」や「欠損値の処理」のように、1つの列に対してのみ適用できる機能もあります。GUIを使用して、さまざまなデータソースの結合や、データセットに適用する変換の定義など、一連のデータ準備手順(MLパイプライン)を構築できます。 |
| データインサイトの生成 (Generate Data Insights) | 「データ品質とインサイトレポート」により、データ品質を自動的に検証し、異常を検出します。 |
| 分析 (Analyze) | 散布図やヒストグラムなどの可視化ツールや、ターゲット漏洩分析などの機能を用いて、データ内の特徴や相関性を理解できます。 |
| エクスポート (Export) | 準備が完了したデータワークフローを、Amazon S3バケット、Amazon SageMaker Pipelines、Amazon SageMaker Feature Store、またはPythonスクリプトとしてエクスポートできます。 |
バランスデータ
データの不均衡を解決するための操作。少数派クラスをオーバーサンプリング(過剰に抽出)して、クラスの分布を均一にすることができます。GUIベースで直感的に操作できるため、高品質なデータを迅速に準備できます。
また、様々なデータソース(Amazon S3やオンプレミスのMySQLなど)と簡単に統合でき、トレーニング全体のパイプラインを一元管理できるため、エンジニアはモデルのトレーニングに集中できます。
| ランダムオーバーサンプリング | 少数カテゴリのサンプルをランダムに複製します。例えば、不正検出のケースで不正ケースが全体の10%しかない場合、このデータを8回複製して不均衡を是正します。 |
| ランダムアンダーサンプリング | 多数派カテゴリからサンプルをランダムに削除し、目的のサンプル割合を取得します。 |
| Synthetic Minority Oversampling Technique (SMOTE) | 過小評価されているカテゴリのサンプルを使用して、新しい合成マイノリティ(少数派)サンプルを補間します。 |
カテゴリ別エンコーディング
| ワンホットエンコーディング | 各カテゴリ値を「0」または「1」のバイナリ形式で表現します。例えば、「A」「B」「C」はそれぞれ [1,0,0] [0,1,0] [0,0,1] のように変換されます。 |
| ターゲットエンコーディング | カテゴリ変数を、目的変数の統計値(平均値など)に基づいて数値に変換します。カテゴリが多い場合や、カテゴリ間に順序性がある場合に有効です。 |
| ラベルエンコーディング | 各カテゴリに整数を割り当てます(例:A=1, B=2, C=3)。順序を持つカテゴリデータに適しています。 |
オプション
[基本的なデータ変換オプション]
| オプション名 | 説明 |
|---|---|
| FirstK | 指定した行数のデータを抽出(サンプリング) |
| Split | データを訓練・検証・テスト用に分割(ランダム・順序・層化) |
| Join | 複数のデータセットを結合(Inner, Left, Right, Full Outer) |
| Filter | 条件に基づいてデータを絞り込み(数値・文字列・日付・複合条件) |
| Drop Column | 不要なカラムを削除 |
| Rename Column | カラム名の変更 |
| Change Data Type | データ型の変換(文字列→数値など) |
| Corrupt image(ノイズ付与) | 画像データ(JPEG、PNGなど)に対して、破損や読み込みエラーを検出・修復するための前処理 |
| Impulse Noise | SageMaker Data Wrangler における「Impulse Noise」は、画像データの前処理ステップの一つで、突発的な画素異常(塩胡椒ノイズなど)を検出・除去する |
[特徴量エンジニアリングオプション]
| カテゴリ | オプション | 用途 |
|---|---|---|
| カテゴリ変数 | One-hot encoding, Label encoding | カテゴリ変数の数値化 |
| 数値変換 | Min-max scaling, Z-score normalization | 正規化処理 |
| テキスト処理 | TF-IDF, Word embeddings | テキストの特徴量化 |
| 時系列処理 | ラグ特徴量、日付分解 | 時系列データの抽出 |
| 欠損値処理 | 平均値補完、前方補完 | 欠損値の補完 |
[分析・可視化オプション]
| オプション名 | 説明 |
|---|---|
| Data Quality & Insights Report | 欠損値・外れ値・ターゲットリークの検出 |
| Quick Model | 簡易モデルによる予測力の確認 |
| Feature Summary | 各特徴量の予測力スコア表示 |
| ターゲット漏洩解析 | モデルに悪影響を与える特徴量の検出 |
[エクスポートオプション]
| エクスポート先 | 説明 |
|---|---|
| Amazon S3 | 変換済みデータの保存 |
| SageMaker Pipelines | モデル学習パイプラインへの統合 |
| Feature Store | 特徴量の一元管理 |
| Python Script | カスタムワークフロー用コード出力 |
Debugger
機械学習モデルのトレーニング中に発生する問題を自動で検知し、モデルの内部状態を可視化できるツール。必要に応じて、カスタムルールを定義してより細かい検証も可能。精度が上がらない原因調査やモデルの挙動をリアルタイムで監視したいときに有効
[対応フレームワーク]
TensorFlow , PyTorch , MXNet , XGBoost など
機能性
| モデル内部の 状態を記録 | 重み、勾配、各レイヤーの出力、lossなどをS3に保存できる。 |
| 自動問題検知 | 「勾配消失」や「lossが減らない」など、事前定義されたルール(またはカスタムルール)に基づいて問題を検出する。 |
| TensorBoard 連携 | TensorFlow以外のフレームワーク(PyTorchなど)でも、TensorBoard形式でログを出力して可視化できる。 |
| スクリプトの 変更不要 | SageMakerの対応コンテナを使えば、トレーニングスクリプトを変更せずにDebuggerを有効化できる。 |
●Tensor Board
TensorFlowに付属する可視化ツールで、以下のような情報をグラフィカルに表示できる。
・GPU/CPUの使用状況
・損失関数や精度などのスカラー値の推移
・特徴マップや畳み込みカーネルなどの画像データ
・各層の重み・バイアスのヒストグラム
・モデルの計算グラフ(順伝播・逆伝播の流れ)
・埋め込みベクトルの分布(例:Word2Vec)
・ハイパーパラメータの探索結果
Experiments
複数のハイパーパラメータやアルゴリズムを試す反復的なML開発プロセスに対して、MLモデルのトレーニングや評価における実験の記録・整理・比較を支援する。
[主な機能]
| エクスペリメントの作成 | プロジェクト単位で実験をグループ化。 |
| トライアルとトライアルコンポーネント | 各トレーニングジョブや評価ステップを個別に記録。 |
| 自動トラッキング | 入力データ、パラメータ、結果などを自動で記録。 |
| 可視化と比較 | SageMaker Studioで実験結果をグラフ表示し、パフォーマンスを比較。 |
| 再現性の確保 | 過去の実験履歴を保存し、モデルの再現性を担保。 |
Future Store
機械学習モデルのための特徴量を一元管理するためのフルマネージドサービス。特徴量(Feature)とは、MLモデルに入力する意味のあるデータのこと。Feature Storeはそれらを保存・共有・管理するための専用リポジトリ。
主な機能
| 特徴量グループの作成 | 特徴量を論理的にまとめた「Feature Group」を定義し、スキーマに基づいて管理。 |
| オンラインストア | リアルタイム予測向け。最新の特徴量を高速に取得可能。 |
| オフラインストア | バッチ学習や分析向け。履歴データを保持。 |
| Point-in-time Join | 特定の時点における特徴量を正確に結合する機能。学習と推論の整合性を保つのに重要。 |
| 特徴量の再利用と共有 | チームやプロジェクト間で特徴量を再利用できるため、重複作業を削減。 |
| トレーニング・推論のスキュー防止 | 学習時と推論時で異なる特徴量が使われることによる精度低下を防ぐ。 |
Future Group
機械学習モデルに使う特徴量を論理的にまとめたデータの集合体。特徴量グループは、MLモデルのトレーニングや推論に使う特徴量(Feature)をまとめたもの。1つのグループは、共通のスキーマ(列名とデータ型)を持つレコードの集合。Feature Storeに保存する際の基本単位であり、特徴量の作成・取得・共有・管理を行うための枠組み。
[構成要素]
| 特徴量定義 | 各特徴量の名前とデータ型(整数、文字列、浮動小数点など)を指定。 |
| イベントタイム | 各レコードに関連づけられる時刻情報。Point-in-time Joinなどで重要。 |
| ストレージタイプ | ・オンラインストア:リアルタイム推論向け。最新の特徴量を高速取得。 ・オフラインストア:バッチ学習や分析向け。履歴データを保存。 |
Ground Truth
ラベル付きデータセットを作成できる機械学習とともに、Amazon Mechanical Turk、任意のベンダー会社、または社内のプライベートワークフォースのいずれかのワーカーを使用できる。Ground Truth のラベル付きデータセット出力を使用して、独自のモデルをトレーニングできる。Amazon SageMaker AI モデルのトレーニングデータセットとして出力を使用することもできる。
ヒューマンインザループ(HITL)のラベリングタスクを支援するために設計されている。
JumpStart
様々な問題に対応できる、学習済みのオープンソースモデル。ユーザーはこれを基盤として、機械学習をすぐに始めることができる。デプロイ、微調整、評価までを一貫して行えるハブのような機能。これにより、ローコード・ノーコードの手法を容易に採用できる。
●事前トレーニング済のモデル
機械学習を容易に始めるための、幅広い問題に対応する「事前トレーニング済みのオープンソースモデル」を提供する。更新された「Studio エクスペリエンス」のJumpStartランディングページを通じて、一般的なモデルハブからこれらのモデルをデプロイ、微調整、評価することができる。
・提供されるモデルは、デプロイ前にトレーニングや調整(チューニング)が可能。
・一般的なユースケースのインフラをセットアップするための「ソリューションテンプレート」も提供される。
・SageMaker MLを使用した機械学習用の「実行可能なサンプルノートブック」も含まれる。
連携サービス
[Autopilotとの連携]
Autopilotと併用することで、モデルのトレーニングやチューニングが自動化され、データサイエンスや機械学習の専門知識がなくても高性能なモデルを構築することが可能
Market Place
機械学習モデルやアルゴリズムを簡単に導入・利用できるAWSのプラットフォーム。
| 事前構築済みのMLモデルや アルゴリズムを提供 | 開発者や企業は、すぐに使えるモデルやアルゴリズムを選んで導入できる。 |
| AWS Marketplaceと統合 | セキュリティ、ネットワーク、ストレージ、データベースなど、他のカテゴリのソフトウェアと同様に、ML関連の製品も一元管理できる。 |
| 柔軟なライセンスと価格設定 | サブスクリプション型や従量課金型など、用途に応じた価格体系が選べる。 |
| 簡単なデプロイと管理 | SageMaker Studioなどの環境から、数クリックでモデルをデプロイ可能。 |
| サードパーティ製品も多数掲載 | Hugging Face、DataRobot、Algorithmiaなど、外部ベンダーの製品も利用できる。 |
Model Registry
作成した様々なバージョンの機械学習モデルを、一元的なリポジトリ(保管場所)で整理・追跡・管理するためのサービス。モデルの登録、バージョンの管理、承認やデプロイといったMLモデルのライフサイクル全体を管理する中心的なハブ。AWS内外を問わずモデルの運用が非常に効率的になる。
主な機能
| 組織全体の標準化とセキュリティ向上 (プライベートリポジトリ) | ・モデル管理のカタログ(場所)一元化 「クロスアカウントリソースポリシー」機能を使うことで、組織内に新しいAWSアカウントが増えても保存場所を1つに統一できる。モデルの異なるバージョンを一貫して管理できる。 これまでは主にAWS内のサービス(ECR)に保存されたモデルが、AWS以外のプライベートなDockerリポジトリ(例: 企業内のサーバーなど)に保存されているMLモデルも登録・追跡できるようになった。 ・トレーニングデータ連携 S3に保存されたトレーニングデータと連携し、モデルの再トレーニングなどを行う際にセキュアなデータアクセスを保証する。 |
| 他のユーザーとのモデル共有 | 開発したMLモデルをこのサービスに登録することで、誰がいつどんなモデルを作ったのかを一覧で管理できる。複数のAWSアカウント間でモデル情報を効率的かつ安全に共有できる。 |
| メタデータの関連付け | SageMaker Studioと統合されており、UI上でモデルの状態やメタデータ(付随情報)を簡単に追跡できる。 |
基本的な構成
| Model Group | 「Model Group」という単位で関連するモデル(モデルパッケージ)を論理的に整理し、運用効率を向上 |
| モデル パッケージ | 個々のトレーニング済みモデルのこと。 |
| モデル バージョン | Model Groupに新しいモデルパッケージが追加されるたびに、「1, 2, 3…」と自動で割り振られるバージョン番号。 |
Model Monitor
機械学習モデルの予測精度やバイアス、入力データの品質が時間とともに劣化する「ドリフト」を検出するアラートを設定できる。モデルの再トレーニング、アップストリームシステムの監査、品質問題の修正などのアクションを実行できる。コーディングが不要な Model Monitor のビルド済みモニタリング機能を使用可能。
モニタリング機能
[主な機能]
| データ品質モニタリング | 入力データの分布や欠損値などの変化を検出 |
| モデル品質モニタリング | 精度や予測分布の変化を検出 |
| バイアスドリフト検出 | モデルの予測に偏りが生じていないかを監視 |
| Feature Attribution ドリフト | 特徴量の重要度が変化していないかを監視 |
[モニタリングの仕組み]
| データキャプチャ | 推論リクエストの入力と出力を S3 に保存。 |
| ベースライン作成 | トレーニングデータから統計情報と制約条件(constraints.json)を生成。 |
| 監視ジョブの設定 | スケジュールに従ってリアルタイムまたはバッチで監視。 |
| 異常検出と通知 | CloudWatch 経由で違反を検出し、アラートを発報。 |
ベースライン
モデルが常に最新のデータに適応し、適切な品質を維持するためには、定期的にデータから新しい「ベースライン」を作成し、評価の基準を最新に保つことが重要である。
データ品質の基準となるもので、データの統計情報やスキーマ(構造)を定義する。SageMaker Model Monitorは、このベースラインとリアルタイムデータを比較することで、データの異常やドリフト(時間経過によるデータの傾向の変化)を検出する。
| 新しいベースラインが必要な時 | モデルを更新した際など、新しいデータ分布が発生して既存のベースラインが現状と合わなくなった場合に、新しいベースラインを作成する必要がある。最新の本番データ(トレーニングデータ)を使って、統計情報とスキーマを抽出し、新しいベースラインを生成する。生成したベースラインをModel Monitorに設定し、今後のデータ品質の評価基準として使用していく。 |
| ベースライン作成の自動化 | Model Monitorには、CSVやJSON形式のデータから、データのドリフトなどを検出するためのベースラインを自動的に提案・作成する機能が組み込まれている。 |
ML Lineage Tracking
データ準備からモデルデプロイまで、MLワークフローの各ステップの情報を詳細に記録・追跡(トラッキング)する機能。モデルが「いつ、どのデータで、どのように作られたか」という系統(リネージ)を追跡できるため、監査やコンプライアンス確認に必要な「ガバナンス機能」を提供する。
Pipelines
データ準備、トレーニング、評価、モデルデプロイといった一連のMLワークフロー全体をエンドツーエンドで自動化するためのサービス。機械学習のワークフローを有向非巡回グラフ(DAG)として可視化・管理する機能。これにより、データサイエンティストはワークフロー全体を細かく制御できる。15TBを超えるような大規模データセットも効率的に処理できる。
コールバックステップ
ML の CI/CD パイプライン内で、外部のタスクやジョブをステップとして統合可能になった。コールバックステップが呼ばれるとタスクが開始され、外部からタスク完了を通知する仕組み(タスクトークン)が使える。コールバックステップは Glue ワークフローを起動し、進行状況を EventBridge 経由で監視。Glue ジョブが完了するまでパイプラインは停止し、完了後に次の処理へ進む。これにより、Glue ジョブの出力を効率的にモデル開発のデータ処理フェーズに利用できる。
例:Amazon EMR の Spark ジョブや AWS Glue の ETL ジョブをパイプラインの一部として実行できる。
サービス連携
〇EventBridgeとの連携
MLパイプラインの開始や監視を自動化し、プロセス全体を効率的かつエラーの少ない方法で運用できる。EventBridgeを利用して、SageMaker Pipelinesの実行をスケジュールしたり、特定のイベントをきっかけに自動で開始(トリガー)したりすることが可能。
Serverless Inference
サーバー管理不要でAWSがMLモデルのインフラ管理やスケーリングを自動で行う便利なサービス。「プロビジョニングされた同時実行」を設定すれば、アクセスが集中する時間を予測して事前準備を行い、遅延なく安定したパフォーマンスをコスト効率よく提供できる。あらかじめ指定した数の推論環境を「ウォームアップ」(事前準備・待機)させておくことで、コールドスタートを解消し、予測されるトラフィックに対して高いパフォーマンスとスケーラビリティを確保する。
※断続的な推論リクエストには向いている。常に高い負荷がかかるため起動の遅延が生じやすい。
Inference Recommender
機械学習モデルの推論に最適なインスタンスタイプや構成を自動で提案する機能。
主な特徴
| 最適なインスタンス選定を自動化 | 従来は複数のエンドポイントを手動でテストする必要がありましたが、Inference Recommender により モデルに最適なインスタンスや構成(数、メモリ、同時実行数など)を自動で評価・提案 できる。 |
| リアルタイム/サーバーレス推論に対応 | 推論エンドポイントのタイプ(リアルタイム or サーバーレス)に応じて、最適な設定を選定可能 |
| ベンチマークジョブによる性能評価 | SageMaker Studio や AWS SDK for Python(Boto3)を使って、推論負荷テストを実行し、パフォーマンスとリソース使用率のメトリクスを収集する。 |
| コスト効率の向上 | 過剰なリソースを避け、必要最小限の構成で高パフォーマンスを実現 できるため、運用コストの削減に貢献。 |
ジョブタイプ
| Default ジョブタイプ | 目的:モデルに対して基本的なベンチマークを実行し、最適なインスタンスタイプを提案 入力:モデルパッケージの ARN を指定するだけで開始可能 テスト内容:SageMaker が用意した標準的なトラフィックパターンでロードテストを実施 所要時間:通常 45 分以内で完了 特徴:簡単に始められる、サーバーレス推論にも対応、高速な初期評価に最適 |
| Advanced ジョブタイプ | 目的:本番環境に近い条件で詳細なパフォーマンス評価を実施 入力:インスタンスタイプやサーバーレス設定、カスタムトラフィックパターン、レイテンシー・スループット要件などを指定 テスト内容:指定した条件に基づくカスタムロードテスト 所要時間:平均 2 時間程度(ジョブ設定とテスト数により変動) 特徴:より精密な評価が可能、本番運用に向けた構成検討に最適、オートスケーリングポリシーの初期設定にも活用可能 |
Studio Classic
2023年11月以降、従来の SageMaker Studio は「Studio Classic」と呼ばれ、新しい SageMaker Studio はより高速で統合されたUIを提供している。
●SageMaker Studio(新しいStudio)
AWSが提供する最新の機械学習統合開発環境。VS CodeベースのIDEやJupyterLab、RStudioを選べる柔軟なUIを備え、数秒で起動可能。Amazon Q Developer によるAI支援やGit連携、S3・RedshiftなどのAWSサービスとの統合もスムーズで、MLOpsやチーム開発に最適。
●SageMaker Studio Classic(従来型Studio)
JupyterLabベースのIDEで、データ準備からモデル構築・トレーニング・デプロイまでを一貫して行える。起動に時間がかかることがあり、Git連携やAWSサービスとの統合は手動設定が中心。個人開発や研究用途に向いている。
※AWSが提供する機械学習向けの統合開発環境(IDE)
| Studio | Classic | |
|---|---|---|
| 概要 | ||
| IDE選択 | 複数(VS Code, JupyterLab, RStudio) | JupyterLabのみ |
| 起動速度 | 高速(数秒) | 遅め(数分) |
| AI支援 | あり(Amazon Q) | なし |
| Git連携 | UI統合 | 手動設定 |
| 拡張性 | VS Code拡張対応 | 限定的 |
| 推奨用途 | チーム開発・MLOps | 個人開発・研究 |
Bedrock

AWS が提供する フルマネージド型の生成AIサービス。大規模言語モデル(LLM)や生成AIモデルを インフラ管理不要 で利用できる。ユーザーはモデルを自分で構築したり学習したりする必要がなく、AWS 上で提供されている複数のモデルプロバイダー(Anthropic、Meta、Mistral、Amazon Titan など)のモデルを API 経由で呼び出して使える。主に自然言語処理やテキスト生成などの用途に使用される。
●Jurassic-2 models
サポートされている言語。英語での最高品質のパフォーマンスに加えて、全ての J2 モデルは、次のようないくつかの英語以外の言語をサポートしている。
対象:スペイン、フランス、ドイツ、ポルトガル、イタリア、オランダ
●ナレッジベース
・検索拡張生成(RAG)を簡単に実装可能。
・構造化・非構造化データの両方に対応(例:S3、Salesforce、SharePointなど)。
・自然言語→SQL変換(NL2SQL)により、構造化データから直接情報取得。
・引用付き応答で、元データの出典を明示。
主な機能
| 複数のモデルが選べる | Anthropic Claude AI21 Labs Jurassic-2 Stability AI (画像生成) Meta Llama 2 / 3 Mistral Amazon Titan など → 1つの API で様々なモデルを比較・利用可能。 |
| 学習やインフラ管理が不要 | サーバー構築、GPU管理、モデル学習を自分で行う必要がなく、即利用できる。 |
| カスタマイズが可能 | ・プロンプト調整 ・ファインチューニング(微調整) ・RAG (Retrieval-Augmented Generation) 構成で独自データと組み合わせて回答を生成できる。 |
| AWS サービスとの連携 | ・Amazon S3(データ格納) ・Amazon Kendra(検索ベースのRAG) ・Amazon SageMaker(カスタムMLとの統合) |
| セキュリティとガバナンス | ・データはモデルプロバイダーに直接渡らず、AWS 内で安全に処理。 ・コンプライアンスや監査対応が必要な企業向けにも利用しやすい。 |
| ユースケース | ・チャットボット / カスタマーサポート ・ドキュメント要約 / 検索支援 ・コード生成 / アプリ開発支援 ・画像生成 / クリエイティブ制作 ・社内ナレッジ検索 (RAG構築) |
| メリット | ・モデル開発不要で即利用できる。データ取り込み、検索、プロンプト拡張までを一括管理。 ・複数のモデルを使い分けられる ・AWS セキュリティ基盤を活用可能 ・ベクトル検索とエンベディングにより、意味的に関連する情報を抽出。 ・セキュアな接続:基盤モデルやエージェントが安全にデータソースへアクセス。 |
| デメリット | ・モデルの「中身」を自由に改造はできない ・利用料金はAPI従量課金 → 大規模利用でコスト増 ・最先端のオープンモデルを自分で細かくチューニングしたい場合は制限あり |
[応答生成を制御する主要パラメータ比較表]
・温度 → 「確率の高低どちらを取りやすいか」を調整
・top_k → 「候補数の幅」を調整。生成する応答のランダム性を制御する。
・top_p → 「確率分布の上位何%までを候補にするか」を調整
| パラメータ | 説明 | 値を小さくした場合 | 値を大きくした場合 | 簡単な例 |
|---|---|---|---|---|
| 温度(temperature) | 出力確率分布の「滑らかさ」を調整。応答のランダム性を制御。 | 決定論的になり、一貫性が高まる。 確率の高い定番の応答を選びやすい。 | ランダム性が増し、多様な応答が得られる。 確率の低い答えも選ばれやすい。 | 「好きな動物は?」 – 低い温度 → 「犬」 – 高い温度 → 「犬」「猫」「キリン」など |
| トップK (top_k) | 次のトークンを選ぶ際に考慮する候補数を制限。 | 候補が少なくなり、安定・一貫した応答になりやすい。 | 候補が広がり、多様で予想外の応答も出やすい。 | 「朝ごはんは?」 – 低い top_k → 「パン」だけ – 高い top_k → 「パン」「ごはん」「おにぎり」など |
| トップP (top_p) (核サンプリング) | 確率分布の上位から「合計確率pまで」の候補だけを考慮。 | 上位候補だけに限定され、予測可能性が増す。 安定した応答になりやすい。 | 確率の低い選択肢も残りやすくなり、ランダム性と多様性が増す。 | 「好きな果物は?」 – 低い top_p → 「リンゴ」 – 高い top_p → 「リンゴ」「バナナ」「ドラゴンフルーツ」など |
Polly

音声発話サービス。文章をリアルな音声に変換するサービス。発話できるアプリケーションを作成できる。
Textract

紙の書類やPDF、画像からテキスト・表・フォーム情報を抽出。
主な機能
| OCR(光学文字認識) | 文字を認識して抽出 |
| 表認識 | 表の構造を理解し、セルごとにデータを抽出 |
| フォーム認識 | ラベルと値のペア(例:氏名:山田太郎)を抽出 |
| 署名検出 | 手書き署名の有無を検出(一部リージョンで対応) |
[使用例]
| 入力形式 | 出力内容 | 利用例 |
|---|---|---|
| スキャンした請求書 | 金額、日付、会社名などの抽出 | 経理システムへの自動入力 |
| 手書きの申込書 | 名前、住所、電話番号などの抽出 | 顧客情報のデジタル化 |
| PDFの契約書 | 契約条件、署名欄の検出 | 契約管理システムへの登録 |
Transcribe

音声を自動的にテキストに変換する。リアルタイムまたは録音済みの音声を高精度で文字起こしできる。100以上の言語と方言に対応しており、日本語もサポートされている。
使い方も比較的シンプルで、音声ファイルをS3にアップロードし、Transcribeでジョブを作成するだけでテキスト化できる。
・話者の識別(話者ダイアライゼーション)や自動句読点の挿入、カスタム語彙の登録など、実用的な機能が豊富。
・字幕ファイルの生成や医療分野向けのTranscribe Medicalも利用可能。
・コールセンターの通話分析や会議の議事録作成、動画の字幕生成など、幅広いユースケースに活用されている。
Translate

AWSが提供するニューラル機械翻訳サービスで、テキストを高精度かつ高速に翻訳するクラウドベースのツール
主な特徴
| ニューラル機械翻訳(NMT) | 深層学習技術を活用し、文脈を理解した自然な翻訳を実現 |
| リアルタイム & バッチ翻訳 | API を使って即時翻訳も、大量のテキストを一括翻訳することも可能 |
| カスタマイズ可能 | 特定のブランド名や業界用語などを定義して、翻訳結果を調整可能 |
| 多言語対応 | 英語、日本語、中国語、スペイン語など、数十の言語間で翻訳可能 |
ユースケース
| ユーザー生成 コンテンツの翻訳 | SNS投稿、コメント、プロフィールなどをリアルタイムで翻訳 |
| 多言語チャット対応 | カスタマーサポートや社内チャットで言語の壁を解消 |
| ドキュメント翻訳 | Word、Excel、PowerPoint などのファイルを一括翻訳 |
| NLP連携 | Comprehend と組み合わせて感情分析やキーフレーズ抽出も可能 |
Comprehend

自然言語処理(NLP)サービスで、機械学習を活用してテキストデータを分析し、チャットデータから顧客の感情(ポジティブ、ネガティブなど)を抽出するなど、価値ある情報を効率的に引き出す。既存のデータをインプットするだけで、迅速に分析結果を得られるため、誰でも簡単に大量のテキストデータから洞察を得ることができる(2026 年 5 月 20 日サポート終了)
・利点として、ユーザー自身が機械学習(ML)モデルのトレーニングやチューニングを行うなど、複雑で手間のかかる作業を省略できる。
・PII(保護対象医療情報)を検出し、マスクまたは除去する機能を備えている。英語またはスペイン語のテキストドキュメントでPII エンティティを検出できる。PIIエンティティは特定の種類の個人を特定できる情報(PII)。PII検出機能を使用して、PIIエンティティを検索したり、テキスト内のPIIエンティティを編集したりする。
主な機能
| 機能 | 説明 |
| エンティティ認識 | テキストから特定のエンティティ(例:人名、組織名、場所、日付、数詞、電話番号など)を自動抽出。 |
| 感情分析 | テキストの感情を識別し、ポジティブ、ネガティブ、ニュートラル、ミックスのいずれかに分類。 |
| キーフレーズ抽出 | テキスト全体からその文脈や内容において最も重要な単語やフレーズを抽出する機能。たとえば、ニュース記事から「新技術」「市場動向」などの主要な話題やテーマを自動的に特定できる。 |
| 言語検出 | テキストが書かれている言語を自動で識別します(最大 100 種類以上の言語に対応)。 |
| トピックモデリング | 大量の文書データを分析し、隠れたトピックやテーマを自動的に抽出。 |
| カスタム分類 | ユーザーが定義したラベル(例:「重要」「非重要」など)を基にテキストを分類。 |
| カスタムエンティティ認識 | 独自のエンティティ(例:商品コード、特定の業界用語など)をトレーニングして識別する機能。たとえば、契約書内の「クライアント名」や「契約日」のような特定のエンティティを定義してトレーニングすることで、独自のビジネスルールに基づいた情報抽出が可能。 |
| 構文解析 | テキストを文法的に解析し、単語の品詞(名詞、動詞、形容詞など)や構文構造を特定。 |
| イベント抽出 | 特定の条件や構造に基づいて、テキスト内の出来事やアクションを抽出。 |
ジョブ
| DetectPiiEntities | テキスト内の個人を特定できる情報(PII)をリアルタイムで検出。 |
| StartPiiEntitiesDetectionJob | 複数の文書を一括で処理する非同期ジョブを開始し、PIIを検出・編集 |
| RedactionConfig | PIIをどのように編集(秘匿)するかを設定 |
Import Model
インポートすると、コピー元のモデルと全く同じ、トレーニング済みの複製モデル(Comprehendのカスタムモデル)が新しいアカウントに作成(コピー)される。
| 必要な設定 | コピー元のAWSアカウントで、コピー先のアカウントからのインポートを許可するためのIAMポリシーを設定する必要がある。 |
| 重要な制約 | インポート元とインポート先のモデルは、必ず同じAWSリージョンに存在している必要がある。異なるリージョンをまたいでのインポートはできない。 |
| 利点 | この方法はComprehendの組み込み機能を使うため、追加のインフラ構築やデータ転送が不要で、最小限の開発作業で実現できる。 |
Medical
AWSが提供する自然言語処理(NLP)サービスで、医療分野向けに特化したツール。
[主な機能]
- 非構造化医療テキストの解析
医師のメモ、退院サマリー、検査結果などから、病名・薬剤・治療法・PHI(保護医療情報)などの医療関連エンティティを自動抽出します。 - 信頼スコアの提供
抽出された情報には、モデルがどれだけ自信を持っているかを示す「信頼スコア」が付与されます。 - オントロジーとのリンク
抽出したエンティティを標準化された医療用語体系(オントロジー)に結びつけることで、より高度な分析が可能です。 - 同期・非同期処理に対応
単一文書の即時解析(同期)と、S3に保存された複数文書のバッチ解析(非同期)の両方に対応しています。
Rekognition

動画や画像認識。イメージや保存済みのビデオから有名人を認識できる。
Lambda関数を使用するとスケーラブルでコスト効率の高いアプリケーション層が得られる。イメージ内の有名人を認識し、認識した有名人に関する追加情報(時間など)を取得するには非ストレージ型のAPIオペレーション「RekognizeCelebrities」を使用する。Rekognition APIにイメージや動画を指定すると、モノ、人物、テキスト、シーン、アクティビティを識別。
Kendra

AIを活用して、「自然言語検索」や「セマンティック検索(文脈や意味を理解した検索)」を実現する。AWSのフルマネージドサービスなので、運用管理の手間が少なく、拡張性にも優れている。質問に対してインテリジェントな回答を生成できるため、検索拡張生成(RAG)アプリケーションの構築に最適。
データソースコネクタ
Kendraは「データソースコネクタ」という機能を使って、様々なデータソースに接続し、検索対象のインデックス(索引)を作成する。接続先として、Amazon S3の他に、Microsoft SharePointやGoogle Driveなどが挙げられている。
このコネクタは、データソースを定期的にスキャンし、ドキュメントの変更や追加を自動でインデックスに反映させるため、常に最新の状態で検索ができる。
[S3 との連携]
「Amazon S3 コネクタ」を使うことで、S3バケットに保存されているテキストファイルなどを直接インデックス化し、高精度なセマンティック検索を簡単に実現できる。S3などの多様なデータソースに接続するだけで、AIによる高精度な意味検索を簡単に構築できるサービス。インデックスを自動で最新に保ってくれるため、RAGのような高度なアプリケーションにも適している。
Glue Data Brew

ノーコードでデータのクレンジング(前処理)(データのクリーニング・整形・変換)を行えるGUIベースのETLツール。分析、レポート、機械学習などの後続タスクのために、クリーンで安全なデータセットを簡単に準備することができる。
[Data Wrangler との違い]
・Data Wrangler:コードで柔軟にデータ処理したい人向け
・Glue DataBrew:ノーコードで視覚的にデータ整形したい人向け
| 項目 | Data Wrangler | Glue Data Brew |
|---|---|---|
| 操作方法 | Pythonコード(pandas) | GUI(ノーコード) |
| 対象ユーザー | エンジニア、分析者 | 非エンジニア、アナリスト |
| 柔軟性 | 高(自由なロジック記述) | 中(組み込み変換に依存) |
| 学習コスト | Python知識が必要 | 直感的で学習コスト低め |
| 処理対象 | S3, Redshift, Athenaなど | S3, Redshift, RDSなど |
| 主な用途 | ETL自動化、分析前処理 | データ整形、品質評価 |
特徴と構成
[主な特徴]
| データ品質のプロファイリング | データ内の欠損値や異常値の検出、統計情報の可視化を簡単にできる。 |
| プライバシー保護 | 機密データを安全にマスク(隠す)処理ができるため、プライバシー要件を満たしながら、機械学習モデルの準備などにデータを利用できる。 |
| 多様な変換処理 | 250以上の変換処理(欠損値処理、正規化、型変換、フィルタリングなど)を用意。 |
| 検出マスキング | ・検出:2、3回クリックするだけで、データ内のPIIや機密情報を含む可能性のある列を自動で特定する。 ・コード不要のマスキング:コードを記述することなく、データセット内の情報を自動で識別し、「墨消し」「ハッシュ化」「暗号化」といったデータマスキングを適用できる。 |
| 自動化 | レシピを保存して定期的にジョブを実行可能 |
| スケーラブル | フルマネージドでリソース管理不要 |
[構成要素]
| データセット | S3、Redshift、RDS、JDBCなどから接続可能なデータソース |
| プロジェクト | データをプレビューしながら変換処理を設計する作業スペース |
| レシピ | 実行する変換処理のステップを記録したもの(料理のレシピのようなイメージ) |
| ジョブ | レシピをデータセットに適用して処理を実行する単位 |
Redshift ML

AWS のデータウェアハウスサービス「Amazon Redshift」に機械学習機能を統合したもの。SQL を使って直接機械学習モデルを作成・トレーニング・デプロイできるのが最大の特徴。
主な特徴
| SQLだけでMLモデルを構築可能 | PythonやJupyterなどを使わず、RedshiftのSQL文でモデル作成・予測ができる。 |
| SageMakerと連携 | 実際のトレーニングは Amazon SageMaker が裏で処理。AutoML によるアルゴリズム選定や前処理も自動化される。 |
| データ移動不要 | Redshift内のデータをそのまま使えるため、S3へのエクスポートなどの手間が省ける。 |
| 教師あり・教師なし学習に対応 | 回帰、分類、クラスタリング(K-Means)など、基本的なMLタスクに対応している。 |
Q Business
AWSが提供する企業向け生成AIアシスタント。社内の情報を活用して、業務効率化や意思決定支援を行うための強力なツール。
特徴と構成要素
[主な特徴]
| 社内データを活用した自然言語対話 | 社内文書、営業資料、技術マニュアル、人事規定などを元に、チャット形式で質問に回答 |
| RAG(検索拡張生成)による高精度な応答 | インデックス化された情報を検索し、生成AIが回答を生成 |
| 多様なデータソースと連携 | Amazon S3、Salesforce、Microsoft 365、Dropbox、Google Driveなど40以上のコネクタに対応 |
| セキュアな認証・認可 | AWS IAM Identity Centerを利用し、ユーザーごとのアクセス制御が可能 |
[機能構成]
| コンポーネント | 概要 |
|---|---|
| データソースコネクタ | 社内外の情報を取り込むための接続機能 |
| インデックス | 取り込んだデータをAIが使いやすい形に変換(StarterとEnterpriseの2種) |
| Retriever | 質問に応じて適切な情報をインデックスから取得 |
| LLM | Amazon Bedrockを裏で活用し、自然言語応答を生成 |
| Web UI | ブラウザやSlack、Teamsなどから利用可能 |
その他機能
●ContentBlockerRule
Amazon Q Businessのガードレール機能の一部であり、ユーザーが制限されたトピックや禁止されたフレーズに触れた際の応答方法を制御するためのルール。制限されたトピックについて質問されたことをエンドユーザーに通知し、次にとるべき手順を提案するカスタムメッセージを設定することができる。
| 項目名 | 説明 |
|---|---|
| systemMessageOverride | ブロックされたトピックに関する質問を受けた際に表示されるカスタムメッセージ。最大350文字まで設定可能。 |
| パターン制約 | メッセージはUnicode制御文字を含まない必要があります(正規表現: ^\P{C}*$) |
| 必須かどうか | systemMessageOverrideは任意。設定しない場合はデフォルトメッセージが使用されます。 |
●グルーバルコントロール
アプリケーション全体の全ての対話に適用される。
| 応答の設定を制御 | 大規模言語モデル(LLM)が直接答えを返すが、企業データソースを参照しながら答えを返すかなどの応答設定を制御 |
| 用語をブロック | 特定の用語の使用をブロックし、機密情報やセンシティブなフレーズの生成を回避 |
| ファイルアップロードの制御 | エンドユーザーによるチャット内でのファイルアップロードの可否を制御 |
| Amazon Q Apps の制御 | エンドユーザーによるAmazon Q Apps の作成・利用の可否を制御 |
API参照ルール
サブスクリプションプラン
| プラン名 | 月額料金 | 主な機能 |
|---|---|---|
| Amazon Q Business Lite | $3 | チャットによる質問応答 |
| Amazon Q Business Pro | $20 | アプリ作成、カスタムプラグイン、QuickSight連携などが可能 |
Trainium
AWSが提供する機械学習トレーニングに特化した、高性能かつエネルギー効率が高い機械学習トレーニング専用のインスタンス。
・一般的なGPUよりもコスト効率が高く、消費電力を抑えながら高速なトレーニングを実現。
・TensorFlowやPyTorchなどの主要なフレームワークに対応。
EC2 Trn1インスタンス
AWS Trainiumチップを搭載し、大規模言語モデル(LLM)などの高性能な深層学習(DL)トレーニングのために設計されている。他のEC2インスタンスと比較して、トレーニングにかかるコストを最大50%削減できるとされている。Trnシリーズは、機械学習トレーニングに特化しており、エネルギー効率が「非常に高い」と評価されている。
Mechanical Turk(MTurk)
人間の判断が必要な小さな仕事(タスク)を、世界中の人に依頼してこなしてもらう仕組み。18世紀の「メカニカル・ターク(自動チェスマシン)」にちなんで、「機械のように見えるが実は人間がやっている」ことを表現。
| 依頼者(リクエスター) | 企業や研究者など。タスクを投稿して報酬を設定。 |
| 作業者(ワーカー) | 世界中の個人が参加可能。好きなタスクを選んで報酬を得る。 |
・依頼者は、ウェブUIやAPIを通じてタスクを提出し、人間の作業者がそれを完了・提出する。
・作業者はタスクを選んで実施し、完了後に報酬を受け取る。
・APIを用いたやり取りは、リモートプロシージャコールのような形式で行われる。
・実質的には「人力による人工知能」のような仕組みで、柔軟で多様なタスク処理が可能。
[タスクの例]
・画像に写っているものを分類する
・音声を聞いて文字起こしする
・アンケートに答える
・AI学習用のデータにタグをつける
[公式サイト引用]
IoT サービス

基礎知識
●AWS IoT
IoTデバイスとAWSクラウドサービスをつなぐための仕組み。AWSは、デバイスとクラウドを連携させるためのデバイス向けソフトウェアも提供しており、これによりIoTソリューションの構築がスムーズになる。
IoT Core

【センサーデバイスに特化】
インターネットに接続されたデバイスから、クラウドアプリケーションやその他のデバイスに簡単かつ安全に通信できるクラウドサービス。大量のIoTデータを効率的に収集することができる。リアルタイムには不向き。
※MQTTプロトコルをサポートしている
・ 数十億のデバイス、メッセージをサポートし、それらメッセージをエンドポイントや他デバイスに確実かつセキュアに処理してルーティングする。
・アプリケーションがインターネットに接続されていない場合でも、すべてのデバイスを常に追跡して通信できる。
[使用例]
・産業、コンシューマー、商業、オートモーティブ用のワークロード向けに IoT サービス。
・センサーデバイスを利用した車両管理アプリケーションを容易に構築することができる。
※AWS IoTの仕組み
IoT Core Basic Ingest
IoTデバイスからのメッセージをメッセージブローカーを経由せずに直接ルールエンジンに送信できる機能。
[主なポイント]
| コスト削減 | 通常のメッセージングではメッセージブローカーを通すためコストが発生しますが、Basic Ingestを使うとその部分のコストを削減できる。 |
| 用途 | デバイスからのデータを他のデバイスに配信せず、ルールアクション(例:Lambda実行、S3保存など)だけを実行したい場合に最適。 |
| 使い方 | 特定のトピック形式(例:$aws/rules/ルール名/トピック名)でメッセージをパブリッシュすることで利用できる。 |
| 注意点 | 他のデバイスが同じトピックをサブスクライブしている場合は使えません。あくまで単方向の処理に向いている。 |
MQ for RabbitMQ
メッセージキューイングシステムとしての利用が主である。
IoT Fleet Wise

特定のフリート管理ソリューション向け。
IoT Greengrass

【ローカルでAWS処理】
クラウドの処理能力をエッジデバイスに拡張するためのサービス。ネットワークが不安定な環境でも、ローカル、オンプレミスでデータ処理やアクションが可能になる。
[特徴]
| リアルタイム性 | クラウドに頼らず即時処理が可能 |
| コスト削減 | 不要なデータ送信を減らし、通信コストを抑制 |
| 信頼性 | オフラインでも動作するため、遠隔地でも安心 |
主な機能
| 機能 | 説明 |
|---|---|
| ローカル処理 | Lambda関数をエッジで実行し、リアルタイムでデータ処理が可能 |
| クラウド連携 | S3やIoT Coreと連携して、データの保存や通信がスムーズに行える |
| 機械学習モデルの展開 | SageMakerで作成したモデルをエッジにデプロイして、ローカルで推論が可能 |
| セキュリティ | TLS通信、認証、アクセス管理など、セキュアな運用が可能 |
| コンポーネント管理 | モジュール式で必要な機能だけを選んでデプロイできる柔軟な構成 |
24/06/27 JAWS名古屋:「× Media-JAWS@中京テレビ」参加記録
前置き
先日参加したJAWS名古屋の活動、「Media-JAWS@中京テレビ」技術交流会の参加記録です。
仕事の環境が変わり、今からでも積極的に情報網を広げてフットワーク軽く成長したいと思い始まった本年度。初めてのJAWS名古屋参加でした。
発表内容
下記にて発表内容の概要記載します。
①ゼロからのデータ分析基盤立ち上げ1年間の歩み
まずは中京テレビとAWSのなりそめを下記のように紹介いただく。
★中京テレビではAWSを使用している
| 2016年 | 素材のクラウド上PVシステムでAWSを利用 | ベンダー |
| 2018年8月頃 | インターネット関連部署の担当者がアカウントを作りテスト開始 | 内製 |
| 自社HP基盤のCDNをAWSに切り替える | グループ会社 | |
| 2019年3月頃 | 自社HP基盤をすべてAWSに切り替える | グループ会社 |
| 2020年4月頃 | 在名4名共同配信PFでAWSを利用 | グループ会社 |
| 21年~ | 事業開発にて外部でAWSのサービス制作(運用後の管理のみ依頼) | グループ会社 |
| 配信関連のデータやりとりでAWS S3を利用するなどのニーズに対応。配信視聴結果データ、各基幹システムデータなどの集約の検討が始まる。 | 内製 |
これら取り組みの一環で第一の課題となったのはアカウント管理(IAM)とコストパフォーマンスでした。
クレジットカード情報の残留や支払い元が退職予定の社員だった場合などと、初歩的ながら忘れがちなこと。散見するアカウントの管理、テスト設定が残っていたために課金が発生したなどと。。。
簡単ながら課題と対策を展開いただいた。この知識は有難く得た知識として別個記載することにします。
様々な問題を経て、ベンダーのサポートを受けながらも数年で内製化。
ETL(複数データの抽出・変換・書き出し)監視の環境を確立された。放送されたものはもちろん、Youtubeなどの動画コンテンツサービスやSNSを対象として、統合ダッシュボードに表示できるようになったとのことです。
※以前までは各サービスごとのダッシュボードを個別に確認されていたようです
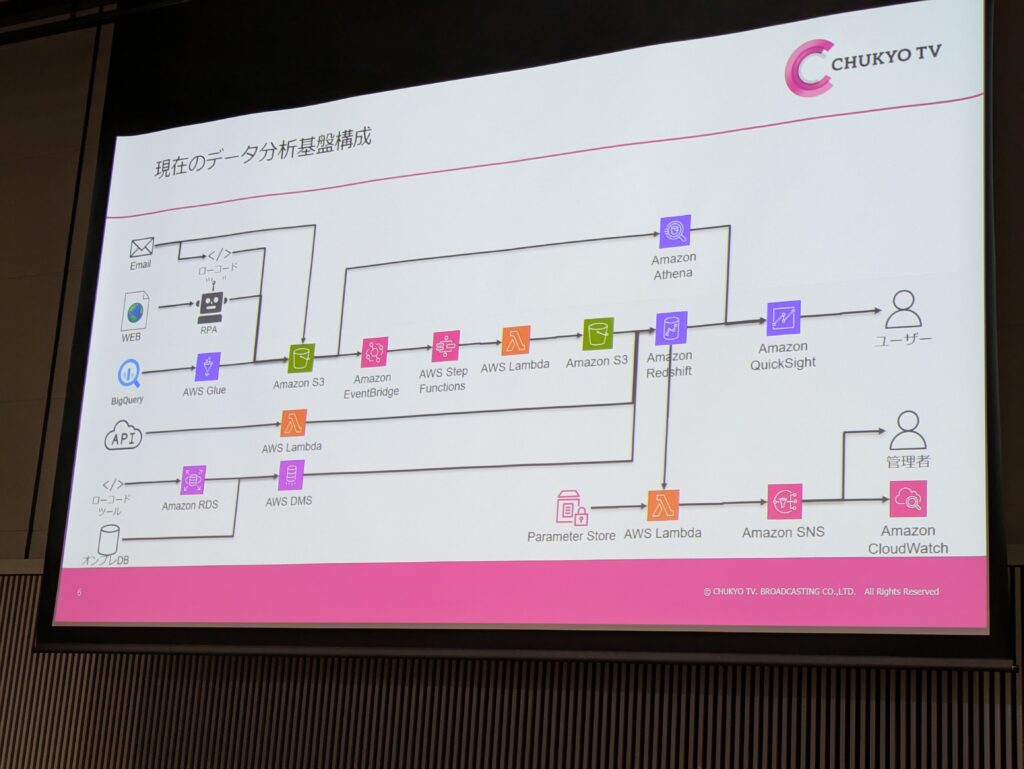
クラウド導入の一例を簡単に知ることができたこと。また、TV局という仕事上では関りの少ない業界の取り組み、システムを知ることができたのはとても有益でした。
②固定費用0円の完全サーバーレス(AWS)なRAG構成と業務効率化事例紹介
続いても放送業界に関する内容。AWS Summitでも話題沸騰だった BedRockを利用した取り組みでした。
※BedRockの概要
・各種生成AIのモデルをAWSが提供するAPIを通して利用できるマネージドサービス。
・他のAWSサービスとの統合が簡単、多様なモデルをAWSマネージドコンソールで試せる
一例として挙げられたのは、北海道テレビ放送で放映されたコンテンツの情報をブログに自動的に書き起こすというもの。
流れとしては以下のよう。
動画のキャプチャを撮って生地の内容と関連するように指定する方法
①動画ファイルをS3に入力
②Transcordeにて、オーディオから文字を起こす
③OpenCVで記事に使用するキャプチャをとる
④キャプチャした画像を記事の段落ごとに指定するように、Lambdaで処理する
⑤キャプチャをテキストに変換・保存
⑥キャプチャを活用して記事生成
※記事作成時は文字お越しのスクリプトから記事を作成し、各段落に合うイメージをテキスト情報として読み込み
※OpenCVは、プログラミング初心者でも気軽に画像処理・画像解析を行うことができる

ただ文章や画像を並べるだけでなく、文章・トピックの間隔、最良の画像を選出、設定するようなシステム構成になっており、人間が手動で執り行ったものと同等の完成度と感じました。
AI技術が日々進化していることを実感せざるを得ない、そんな講演でした。
③自社サービスをお客様が簡単に利用出来る為にやったこと
トラフィック・シム社 で展開しているサービスとAWSを掛け合わせた内容でした。
コンテンツは「営業を介さずサービスを提供」「顧客のニーズに素早く対応」と感じました。
上記実現のために利用したAWSサービスは以下2つ。
【1】AWS Market Place
厳選されたデジタルカタログ。
ユーザーはサードパーティーのソフトウェア、データ、サービスを検索、購入、デプロイ、管理してソリューションを構築し、ビジネスを運営できる。企業側は手軽に出品することができる。
また、ユーザーに発生する料金はAWS内で一元管理される。
【2】ECR Public Gallery
Amazon ECR パブリック リポジトリでホストされているコンテナイメージを検索して共有するための公開 Web サイト。
Docker Hubの代替として利用できるコンテナレジストリ。AmazonによりDocker Hubのイメージが複製され公開されている。
「ECR Public Gallery」はこの時初めて知ったサービスでした。これを活用してトラフィック・シム社は自社サービス「MediaHarbor」を以下のように展開されているとのこと。
①サービス提供元に登録し、APIキーを入手➡ライセンス管理
②EC2を立ち上げ、提供された手順書にならいコマンドを実行
③ECR Public GalleryからMediahaborをインストールすることができる?
結果として・・・
・コンテナやインストーラーは無料配布
・インストーラーですぐ構築(オンプレ/クラウド)
・利用時間でのポイント消費型であるため、使用分だけ課金される
・ユーザーの思い付きに対応して提供できる
➡数クリックで提供が早く、営業の代替ともなる

④AWSアーキテクチャ図をスマートに描く方法を試してみた
普段業務上で使用するであろう(?)インフラ構成描画ツールの比較を以下のように所感や経験を交えて説明いただきました。
・draw.io
手軽に作図できる。アイコンも豊富。割と新しい。
・PlantUML
UML図作成用のテキストベースツール。アイコンは割と新しいが、思ったように配置できない
・Mermaid
テキストベースの作図ツール。AWSアイコンセットがないため、色と形で工夫が必要
・Diagrams
Pythonコード図で生成。アイコンセットが古い。
・EraserAI
生成AIを使って自然言語(プロンプト)での作図もできるツール。図をCode化できる。
私もたまに使用するため、こんなに種類があるのだと驚きました。
普段、Cacooというものを使って……Cacooがない。。。。
所感としては状況応じて使用することが有効かなと感じました。
大衆の中で概要を説明するのであれば数メートル離れていても理解できる配色、図解を用いれるツール。AWSサービスに詳しくない人に説明する人にも同様。
詳しい方にはしっかり目で追う必要のある描画図。
これらはどのように描くかということも大事ですが、如何に説明し理解を得るかが重要なポイントだと常日頃感じています。それを実現するための「やり方」を本講演は教えてくれたと感じました。
⑤プレゼント応募システム費を97%削減した話
東海テレビ と外部ベンダーとのお付き合いでクラウド化に成功した事例。
タイトル通り、プレゼントの応募システムへのアクセス集中に耐えれるようにしたとのことです。
お話いただいたことを以下にまとめます。
【困りごと】
・全国のネットスポーツ中継
・ドラマで出演者が某事業所
・プレゼントを番組で煽りまくった(キャッシュなど)
【達成要件】
・毎分10,000は華麗にさばきたい
・ユーザーフォームは無制限
・とにかく安いやつ
【旧構成】
LB(日立ArraysOS)の背後にWebSV(Apache)×2をフロント、バックエンドにDB(Postgresql)
→セキュリティのポイント:自分で作らない
→WAF:たまに誤検知が発生することが少し悩み
【コンセプト】
・特別な設定なしで大量アクセスOK
・コストカット
・セキュリティにも気を遣いたい
【流れ】
簡単な下図を書いた後に、TOKAIコミュニケーションズ社に依頼。
●背景
・ハードウェアのサポート期限が迫っている
・メンテナンスにかかる費用負担分とコスト削減などのクラウドストサービスによるメリットを享受したい。
・サーバーに接続する信頼性の高い回線を冗長構成で実現したい。
●導入サービス
・AWS接続サービス
・AWS運用管理
●効果
・本社とAWSを結ぶ接続回線を冗長化しセキュア且つ信頼性の高い接続環境を実現
・業務システム群のAWS意向を見据えたAWS環境を構築
・専用サポートプランの採用でVPC間の通信が容易になった
【結果】
・毎分32,000件裁けるように
・ユーザー・フォーム数は無制限に
・利用費が97%安くなった(人件費を入れたらもっと!)
出来上がった本システムは5万円で運用できているらしいです。
クラウドを導入するための第一歩の動きとして、とても参考になります。
ただ、ベンダーにすべて任せては知識が付かない、という考えもあるため、ここからどのように内製に繋げたかとても気になるところです。
私も懇親会(講演の後のお食事会)に参加すればよかったでしょうか・・・
⑥terraform-provider-aws にプルリクしてマージされるまで
開発者サイドの苦労、葛藤をお話いただきました。開発側の動きは認識があまいため、やんわりとしたイメージしか持てませんでした。
概要としては、Terraform上でのプルリクエスト(略称:PR)~マージまでの苦労と葛藤です。
Terraform とは書き上げたコードからクラウド環境を構築ができるという優れものです。
AWSには同等のサービスとして、CloudFormationがありますが、、、確か汎用性や機能性の面でTerraformが推進されています。
このTerraformにAWSが 「Terraform provider aws」 というプロバイダー(ライブラリのようなもの)を提供しているようです。これにより、Terraform上での開発、展開、技術促進が捗る?ということでしょうか。見聞きしていたところ、GitHubと同じような位置づけと感じました。
以下、登壇いただいた方からのコメントです。
【プルリクするまではスムーズ】
・プルリクで従うべき手順がドキュメントに書いている
・ざっくりいえばAWS SDKを使ってリソースを探したり、変更するだけ。普段SDKでアプリ開発しているのと同じ
・どのAWSも設計がほぼ一緒であるため、既存コードを参考にすぐ書けるものもあった。
・受入テスト(実際のAWSにデプロイして実行)もコード化されてっるので、動作確認も簡単だった。
➡ただ、プルリクがマージされるまでに時間がかかる。
terraform providerにPR(プルリクエスト)を出したが、管理元に中々マージしてもらえない・・・そんな内容でしょうか。


⑦Amazon IVS: 新しいインタラクティブメディア体験を実現する
AWSご所属の Hao Chen氏に登壇いただきました。
カナダ支部(?)所属の方でご多忙の中、お時間をいただけました。
AWSで音声配信サービスを展開されており、その取り組みについて発表いただきました。
その音声配信サービスとは「Twitch」です。
※Twitch:Twitch Interactive(Amazon.com子会社)が提供するライブストリーミング配信プラットフォーム
このサービスを実現させるAWSサービス、それは「Amazon IVS」。これまた初耳です。
- Amazon IVS
世界中の視聴者が低レイテンシーまたはリアルタイムの動画を利用できるようにするマネージド型ライブストリーミングソリューション。これにより、魅力的なライブ体験を実現できる。
・Twitchを支えるネットワークとインフラ
・累計一年間1.35兆分ものライブ動画再生
・低遅延(2~5秒)のHLSストリーミング
・超低遅延(300ms)のWebRTCのストリーミング
・ストリームチャット(WebSocket)
まだアソシエイトレベルの知識しかありませんが、ライブストリーミングサービスを配信したいから・・・なんて問題は出てきていません。
今後のことを視野に学ばせていただきました。
⑧AWS上で構築する生成AI実行環境(Dify のローカル環境構築)
アクセンチュア社から今流行りの生成AIについて発表いただいた。
生成AIということで発表いただいたサービス、「Dify」。続けて初耳のサービスです。
AWSでAMIとしても提供されており、超簡単に生成AIのプライベート環境の構築ができるそうです。
- Dify
オープンソースのLLM(大規模言語モデル)アプリ開発プラットフォーム。RAGエンジンを使用して、エージェントから複雑なAIワークフローまでLLMアプリを編成できる。
・GUI画面操作で複雑なタスクを実行するAIエージェントを簡単に作成できる
・複数モデル(ChatGPT、Bedrock、Llamaなど)を包括的に利用可能
・作成したエージェントをAPIとして公開し、既存のアプリケーションに組み込むことができる
・LLMOps 機能が組み込まれている
かつてはチャットボットを便利だ、人件費削減だと歓喜していましたが今や簡単に作れてしまうサービスになってしまったと感じます。
本講演ではDifyを実際に使用したチャットボットの作成を実演いただきました。
GUI操作でとても見やすいですが、設定なり操作感が少し難しそうでした。

⑨完全未経験から民放連盟賞を受賞したシステムを開発するまで
最後はアイスブレイクのようなご講演でした。
HTB北海道テレビ放送(株)にご所属されている方で、どのようにAWSを社内システムにクラウドリフトされたかご講演いただきました。
フランクで明るい巧みな話術で終始リラックスして拝聴しておりました。
クラウド化する際に、雑多なインフラ構成図で外部ベンダーに持ち込んだエピソードはとても印象的であり、始めるためのアクションというのは様々なものだと改めて感じました。
おわりに
初めての名古屋JAWS、総合的に見てもまだエンジニア的観点・思考が不足していると痛感しました。
業務では得られない知見や思考、アイディアは積極的に足を運び吸収すべきだと改めて感じました。
エンジニア業界、様々な方が在籍されていますが、とても親しみやすそうな方ばかりでした。
こういった柔軟性、協調性、探求心に重きをおけるよう方々から今後いろいろ学ばせていただき、成長の糧にしていけるように活動していきたいものです。
そのため、上記でも話のありました懇親会。。。参加したかったのですが、実務経験のなさ故に弱腰になってしまいました。
次は否が応でも、弱さを引きずってでも参加しようと思います。
AWS MFA認証 を解除した件
経緯
スミスです。
断捨離がクセになってしまい、時々スマートフォンのアプリも断捨離してしまうことがたまにあります。
その際、たま~に「もう使わないだろうな」と考えずにアンインストールしてしまうことがあります。
そんなわけで、半年ほど前に「Google Authenticator」を消してしまいました。
再インストールしても、情報は残っていません。。。
二度目というのは内緒です。
対応記録
余計な対応を挟んでしまっていますが、生暖かい目で流してあげてください。
①サインインのトラブルシューティング
ルートアカウントにMFA認証をかけていました。
そのため、IDとパスワードを入力すると当然MFA認証を求められます。
画面のように下部に「MFAのトラブルシューティング」とありますので、こちらを左クリック。
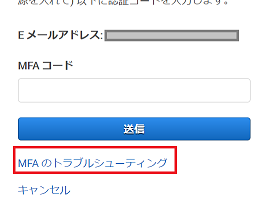
画面が遷移されると、
・ステップ1:Eメールアドレスを検証する
・ステップ2:電話番号の確認
・ステップ3:サインイン
と書かれた画面に記載されています。ここの画像を取り忘れていました。ご容赦願います。
ここで問題なく処理されればいいのですが、「ステップ2:電話番号の確認」で失敗してしまいます。
着信がかかってきませんでした。
「ステップ2:電話番号の確認」が失敗すると、「AWSサポートにお問い合わせください」と対応ページの提案を受けます。
早速、左クリック!
②AWSの問い合わせフォームに移動
「①」の対応にて、下記画像のサイトに遷移します。
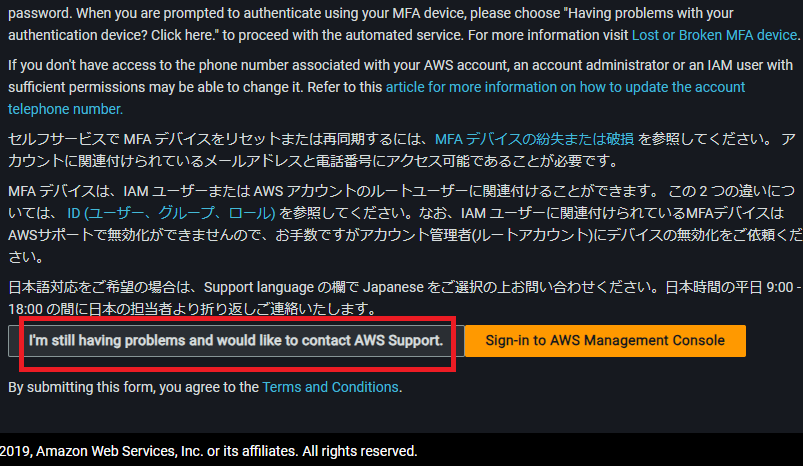
ここで私はひとつミスをしました。「Sign-in to AWS~」という方を選択してしまいました。
ログインできないのにコンソール画面に移動するってどういうこと???
そう疑問に悩んだ挙句、安パイで 「AWS問い合わせフォーム」から問い合わせしました。
返信として、上記画像のサイトへと案内されてしまいました。そりゃそうですよね。。。
間違えないように赤枠に記載されている箇所を左クリックで選択しましょう。
すると、画面下部に入力フォームが表示されるようになります。
必要な情報を入力し送信すると、「平日の9時頃に電話がくる」旨、表示されます。
サインインして確認するようなパソコンが必須になる対応はありません。
土日に申請をしている場合は、基本的に月曜日に対応いただけます。
最高過ぎます。
③平日、電話対応
平日の9時にAWSサポートから電話を受領しました。
「氏名」「登録のメールアドレス」を口頭確認した後に、MFA認証をリセットしてもらえました。
以降、AWSのルートアカウントには、「ID , パスワード」のみでサインインできるようになります。
つまり、初期登録の状態にもどることになります。
最後に
AWSサポートの方、私の断捨離がご迷惑をおかけしました。。。
Encrypt

基礎知識
●共通鍵暗号
鍵は1つ使う。
暗号化と復号に同じ鍵を使う、高速に暗号化、復号できる。安全な受け渡し、保管を実現。ストレージの暗号化に使用されるケースが多い。
●公開鍵
鍵は2つ使う。公開鍵認証形式(非対称鍵暗号)
鍵を持っている人からのみ、一般ユーザーのログインを許可する。 公開鍵と秘密鍵のキーペア。
- 秘密鍵ファイル:パソコン側に置く
- 公開鍵ファイル:サーバー側に配置する
公開鍵で暗号化したデータは秘密鍵で復号できる。共通鍵暗号と比べて、複雑で処理は重い(CPU能力を使う)暗号化に加えて、デジタル署名やデジタル証明書に使われる技術。
※受信者は鍵のペアを予め作っておき、公開鍵を送信者に渡しておく
※公開鍵認証ではログイン時に「パスフレーズ」を使用する
[共通鍵と公開鍵の併用]
共通鍵を公開鍵で暗号化し、復号は秘密鍵。実際の通信は共通鍵暗号で暗号化/復号を行う。
安全性とパフォーマンスの両立を実現。
KMS

(Key Management Service)【鍵管理サービス】
データ暗号化に利用する暗号化(または復号化)できるKMSキーの作成・管理を行うためのAWSのマネージドサービス。AWS所有のマルチテナント管理を共有で利用し、耐久性が高く、高可用性である。
- 鍵の保管:KMSキーを安全に保管するストレージ(安全なロケーションの提供)
- 鍵の管理:KMSキーのライフサイクル管理、及び鍵の管理や利用に対する認証・認可・記録するアクセス制御
[参考]
・他のAWSと連携しやすい(S3サーバー、オブジェクト側の暗号化など)(連携するAWSサービス:50以上)
・CloudHSMに比べると安価に利用でき、手軽に暗号化キーを管理
・キーの使用・管理の監査証跡として、有効
[独自のキーマテリアルの場合]
独自のキーマテリアルをインポートするには、最初にキーマテリアルなしで KMS キーを作成。そして、独自のキーマテリアルをインポート。キーマテリアルなしで KMS キーを作成するには、AWS KMS コンソールまたは CreateKey オペレーションを使用する。キーマテリアルなしでキーを作成するには、オリジンとして EXTERNAL を指定。
- キーマテリアル
CMKのメタデータを除く暗号・復号に利用する部分。
鍵の種類
| マスターキー | ・データキーを暗号化する ・AWS内部で永続化される ・ユーザーがローカルにエクスポートできない |
| データーキー | ・データを暗号化する ・AWS内部で永続化されない ・ユーザーがローカルにエクスポートできる |
[マスターキーの種類]
●KMSキー(CMK3種類)
データの暗号化、復号、再暗号化を行い、外部が使用するデータキーを作成する。キーストアに厳重に格納される。KMS キーには、キー ID、キー仕様、キー使用法、作成日、説明、およびキーステータスなどのメタデータが含まれる。
| カスタマーマネージドキー (カスタマーマスターキー) | ユーザーが作成するKMSキー。データーキーを暗号化するための鍵。削除した直後であれば、削除のキャンセルができる。 |
| AWSマネージドキー | AWSがユーザーのAWSアカウントで作成するキー。AWSサービスが作成・管理・使用するCMK。 キーの名前は「aws/サービス名」。このため、名前の先頭に「aws」を付けられない。 3年ごとに自動ローテーション。 |
| AWSが所有するキー | AWSがユーザーのサービスアカウントで作成するキー。ユーザーからは見えない。 |
[データーキー]
●CDK(Customer Data Key)
対象のデーターを暗号化するための鍵(データキー)。
※公式の資料ではCDKという言葉はほとんど使われていない
[使われている関連記事]
暗号化(エンベロープ暗号化)
AWS KMS はセキュアで弾力性の高いサービス。データーキー、マスターキーを用いる。
暗号化や復号の際にはKMS(またはCloudHSM)に鍵の使用リクエストAPIを送信し、データキーを一時的に復号化して暗号化、復号する。
[暗号化機能] (参考)
- Encrypt:文字通りデータを暗号化するためのAPI(4KBまでの平文字に対応)
- Decrypt:復号のためのAPI
- GenerateDataKey:ユーザーがデーターの暗号化に利用するための、カスタマーキーを作成する
[暗号化流れ]
- アプリケーションから AWS SDK の GenerateDataKey オペレーション(キーID)を使って CDK を生成。
- 作成されたCDKをCMKで暗号化する。CMKはデータキーを2つ作成する。
※認識が混ざるためCDKという単語は不使用
・データーキー:「A」とする
・暗号化されたデーターキー:暗号化された「A」とする - ユーザーは工程「2.」で作成された、「A」で暗号化したいデータを暗号化する。
後に、「A」は削除して、暗号化された「A」を手元に残す。
[復号化の流れ]
- 暗号化された「A」をKMSに送る。
- CMKが暗号化された「A」と「A」を結果として返す。
- ユーザーは結果として返された「A」でデータを復号化。不要であれば「A」は削除。
キーの管理
●KMS Generate Data Key
アプリケーションでデータをローカルで暗号化することができる。一意の対象データキーを生成する。データキーのプレーンテキストコピーと、指定したCMKで暗号化されたコピーを返す。プレーンテキストキーを使用して、KMSの外部でデータを暗号化し、暗号化されたデータと主に暗号化されたデータキーを保存できる。
●マルチリージョンキー
複数のリージョンで同じように KMS Key を相互使用ができる。関連するマルチリージョンキーセットごとに、同じキーマテリアルおよびキーIDがあるため、1つのAWSリージョンでデータを暗号化し、再暗号化やAWS KMS へのクロスリージョン呼び出しを行うことなく異なるAWS リージョンで復号できる。
・キーは個別に管理、独立して使用、連携させて使用することもできる。
[自動キーローテーション]
KMSで生成した各キーマテリアル(ベース)を年次(1年)で更新する。エイリアス、Key ID、Key ARNは新キーに引き継がれる。
・古いキーマテリアルがすべて永続的に保存する。削除されない限り、KMS キーで暗号化されたすべてのデータを復号できる。
・サポートするのは、AWS KMS が作成するキーマテリアルを持つ対称暗号化 KMS キーのみ。(インポートしたCMKは対応不可)
・KMS キーのキーマテリアルに関するローテーションの追跡は、Amazon CloudWatch とAWS CloudTrail で実行できる。
連携サービス
[CloudTrailとの統合]
・KMSで内ユーザーやロール、またはAWSのサービスによってじっこうされたアクションを記録。
・KMSコンソールからのコールやKMS APIへのコード呼び出しを含むKMSのすべてのAPI呼び出しをイベントとしてキャプチャし、証跡を作成。
(リクエスト作成元のIPアドレス、リクエストの実行者・実行日など、)
・すべてのキーの使用ログを表示できるため、規制およびコンプライアンスの要求に応えるために役立つ
Cloud HSM

(Hardware Security Module)
ハードウェアセキュリティモジュール(HSM)を使用した暗号鍵管理サービス。KMSに比べると高価。
※HSMインフラの管理責任:ユーザー⇒AWS クラウドで暗号化キーを簡単に生成して使用できる
・HSMのFIPS認定 :FIPS140-2 Level 3(3認証済み)
・KMS経由でAWSサービスと連携可能。
・異なるリージョンからCloudHSMにアクセス出来ない
・バックアップイメージを異なるリージョンに転送してサービスをリストアすることは可能。
・VPC外からアクセスする場合には、CloudHSMがあるVPCにルーティングする必要がある
[サポートする暗号鍵]
共通鍵と公開鍵。占有タイプ(Amazonの管理者もアクセスできない)のハードウェアで暗号化キーを保管(不正防止機能を装備したハードウェアデバイス内でキーを操作)
・物理デバイス制御とキーへのアクセスを持たないアプリケーションで秘密鍵を強力に保護できる。そのため、キーがAWS環境の外に移動されない。
[オフロード機能]
CloudHSM クラスターの HSM に対するHTTPS同様の計算の一部をオフロードできる。ウェブサーバーの計算負荷が軽減され、サーバーのプライベートキーを HSM に保存するとセキュリティが強化される。このプロセスは、SSL アクセラレーションとも呼ぶ。
・ウェブサーバーとそのクライアント (ウェブブラウザ) では、SSL または TLS を使用できる。
※一般的に HTTPS として知られており、パブリック/プライベートのキーペアと SSL/TLS パブリックキー証明書を使用して、各クライアントとのHTTPS セッションを確立するため、このプロセスは、ウェブサーバーにとって多くの計算を伴う。
Secrets Manager

【認証情報管理】
データベース認証情報、アプリケーション認証情報、OAuth トークン、API キー、およびその他のシークレットを安全に暗号化し、アクセス管理情報を一元的に監査する。それらシークレット情報を、Secrets ManagerへのAPIコールに置き換えて取得できる。各サーバからAPIを叩くことでシークレット情報を取得でき、認証やサーバセットアップに利用できる。(アプリケーションにシークレット情報を保存する必要がなくなる)
AWS のサービスの多くは、Secrets Manager にシークレットを保存して使用される。
※アプリケーションにシークレット情報を保存する必要がなくなる。
・ライフサイクルを通じて「管理」、「取得」、「ローテーション(Rotation Schedule)」することができる。
シークレット
パスワード、ユーザーネーム、APIトークン、データベース認証、パスワードなどの一連の認証情報、OAuth トークン、または、暗号化された形式。
[参考サイト]
[アクセス]
・きめ細かい IAM とリソースベースのポリシーを使用して、シークレットへのアクセスを管理する。
・各シークレット情報は各サーバーからAPIを叩くことでシークレット情報を取得でき、認証やサーバセットアップに利用できる
・シークレットはデフォルトで KMS によって暗号化されるが、この暗号化キーの管理はAWSが行う。
[シークレットのローテーション]
(Rotation Schedule リソース)
暗号化された安全なストレージを提供され、シークレット、データベースまたはサービスの認証情報が更新する。定期的なキーローテーションスケジュールを設定できる。
※長期のシークレットを短期のシークレットに置き換えることが可能となり、侵害されるリスクを大幅に減少させることができる。
以下の2つの方式がある。
- マネージドローテーション
・ほとんどのマネージドシークレットで利用される。
・サービス側がローテーションを設定・管理するため、Lambda関数は不要。 - Lambda関数によるローテーション
・その他のタイプのシークレットで使用される。
・ユーザーが用意したLambda関数を使って、シークレットと関連サービス(データベースなど)の認証情報を更新する。
リソースタイプ
Secrets ManagerにはCloudFormationテンプレートの一部として作成できるリソースタイプが複数ある。
| AWS::SecretsManager::Secret | シークレットを作成し、Secrets Manager に保存。パスワードは、ユーザーが指定するか、Secrets Manager に生成できる。空のシークレットを作成し、後でパラメータ SecretString を更新もできる。 |
| AWS::SecretsManager::ResourcePolicy | リソースベースのポリシーを作成し、指定されたシークレットにアタッチ。リソースベースのポリシーは、シークレットに対してアクションを実行できるユーザーを制御する。 |
| AWS::SecretsManager::RotationSchedule | 指定した Lambda ローテーション関数を使用して、定期的な自動ローテーションを実行するようにシークレットを設定する。 |
| AWS::SecretsManager::SecretTargetAttachment | シークレットを作成後、サービスまたはデータベースの作成時にそれを参照して認証情報にアクセスすると、このリソースタイプはシークレットに戻ってその設定を完了する。Secrets Manager は、ローテーションが機能するために必要なサービスまたはデータベースの詳細をシークレットに設定する。 |
S3 の暗号化
デフォルトで暗号化が有効化。HTTPSを使用してデータをS3にプッシュして転送中に暗号化できる。
・転送時:S3との間でデータを送受信するとき。
・保管時:S3データセンター内のディスクに格納されている時。
・HTTP 503 レスポンスとは「サービスが利用できない」ときに表示されるエラー
・Secure File Transfer Protocol (SFTP) を使用して ファイルを直接転送することができる
[暗号化する場所]
- クライアント側
クライアント側でデータを暗号化し、暗号化したデータをS3にアップロードする。
この場合、暗号化プロセス、暗号化キー、関連ツールはユーザ管理。 - サーバー側
送信先で暗号化を実施する方法。暗号化キーによって管理方法が変わる。
オブジェクトをデータセンター内のディスクに保存する前にオブジェクトレベルで暗号化。アクセスするときに復号するようにS3にリクエストする。
[暗号化の種類]
| SSE-S3 S3で管理された 暗号化キー | S3が暗号化キーの生成・管理・保管を行う。そのため、暗号化キーの変更、管理を行えない。 ・各オブジェクトは、強力な多要素暗号化機能を備えた一意のキーで暗号化される。 ・キー自体が定期的に更新されるマスターキーによって暗号化される。 ・256ビットの高度暗号化規格(AES-256)を使用してデータを暗号化。 |
| SSE-KMS KMSで管理された 暗号化キー | AWS KMSが暗号化キーの生成・管理・保管を行う。追加の料金がかかる。 ・任意のキーを用いて暗号化できる ・キー自体へのアクセス制御によって、暗号化・復号化できるユーザーを制御できる ・いつ、だれによってキーが使用されたか、ClouodTrailから監査証跡が提供される。 ・エンベロープキー(データの暗号化を保護するキー)オブジェクトの不正アクセスに対する追加の保護を提供する。 |
| SSE-C ユーザー側で用意した暗号化キー | ユーザー自身が暗号化キーの生成・管理・保管を行う。S3に送信する前にデータが暗号化される。 ・どのキーでどのオブジェクトが暗号化されたのかという情報は自分自身で管理。 ・暗号化・復号化に伴う料金は発生しない ・任意のキーを用いて暗号化することができる ・AES-256暗号化タイプを使用 ・HTTPSだけサポートしている ・キーの管理全般はユーザーであるため、セキュリティ面が弱い。 |
[比較表]
「AWS S3でサーバー側暗号化をしたい」というニーズに応えつつ、セキュリティ運用の方針に合わせて選べるようになっている。「AWSにキー管理を任せて利便性やセキュリティレベルを高めたい企業」はSSE-KMS。
「AWSにキーを預けたくない」「極限まで自分で管理したい」というセキュリティポリシーが厳格な組織やプロジェクトではSSE-C。一番簡単に使える暗号化方式で、「保存時に暗号化されればOK」という基本的なセキュリティ要件にはSSE-S3。クライアント側暗号化はAWS外で処理を完結したい場合に有効。
たとえば、
- 金融や医療分野などで「クラウドでも鍵は一切預けない」といった方針があるならSSE-C。
- 監査対応やIAM連携を重視する企業であればSSE-KMS。
| 観点 | SSE-S3 | SSE-KMS | SSE-C | クライアント側暗号化 |
|---|---|---|---|---|
| キー管理 | AWSが自動的に管理(AES-256) | AWS KMSで管理されたキー | 顧客が自分で管理・提供 | 顧客がローカルで暗号化・管理 |
| 利便性 | 高い:設定だけで利用可能 | 高め:KMS連携の設定が必要 | 低め:毎回キー提供が必要 | 低め:全て手動で管理する必要あり |
| 監査・制御 | CloudTrail対象外 | CloudTrail対応・IAM制御可能 | CloudTrail対象外・制御困難 | 自前で監査ログを準備する必要あり |
| コスト | 無料 | KMS利用料が発生 | 無料(但し運用負荷高) | 暗号化ツールの導入コストあり |
| セキュリティ水準 | 基本的な保護(AES-256) | より強力・柔軟な制御 | 顧客が鍵を持つため強力 | 最も厳密な管理が可能(自己責任) |
| 代表用途 | 一般的な暗号化要件を満たす用途 | 企業・監査向け用途 | 金融・法務など高セキュリティ用途 | 機密性重視の組織や独自運用環境 |
分析サービス

基礎知識
●ETL
(Extract(抽出)Transform(変換)Load(格納))
社内に点在する情報(データ)を必要な情報(データ)のみ1箇所に集約し蓄積し、経営に役立つ洞察を得るために利用する。
※これまでは情報を蓄積させるにも異なるデータソースであったため、各開発工数と専門知識が求められた
[RPAとの違い]
RPAツール:既存のアプリケーションの利用を前提とする。
ETLツール:ツールを利用してデータの収集や加工を行う。
| サブセット | 一部分、部分集合、下位集合などの意味を持つ英単語。ある集団全体を構成する要素の一部を取り出して構成した小集団のこと。ITの分野では、仕様や規格、データ集合、ソフトウェアの機能などについてよく用いられる用語。本来備えている要素の一部を省略・削除した簡易版、限定版、軽量版という意味で用いられることが多い。 |
| ヒューリスティック | 必ず正しい答えを導けるわけではないが、ある程度のレベルで正解に近い解答を得ることができる方法。答えの精度が保証されない代わりに、回答に至るまでの時間が少ない。 |
| データパーティショニング | スキャンされるデータ量が最小限に抑えられ、パフォーマンスが最適かされ、S3での分析クエリのコストが削減される。データへのきめ細かいアクセスも向上。 |
●Fluent Bit
・Kubernetes対応:DaemonSetとして簡単にデプロイ可能。PodやNodeのログ収集に最適
・用途:ログの収集、処理、転送(ログルーターとして機能)
・軽量設計:C言語で実装されており、メモリ使用量が非常に少ない(数MB程度)
・対応フォーマット:JSON、CSV、Apache/Nginxログなど、さまざまな形式に対応
・出力先:Amazon S3、CloudWatch Logs、Elasticsearch、Kafka、Splunk、Datadog など多数
| 機能 | 説明 |
|---|---|
| Input Plugins | ログの取得元(ファイル、systemd、TCP、Kubernetesなど)を指定可能 |
| Filter Plugins | ログの加工(タグ付け、除外、JSON変換、Grepなど) |
| Output Plugins | 転送先の指定(S3、CloudWatch、Elasticsearchなど) |
| パフォーマンス | 高速処理と低リソース消費で、IoTやエッジ環境にも適している |
Quick Sight

【ダッシュボード】
クラウド内のデータに接続し、さまざまなソースのデータを結合し、AWSで簡単に分析環境を作ることができるBIサービス。単一のデータダッシュボードに AWS データ、サードパーティーデータ、ビッグデータ、スプレッドシートデータ、SaaS データ、B2B データなどを含めることができる。
※CloudWatchLogsを直接データソースとして利用できない
[参考]
Open Search Service

【ログ等高速検索】
Elasticsearch から派生したオープンソースの分散検索および分析スイート。リアルタイムのアプリケーションモニタリング、ログ分析、ウェブサイト検索などの幅広いユースケースにご利用できる完全なオープンソースの検索および分析エンジン。統合された視覚化ツールである OpenSearch ダッシュボードを使用して、大量のデータへの高速アクセスと応答を提供するための高度にスケーラブルなシステムを提供する。これにより、ユーザーはデータを簡単に探索できる。
Apache Lucene 検索ライブラリを搭載しており、KNN 検索、SQL、異常検出、機械学習コモンズ、トレース分析、フルテキスト検索など、多くの検索および分析機能をサポートしている。ドキュメントやメッセージ、ログ等の様々なデータソースに対してDashboards Query Language(DQL)を使用することでデータの分析や可視化ができるサービス。
※Cloud Frontのログの格納先にOpenSearchドメインを使用することはできない
※本サービスを停止することはできない
[Kibanaへのアクセス制御]
以下設計により、認証とIP制御の柔軟な組み合わせで、Kibanaのセキュリティを強化することが可能。
[認証と保護の方法]
| Amazon Cognito認証(Elasticsearch 5.1以降) | Kibanaにユーザー名とパスワードによるアクセス制限を設定可能。オプション機能。 |
| IPベースのアクセスポリシー + プロキシの利用 | Cognito認証を使用しない場合でも、IP制御とプロキシを使ってアクセス制御が可能。 |
[JavaScriptとアクセス制御の考慮点]
多数のIPをホワイトリストに登録するのは非効率なため、プロキシのIPアドレスからのみアクセス許可する方法が提案されている。KibanaはJavaScriptアプリのため、アクセス元IPは「ユーザーのIP」となり、IPベースの制御が難しくなる。
Compute Optimizer

【リソース評価・分析】
AWS「リソース設定」と「使用率」のメトリクスを分析。機械学習を使って過去の使用率メトリクスを分析することでリソースが最適かどうかを報告し、コスト削減し、パフォーマンスを向上させる。コストを削減しつつパフォーマンスを向上させるための最適化に関する推奨事項を生成する。(EC2、EBS、ECS、Lambdaを対象)
[グラフ機能]
最近の使用率メトリクスの履歴データと、レコメンデーションの予測使用率を示す。最適なコストパフォーマンスのトレードオフとなるレコメンデーションを評価できる。実行中のリソースを移動またはサイズ変更するタイミングを決定し、パフォーマンスとキャパシティーの要件を満たすのに役立つ。
Kinesis

【プラットフォーム】
AWSでデータをストリーミングするためのプラットフォーム。受信するとすぐに処理,分析を行うため、すべてのデータを収集するのを待たずに処理を開始して直ちに応答する。複数のソースから高頻度でストリーミングデータをリアルタイムで収集、処理、分析することが簡単になるため、インサイト(見通し)を適時に取得して新しい情報に低レイテンシーに対応できる。また、特殊なニーズに合わせてカスタムストリーミングデータアプリケーションを構築する。
●ストリーミングデータ
数千ものデータソースによって継続的に生成されるデータ。
[ユースケース]
動画分析、一括からリアルタイムへの移行、動画分析アプリ、リアルタイムアプリなど
Kinesis Data Streams

【シャードの集合体】
次々と送られる大量のデータをリアルタイムに加工、収集、次のサービスに配送するためのサービス。データを中長期保存することを目的としない。そのため、レコードが追加されてからアクセスできなくなるまでの保持期間(Default:24h)がある。(DynamoDBにデータ保存はできない)
仕組み
一連のデータレコードを持つ「シャード」のセット。各シャードのデータレコードには、Kinesis Data Streams によってシーケンス番号(順序)があるため、メッセージが失われず、重複されず、到着と同じ順序で伝送することが可能。サーバー側での暗号化をサポートする。特定の場所に転送することはできない。
(処理速度を向上させるものではない、スループット(処理量)を増加させるもの)
・デフォルトのデータ保持期間は24時間。この期間は、最大で8760時間(365日)まで延長できる。保持期間を延長すると、追加料金が発生する。
⇒データバッファリングや一括処理には不向き
| シャード | Kinesis Datastream内のデータレコードのシーケンス。シャードの増減によってデータの転送速度を変動できる。各シャードには、一連のデータレコードが含まれる。 [参考] 【1つのシャードあたり…】 ・取り込み:1秒あたり最大 2MB のデータ ・書込み:1秒あたり 1,000 レコード ・ストリーム:1秒あたり最大10ギガバイト [引用元公式サイト] |
| データレコード | Kinesis data stream に保存されたデータの単位。シーケンス番号、パーティションキー、データ BLOB (イミュータブルなバイトシーケンス) で構成される。各データレコードには、シャード内のパーティションキーごとに一意のシーケンス番号が割り当てられる。 ※BLOB 内のデータが検査、解釈、変更されることは一切ない |
構成
●プロデューサー(データ送信側)
データレコードを Kinesis Data Streamsに送信する。たとえば、Kinesis data stream にログデータを送信するウェブサーバーはプロデューサー。コンシューマーは、ストリームのデータレコードを処理する。
●コンシューマー(データ処理側)
Kinesis Data Streams からレコードを取得して処理する。これらのコンシューマーは Kinesis Data Streams Application と呼ばれる。S3、Redshift、Splunk などのサービスに直接ストリームレコードを送信する場合は、 Kinesis Data Firehose 配信ストリームを使用できる。
[拡張ファンアウト]
コンシューマーは、シャードあたり 1 秒間に最大 2 MB のデータのスループットで、ストリームからレコードを受け取ることができる。これにより、コンシューマーはスループット性能を向上させることができる。
●Kinesis Client Library(KCL)
Kinesis Data Streamからレコードを取得して、レコードプロセッサ と呼ばれるレコードを処理するためのハンドラをアプリケーション。EC2などの上で常駐させる。アプリケーションの開発者はこの レコードプロセッサ に処理を実装するだけで良く、レコードの取得、どのレコードまで処理したかの状態、Kinesisストリームのシャード増減を自動的に管理してくれる。
●Kinesis Producer Library(KPL)
Kinesis Data Streamsが提供するライブラリ。データストリームへの書き込みプロセスを簡素化する。 バッチ処理、集約、自動再試行などの機能を提供し、データ取り込みの効率性と信頼性を向上させる。
[データ処理によって、複数回のレコードが送信される理由]
Kinsis系のサービスではストリーミング処理を失敗した場合に、プロデューサーが断続的に再起動され複数回送信されてしまう場合がある。重複させないために主キーをレコード内に埋め込み、それぞれのレコードをユニークにする(同じものの存在を1つしか許さない状態)必要。下記2点についてはアプリケーション側で設計時に複数回送信されることを想定される。
- プロデューサーの再試行
- コンシューマーの再試行
連携サービス
| Lambda | Lambda 関数を使用すると、Kinesis DataStreams のレコードを高速処理できる。Kinesis データストリームは、シャードのセット。Lambda 関数を共有スループットコンシューマー (標準イテレーター) にマップすることも、拡張ファンアウトを使用する専用スループットコンシューマーにマップすることもできる。 |
| Application Auto Scaling | Application Auto Scalingを利用することでKinesis Data Stream に対してシャードを自動的に追加・削除する。スケーリングポリシーを定義を利用することでKinesis Data Stream に対してシャードを自動的に追加・削除するスケーリングポリシーを定義する。 |
Kinesis Data Firehose

完全マネージド型サービス(ゼロ管理)。設定を行うだけで、次々と送られる大量のデータをRedShiftやS3に流し込むサービス。分析用途であり、大量のデータを効率よく格納する圧縮技術やいかにセキュアにデータを保持するかに向いている。アプリケーションの構築なしに設定を行うだけでS3、Redshift,Elastic searchに自動的にデータを収穫・格納できる。
※データのリアルタイム分析を直接実行する機能はない
・Lambda関数と統合されており、Lambda関数によるELT処理を連携することでデータ変換しつつ配信処理を実行できる。
●サブスクライバー
Marketplaceで提供されているソフトウェアやサービスを契約して利用しているユーザー。
機能概要
| 動的パーティショニング | データ内のキーを使用して、Kinesis Data Firehose でストリーミングデータを継続的にパーティショニングし、これらのキーでグループ化されたデータを対応する S3 プレフィックスに配信できる。これにより、Athena , EMR ,Redshift Spectrum などのさまざまなサービスを使用して、S3のストリーミングデータに対して高機能でコスト効率の高い分析を簡単に実行できる。 |
| ゼロバッファリング | ほぼリアルタイムでデータを配信できるオプション。従来の Firehose は、データを一定時間(最小60秒)バッファリングしてから S3 や Redshift などに配信していたが、バッファ時間を0秒(0〜900秒 の範囲)に設定可能となり、数秒以内にデータを配信できる。 (リアルタイム性が求められるユースケースに最適) ・追加処理(変換など)がない場合、5秒以内に配信できる ・Lambda変換にもゼロバッファリング対応 |
Kinesis Video Streams

【動画処理】
動画を処理する。
Kinesis Data Analytics
【分析】収集したデータを可視化・分析。
リアルタイムのストリーミングデータの分析や処理、保存を行う。
Managed Grafana

【Grafana専用】
複数のソースからの運用メトリクス、ログ、トレースを即座に照会、関連付け、視覚化する。
拡張可能なデータサポートに対して定評があり、広く展開されているデータ視覚化ツールである Grafana を簡単に展開、運用、スケールできる。
| ★Grafana(グラファナ)とは 分析およびインタラクティブな視覚化を可能にする、マルチプラットフォームで動作するオープンソースのWebアプリケーション |
ワークスペースと呼ばれる論理的に分離された Grafana サーバーを作成する。
シングルサインオン、データアクセスコントロール、監査レポートなど、コーポレートガバナンス要件に準拠するためのセキュリティ機能が組み込まれている。
MSK

【Apache Kafka専用】※MSK:Managed Streaming for Apache Kafka
Apache Kafkaをベースにした完全マネージドのストリーミングサービス。
| ★Apache Kafka オープンソースの分散ストリーム処理プラットフォームで、リアルタイムのストリームデータを扱うためのツール |
・可用性が高く、クラスターは最新の状態に保たれる。
・拡張性が高く、必要に応じて規模を換えることができる。
・Apache Kafka クラスターを複数のアベイラビリティーゾーン (AZ) に分散して提供する。
・既存アプリケーションで処理しているメッセージング機能をクラウドにすばやく簡単に移したい場合に最適。
| Broker(ブローカー) | Kafkaクラスタを構成するサーバーのこと。 |
| Topic(トピック) | メッセージを格納するための論理的な単位。データはTopicに分類される。 |
| Producer(プロデューサ) | Kafkaにメッセージを送信するアプリケーション。 |
| Consumer(コンシューマ) | Kafkaからメッセージを取得するアプリケーション。 |
[引用元]
[処理手順]
★以下を処理実行する
1:サーバーのプロビジョニング
2:Apache Kafka クラスターの設定
3:障害時のサーバーの交換
4:サーバーのパッチとアップグレードのオーケストレート
5:高可用性のためのクラスターの構築
6:データの永続的な保存とセキュリティの確保
7:モニタリングとアラームの設定
8:負荷変動をサポートするためのスケーリングの実行
MSF

【Apache Flink専用】※Managed Service for Apache Flink
Apache Flink を使用してストリーミングデータをリアルタイムで変換および分析し、アプリケーションを他の AWS サービスと統合できる。管理するサーバーやクラスターはなく、コンピューティングやストレージのインフラストラクチャをセットアップする必要もない。
・複雑なストリーム処理に適している。
●RANDOM CUT FOREST
データストリーム内の異常を検出する。
分析サポートサービス
Glue

【データ変換】
サーバレス型分析サービス。データ管理と変換する機能。データの加工などを行う、ETL(抽出・変換・格納)サービスであり、主にデータを分析する前に使うサービス。 データソースのデータを探索し、メタデータとして管理する。
[組み込み変換]
データを処理するために使用できる一式の組み込み変換を用意。これらの変換はETLスクリプトから呼び出すことができる。データは変換から変換へとDynamicFrameと呼ばれるデータ構造で渡される。
| Data Catalog | メタデータを格納するデータストア(=メタデータストア)。データベースやテーブルといった構造で保管する。S3 などのデータソースに保存されている構造化データ、または半構造化データの集まりをメタデータとして管理する。データカタログには、データベース、テーブル、スキーマといった構成を持ち、コネクション、クローラー、分類子といったメタデータを抽出するための機能がある。 |
| Crawler | データソースへの接続、データスキーマの推測、データカタログでメタデータテーブル定義の作成を行うプログラム |
| ETL Job | ソースからデータの抽出、Apache Spark スクリプトを使用して変換、ターゲットにロードするビジネスロジック |
[公式参考サイト]
Dynamic Frame
AWS Glue専用のデータ構造。SparkのDataFrameと似ていますが、1つのカラム(列)に複数の異なるデータ型を混在させられるという高い柔軟性が最大の特徴。
[主な機能と特徴]
生データの複雑なETL処理を簡単にするために設計されています。複数のデータ型候補を「Choice型」として保持し、後の処理で型を決定できます。SparkのDataFrameと相互に変換可能。一般的に、データの読み書きはDynamicFrameで行い、途中の複雑なデータ変換はDataFrameに変換して行うことが多い。
[構造]
DynamicFrameがデータ全体(テーブル)を表し、その中の1行のデータをDynamicRecordと呼ぶ。
Glue Find Matches
機械学習を使って類似レコードを検出する機能。特に、完全一致しないデータ(名前のスペル違いや住所の表記揺れなど)でも、同一人物や同一商品などを見つけたいときに活躍する。
[特徴]
・主キーや完全一致がなくても類似レコードを検出可能
・ラベル付きデータを使って機械学習モデルをトレーニング
・match_id列を付与して、同一グループのレコードを識別
・重複排除やインクリメンタルマッチングにも対応
Lake Formation

データレイクの構築・管理・アクセス制御を簡素化するマネージドサービス。S3 上のデータに対して詳細なアクセス制御が簡単に設定できる。構造化・非構造化データを一元管理できる。
- アクセス制御を強化:IAM とは別の独自の権限モデルで、列・行・セルレベルまで細かく制御
- セキュリティとガバナンスの向上:企業全体でのデータ共有と制限を両立
- Lake Formation タグ を使ってデータを分類・ラベル付けし、リソースアクセスをキャンペーン単位などで制限可能。
- AWS Glue Data Catalog や Amazon Athena と連携し、統合的なメタデータ管理やアクセス制御を実現。
[主な機能と構成要素]
| コンポーネント | 説明 |
|---|---|
| データカタログ | Glue と共有するメタデータ管理機構。S3 上のデータをテーブルとして定義 |
| アクセス制御 | LFタグ方式(タグベース)とリソース方式(個別付与)の2種類 |
| ブループリント | データ取り込みのテンプレート。Glue のクローラーやジョブを自動生成 |
| ワークフロー | データ取り込みや変換処理の流れを定義。Glue のトリガーと連携 |
| プリンシパル | IAMユーザーやロールに対応。Lake Formation 独自の管理者権限も存在 |
LF-TBAC
[Lake Formation のタグベースアクセス制御 (LF-TBAC)]
- LF-TBAC は、属性(タグ)に基づいて許可を定義する仕組み。
- LF タグは Data Catalog リソース、Lake Formation プリンシパル、テーブル列などに付与可能。
- プリンシパルのタグがリソースタグと一致したときに操作を許可する。
- 急成長する環境やポリシー管理が複雑な状況で有効。
- IAM の属性ベースアクセス制御 (ABAC) と連動し、細粒度アクセスを提供。
[メリット]
・名前付きリソース方式よりも柔軟で効率的。
・リソースが多数あってもスケーラブルに管理可能。
ADOT

※AWS Distro for OpenTelemetry
AWSが公式に提供する OpenTelemetry のディストリビューションで、クラウドネイティブな監視とトレーシングを簡単に実現するためのツールセット。
| 項目 | 内容 |
|---|---|
| 目的 | アプリケーションのメトリクス、ログ、トレースを収集・送信するための統合ソリューション |
| ベース技術 | CNCF(Cloud Native Computing Foundation)プロジェクトの OpenTelemetry |
| 特徴 | AWSサービスとの統合が強力(X-Ray、CloudWatch、ECS、Lambda など) |
| コンポーネント | OpenTelemetry Collector(AWS対応版)、SDK(Java, Python, Go など) |
[メリット]
・AWSリソースのメタデータ取得:アプリケーションとインフラの関連付けが可能で、トラブルシューティングが高速化
・一度の計装で複数サービスに送信:X-RayやCloudWatchなど、複数の監視ツールに同時にデータを送れる
・サイドカーやエージェントとして柔軟にデプロイ可能:ECS FargateやEC2、Lambdaなどに対応
キューイングサービス
ストリーム処理をかけるデータはキューイングサービスを通すことが一般的である。
SQS

(Simple Queue Service)
キュー内の(複数の)ワーカープロセスでメッセージを処理し、確実な非同期(分散並行)処理を行う。キューの有効期限が切れるまで繰り返し処理する。
| プロデューサ | キューにメッセージを入れる、取り出すサービス。 |
| エンドポイント | URLを介して送受信する。 |
キュー
メッセージを管理する入れ物のようなもの(256KB限度)デフォルトは4日間保存する。キューは手動で削除することが可能。
| スタンダードキュー | 順番は保証されない。一回のメッセージ配信をサポートする。 ・シーケンス情報 追加することで、順序良く受信させることができる。(スタンダードキュー可能) |
| 先入れ先出し(FIFOキュー) | 利用料金は高め。受信時にメッセージの並び替え、最低1回のメッセージ配信をサポートする。 ・S3との連携はできない ・1秒あたり最大3,000トランザクション ・1秒あたり最大300メッセージをサポートする [キューの切り替え] FIFOキューに切り替えるなどする際は、新しくキューを作成する必要がある。 ※FIFOキューは「コンテンツベース重複排除」を有効化することで、データを一意にできる |
その他機能
| キューイング (待ち行列) | 【一時退避】一時的に送信するデータをデータ領域に保持し、滞留させず確実に相手へ届ける。疎結合が可能。 |
| デッドレターキュー (DLQ) | 【失敗処理】処理できないメッセージを別のキューに移動させる。正常に処理 (消費) できないメッセージのターゲットとする。アプリケーションやメッセージングシステムのデバッグに役立つ。 |
| 遅延キュー | 【受信遅延】キューへの新しいメッセージの配信を数秒間遅延させ、そのキューに送信したすべてのメッセージは遅延期間中にコンシューマーに表示されない。キューのデフォルト (最小) 遅延は 0 秒。最大値は15分。 |
メッセージ
キューの中に格納される情報。
●メッセージグループ ID
【メッセージのタグ付け】
メッセージが特定のメッセージグループに属することを指定するタグ。 同じメッセージグループに属するメッセージは、そのメッセージグループに関連して厳密な順序で 1つずつ処理される。
●可視性タイムアウト
【重複受信防止】
メッセージの受信中に他クライアントが受信しないように防止する(30秒~12時間まで延長可能)。メッセージは受信しただけでは消えず、クライアント側から削除指示を受けた時のみ削除される。
- ChangeMessageVisibility
新しいタイムアウト値を指定すると、メッセージの可視性を短縮または拡張できる。 - VisibilityTimeout
メッセージが1回受信された後、他のクライアントから同じメッセージを受信不可にするための時間。
(デフォルトは30秒. 値は0〜43,200(12時間) の間で設定可能) - ReceiveMessage
リクエストによってメッセージを取得。
●SQS Java 拡張クライアントライブラリ
【メッセージの保存管理】
メッセージを常に S3 に保存するか、メッセージのサイズが 256 KB を超える場合のみ保存するかを指定する。
・S3 バケットに保存されている単一のメッセージオブジェクトを参照するメッセージを送信する
・S3 バケットからメッセージオブジェクトを取得 / 削除する
ポーリング
複数のキューを呼び出して分散してメッセージを処理する。ただし、1つのキューにすべてのメッセージが入っているわけではない。
キューの中の先頭のデータが渡されるため、中の特定のメッセージを指定できない。
[参考]
| ショートポーリング | メッセージ取得時に特定のキューをランダムに選択し、そのキューからメッセージを取得する。リクエストを投げると結果は直ぐに返ってくるため、メッセージ取得時の待機時間0秒。しかし、結果が0件だった場合はリトライされるため、リクエスト回数が増え、料金が増加する。 |
| ロングポーリング (推奨) | すべてのキューを確認し、処理可能な(待機時間を超過した)メッセージが存在する場合と接続タイムアウトになった場合のみ結果を返す。結果が0件の場合は返答しないため、SQS使用時のコストを削減できるので、ショートポーリングよりも推奨される。 ※ReceiveMessageAPI アクションが 0 より大きい場合ロングポーリングは実行中 ・KMSを使用したサーバー側の暗号化を使用したシームレスな保存データの暗号化をサポート。一元化されたキー管理が可能になる。 |
メトリクス
[参考公式サイト]
[AWS SQSで利用可能なCloudWatchメトリクス]
| メトリクス名 | 説明 |
| ApproximateNumberOfMessagesVisible | キュー内で現在可視状態にある(取得可能な)未処理メッセージの数。消費対象としてすぐに取得可能。 |
| ApproximateNumberOfMessagesDelayed | 遅延状態にあるメッセージの数。DelaySecondsが設定されており、まだ可視でないもの。 |
| ApproximateNumberOfMessages(属性) | CloudWatchメトリクスではなく、SQSキュー属性。Visible、Delayed、NotVisibleをまとめた情報をAPIで取得可能。 |
MQ

【Apache用】
Apache ActiveMQ および RabbitMQ 用マネージド型のメッセージキューイングサービス。AWS独自の方法ではなく業界標準APIやメッセージング用プロトコルを使ってるため、今までのアプリから接続先をMQに変えるだけで簡単に移行できる。リージョン内の複数のAZにメッセージを冗長的に保存するため、耐障害性が高い。
・ソフトウェアをインストールして管理したりする必要はない。
・ソフトウェアのアップグレードやセキュリティの更新、障害の検出と回復などのタスクを自動的に管理する。
●メッセージブローカー
【中間システム】
異なるシステム間でメッセージやり取りの時、直接データのやり取りせず、中間システムとしてメッセージ格納領域を管理する機能。
その他関連サービス機能
IAM Access Analyzer
【意図せぬ公開】
外部エンティティ(別のAWSアカウントのエンティティ)と共有されているS3バケットやIAMロールなどが、セキュリティ上のリスクであるリソースとデータへの不適切なアクセスがないかを特定する。すなわち、AWSリソースに紐付いているポリシーを検査し、他AWSアカウントや外部のインターネット等からのアクセスを可能とするような意図せぬ公開設定がされているか確認する機能。
・ユーザーアクセスと最後にアクセスした情報に関する詳細なレポートを作成できる。
●S3 Access Analyzer
IAM Access Analyzeに基づいて現在のS3へのアクセスポリシーを監視できるサービス。
※IAM Access AnalyzeのS3用みたいなもの
バケットアクセスポリシーがS3リソースへの意図したアクセスのみを提供するように意図しないアクセスの可能性があるバケットを検出して迅速に修正できるようにする。また、S3バケットに対する外部アカウントからのアクセス情報を分析して、不正なアカウントアクセスがないかを確認することができる。
S3に関する分析機能
S3 Select

単純なSQL式を使用してS3バケット内のオブジェクト内のデータのサブセットを取得し、より迅速かつ安価に分析および処理できる。
[S3インベントリをフィルタリング]
S3インベントリ内のレポートをフィルタリングして、暗号化されていないオブジェクトなどを検索できる。
[データの解析には不向き]
シンプルなSQLステートメントを使用してS3オブジェクトのコンテンツをフィルタリングし、必要なデータのサブセットのみを取得できる。結果として、S3が転送するデータ量を削減でき、データ取得に要するコストを削減し、待ち時間を改善できる。
・アーカイブ容量の最大は250MB未満
※簡単なデータ検索や抽出に利用される機能であるため、本件の高度なビッグデータ分析には利用できない。
Athena

標準のSQL式を使用して、S3 内のデータを標準 SQL を使用して簡単に(アドホックなSQL)分析できるクエリサービス。サーバーレスなため、インフラストラクチャの管理は不要。S3のデータをポイントし、スキーマを定義し、標準のSQL式を使用してクエリを開始するだけ。S3上にログ等のデータを保管しており、それを分析用途に簡単に利用したい、新しく取得したデータに対してDWHに入れるべきかを検証する場合に利用が適する。
[課金について]
実行したクエリに対してのみ料金が発生する。
●CTAS (CREATE TABLE AS SELECT) コマンド
あるクエリの実行結果から新しいテーブルを作成できる。作成されたデータファイルは、指定したS3の場所に保存されます。S3上のデータをクエリしやすい形式(例: Parquet形式やパーティション化された形式)に変換・最適化し、分析パフォーマンスを向上させるための強力な機能。
[パーティション化]
機械学習を使って類似レコードを検出する機能。特に、完全一致しないデータ(名前のスペル違いや住所の表記揺れなど)でも、同一人物や同一商品などを見つけたいときに活躍。時系列データを日付プレフィックスでパーティション化することでクエリ効率を大幅に向上させることができる。
[特徴]
・主キーや完全一致がなくても類似レコードを検出可能
・ラベル付きデータを使って機械学習モデルをトレーニング
・match_id列を付与して、同一グループのレコードを識別
・重複排除やインクリメンタルマッチングにも対応
S3 分析
【ストレージクラス分析】
ストレージアクセスパターンを分析し、適切なデータをいつ適切なストレージクラスに移行すべきかを判断できる。
アクセス頻度の低い STANDARD ストレージをいつ STANDARD_IA (IA: 小頻度アクセス) ストレージクラスに移行すべきかを判断できるように、データアクセスパターンを確認する。
EMR

【S3を高分析】※Elastic MapReduce
※スポットインスタンスと相性が良い
Apache HadoopやApache Sparkなどのオープンソースツールを利用し、大量のデータを迅速に処理するために分散アプリケーションを実行する。マネージド型 Hadoop フレームワーク。(高速処理ではない)
・GoogleのフレームワークであるMapReduceをベースに実装されている。
・S3にある大量のログファイルを処理して、分析するのに最適なサービス。
・EMRの処理結果をS3をはじめとしたAWSの他のサービスと連携できる。
| 伸縮自在 | EMRのコンピューティングとストレージは分離されているため、スケーリングができる。 |
| 信頼性 | クラウド向けの調整。パフォーマンスの低いインスタンスは自動的に置き換わる。 |
| 安全性 | インスタンスへのアクセスは自動制御、またKMSを使用して暗号化を行うことが可能。 |
| 低コスト | 最小課金時間が1分、そして1秒毎に課金される。 |
仕組み
●Apache Spark
EMRクラスターを使用した機械学習、ストリーム処理、またはグラフ分析に役立つ分散処理フレームワークおよびプログラミングモデル。 Apache Hadoopと同様に、ビックデータのワークロードを処理するために一般的に使用されているオープンソースの分散処理システム。
※イメージ比較
・Redshiftは標準的な Apache Sparkの3倍以上の速さで、ペタバイト規模の分析を実行できる。
●Hadoop
巨大なデータを処理するため、アプリケーションの実行をハードウェアのクラスター上で行うオープンソースのソフトウェアフレームワーク(プラットフォーム)。
- HDFS(Hadoop Distributed File System)
コモディティハードウェア上で実行するように設計された分散ファイルシステム。
・耐障害性を備えており、低コストのハードウェアに導入できるように設計されている。
・アプリケーションデータへの高スループットを提供する。
・Apache Hadoop のファイルシステムデータへのストリーミングアクセスを可能にする。
●Kerberos ベースの認証
EMRクラスターのセキュリティ強化に使用。はじめにIDとパスワードで認証に成功すると、証明のための「チケット」が発行される仕組み。
ノード
| プライマリノード (Primary Node) | ・クラスター全体の管理を担当 ・データ損失が起きるとクラスター全体に影響 ・オンデマンドインスタンスで実行し、高い可用性を確保するのが推奨 |
| コアノード (Core Node) | ・データストレージと分散処理に不可欠な役割を持つ ・データ損失が発生すると復旧困難 ・オンデマンドインスタンスを選択して安定性を担保するのが推奨 |
| タスクノード (Task Node) | ・主に計算負荷の分散処理を担当 ・データストレージには関与しない ・コスト効率を優先して スポットインスタンスを利用可能 ・中断される可能性があるが、タスクノードはその影響を最小限に抑えられる設計 |
●マスターノード
クラスターを制御し、分散アプリケーションのマスターコンポーネントを実行。クラスターにサブミットされたジョブステータスを追跡して、 インスタンスグループの健全性を監視。マスターノードは一つしかなく、インスタンスグループまたはインスタンスフリートは1つの EC2で構成される。
※マスターノードが終了するとクラスターも終了するため、マスターノードは突然終了しても問題が発生しないクラスターを実行している場合にのみ、スポットインスタンスとして起動するようにするとよい。
●コアノード
マスターノードによって管理される。データノードデーモンを実行して、Hadoop Distributed File System(HDFS)の一部を使用して データを格納する。さらにタスクトラッカーデーモンを実行し、インストールされているアプリケーションを要求する。 データ上で、その他の並列計算タスクを実行。マスターノードのように、クラスターあたり最低一つのコアノードが必要。
※コアインスタンスを終了すると、データ損失のリスクがある
●タスクノード
タスクノードはオプション。Hadoop MapReduceタスクやSpark実行プログラムなど、データに対して平行計算タスクを実行するための能力を追加するために使用。データノードデーモン上で実行されることも、HDFSでデータを保存することはない。コアノードと同様に既存のユニフォームインスタンスグループにEC2インスタンスを追加することでクラスターにタスクノードを追加、あるいはタスクインスタンスフリートのターゲット容量を変更することができる。オンデマンドインスタンスなど、異なるインスタンスタイプおよび価格設定オプションを組み合わせることができる。
S3 Storage Lens

オブジェクトストレージおよびアクティビティを組織全体で可視化するために使用できるクラウドストレージ分析機能。メトリクスを分析して、ストレージコストを最適化し、データ保護に関するベストプラクティスを適用するために使用できるコンテキストに応じた推奨事項を提供する。
[(デフォルト)ダッシュボード]
複数のAWSリージョンにわたるS3バケットの監視と、暗号化されたオブジェクトの割合の追跡に適した統合ダッシュボード。
S3コンソールを使用して直接ダッシュボードにアクセスできるため、追加のデータ集約やダッシュボードの作成が不要になる。
[クエリと集計関数の活用]
・stats コマンドを使ってログデータを集計
・特定フィールドの値でグループ化し、件数をカウント
・クエリ結果を棒グラフ・折れ線グラフなどで視覚化可能
[視覚化とパターン分析]
・ログデータの傾向や異常をグラフで把握
・stats と集計関数を組み合わせて、効率的な分析が可能
[クエリ構文の柔軟性]
・正規表現、算術演算、関数などをサポート
・複雑な条件でロググループに対して検索・抽出が可能
Cloud Watch関係
CloudWatch log insight
【Cloud Watchlogの検索】
CloudWatch Logsのログデータに対し、独自の構文を使ってクエリのようにデータを検索したり分析したりすることができる機能。ロググループ内のログデータの分析に特化しており、集計したデータをダッシュボードに表示することができる。
リアルタイムの監視やアラート設定はできない。
●ロググループ
複数のログストリームをまとめた単位。1つのロググループには複数のストリームが含まれ、アプリケーションやサービス単位でのログ管理を可能にする。
[クエリ構文]
専用のクエリ言語を用いてロググループを分析できる。
- 汎用関数:ログ項目の抽出や結合、フィルタリング
- 算術・比較演算:数値演算や大小比較による絞り込み
- 正規表現サポート:文字列パターンのマッチング
- 集計関数:集計、統計情報の生成
- ソート・制限:結果の並び替えや上位N件の取得
CloudWatch Application Insights
【アプリケーションの監視】
他のアプリケーションリソースとともに インスタンスを使用するアプリケーションをモニターリングする。
[アクション実行]
メトリクスとログを継続的にモニターリングし、異常やエラーを検出して相互に関連付ける。エラーや異常が検出されると、Application Insights は CloudWatch Events を生成する。これを使用して、通知を設定したり、アクションを実行したりできる。
[ダッシュボード]
トラブルシューティングに役立てるために、検出した問題の自動ダッシュボードを作成します。このダッシュボードには、相互に関連付けられた異常とログエラー、さらに根本原因を示唆する追加のインサイトが示されます。
CloudWatch Contributor Insights
【高頻度ボトルネック可視化】
CloudWatch Logsから取得した時系列データから上位(高頻度)の要素をリアルタイム分析を簡素できる機能。ログデータから特定の項目の頻度をランキング形式で表示し、トラフィックの傾向や主要な原因を特定するためのサービス。
パフォーマンスのボトルネックや、使用されているリソースなどを一目で確認できるダッシュボードで確認することができる。
CloudWatch Logsにエクスポートしたシステムやアプリケーションログなどからエラーが多いURLを特定したり、VPC Flow Logsで意図しないIPアドレスからのアクセスを特定したりすることができる。
CloudWatch Container Insights
ECS・EKS・EC2 上の Kubernetes クラスタで動作するコンテナ化アプリケーションやマイクロサービスのリソース使用率と稼働状況を収集・可視化する機能。
[主要ポイント]
[対象環境]Amazon ECS、Amazon EKS(EC2 プロビジョニングされたクラスタのみ)、EC2 上の Kubernetes
[収集メトリクス]
・Pod レベルのメモリ使用率(pod_memory_utilization)
・ノードレベルのメモリ使用率(node_memory_utilization)
・サービスレベルのエラー率や CPU 使用率(Service インサイト)
[活用方法と注意点]
・AWS CloudWatch ダッシュボードで Pod/ノード/サービス単位のメトリクスを可視化できる
・サービスインサイトを有効にするには、対象となる Kubernetes サービスにタグ付けが必要
・タグがないとサービスレベルのメトリクス収集が行われない
CloudWatch メトリクスストリーム
- 目的:リアルタイムで CloudWatch メトリクスを外部サービスにストリーミングする機能。
- 用途:監視や可観測性の向上、サードパーティーサービスとの統合に活用。
- 対応先:Amazon S3、Amazon Kinesis Data Firehose、サードパーティープロバイダーなど。
[構成要素]
| 要素 | 説明 |
|---|---|
| データレイク | メトリクスを Amazon S3 に保存して分析可能。Kinesis Data Firehose 経由で S3 に送信。 |
| サードパーティープロバイダー | Datadog や New Relic などの外部サービスに直接ストリーミング可能。 |
Data Exchange

【リソース取得】
公開されている第三者機関のデータをAWSクラウドへ取り込み、分析したり機械学習に活用したりできる。または、手持ちのデータをアップロードして、ユーザーへ配布・共有できる。
[サブスクリプションの検証]
データを共有する前に送り先の身元を確認でき、信頼性の確保を実現する。
データベースサービス

基礎知識
●エビクション
キャッシュが満杯の状態。キャッシュ内に必要なデータを保存し、不要なデータを追い出すこと。
●接続文字列
どのサーバの、どのデータベースに、どのOLEDBプロバイダーで接続するかを指定するための文字列。障害発生時に、再度更新に時間がかかる要素。AWS DLM(EBS)が有効策。
●プロキシフリート
リソースのフリート(集団)を管理しており、DBなどの接続を仲介する(?)
- フリート
一般的に、「集団」、「ものの集合体」を意味する。フリートを使用することによって、マルチクラスタ機能の使用と管理、複数のシステム間での一貫したポリシーの適用が可能。
●変更データキャプチャ(Change Data Capture:CDC)
テーブルの特定のデータソースが追加・削除・更新などの変更情報を追跡することができる。
●RDBMS(Relational DataBase Management System)
SQLを利用して、RDBを管理するためのソフトウェアの総称 下記のソフトウェアを選択して利用できる。(各ソフトウェアを利用したDBを作成可能)
・MySQL(Amazon Auroraと互換性あり)⇒パフォーマンスの向上
・ORACLE
・Microsoft SQL Server , PostgerSQL
・MariaDB
・Amazon Aurora(MySQl,PostgerSQL)
●完全なスナップショット
インスタンスの停止が必要。マルチAZ配置で設置されたDBのスタンバイ側は読み込みをサポートしていない。
[サーバーとセッション情報について]
セッション管理しているサーバーに障害が発生した場合、セッション情報が消える。⇒再度処理しなおす必要がある。➡各サーバーにセッション情報を置かずに、DBを利用して保存する。(セッション情報は消えない)
[NoSQLについて]
「柔軟でスキーマレスなデータモデル」「水平スケーラビリティ」「分散アーキテクチャ」「高速な処理」 RDSやAuroraなどのリレーショナルデータは、サーバレスアーキテクチャとの互換性が低い 小規模データを保存・処理するためにはNoSQLデータベースを利用することが最適。
[「DBインスタンス」という表現]
例として、「RDS」と「DBインスタンス」の違いを記載すると以下になる。
・AWS RDSは、クラウド上でデータベースの管理を簡素化するマネージドサービス全体
・AWS DBインスタンスは、RDSの中で実際に動作する個々のデータベース環境。ユーザーが選択したエンジン(MySQL、PostgreSQLなど)で動作し、設定可能。
つまり、RDSはサービスの枠組みであり、DBインスタンスはそのサービスの中で動作する具体的なデータベース環境ということ。
RDS

(Relational Database Service)
シンプルかつ迅速にスケール、安定したパフォーマンス、低コストを実現可能なデータベース。(停止してから7日間経つと自動的に起動される)。データを複数の表として管理し、それぞれの関係を定義することで、互いの関連性を扱えるデータベース。リードレプリカは最大5台まで。
高速なフェイルオーバー: データベースに障害が発生し、別のデータベースに切り替わっても、プロキシが自動的に接続先を切り替えるため、アプリケーションは再接続する必要がなく、ダウンタイムを最小限に抑えられる。
接続の管理: アプリケーションからの接続をプール(集約)し、データベースへの接続数を削減することで、データベースの負荷を軽減する。
(課金:1秒単位 ※プライマリとスタンバイ間のデータレプリケーションに課金は発生しない)
※RDSのオンデマンドより、リザーブドインスタンスの方が費用対効果が高い
・マルチAZ構成にすると、自動的にフェイルオーバー構成になる
・頻繁にまたは同時に上書きおよび削除するデータに向いている
・複数の同時書き込み操作をサポートし、常に最新のデータが返される
・MySQLのストレージエンジンに【InnoDB】を利用⇒複雑なクエリ、結合処理が可能
・DBインスタンスのバックアップに自動バックアップとスナップショットをAmazon S3に保管する
・DBインスタンス全体の保存期間を35日間に設定できる。破損からデーターベースを守ることができる。
[注意点]
・個別パッチは適用できない
・AutoScaling グループは使用できない
・OSにログインはできない(別途RDBMSの検討が必要)
・ファイルシステムへのアクセスができない(ファイルシステムとの連携がサポートされていない)
・作成した、DBインスタンスのパラメータの変更について➡[動的:インスタンスの再起動不要]、[静的:インスタンスの再起動必要]
・テーブルのパーティションは16TBが限度(ストレージは64TBまで拡張可能)
●リードレプリカ
読み取り専用のDB。アクセス数が多くDBに読み取り負荷が起きている場合など、リードレプリカを構築することでプライマリデータベースへの負荷を分散する。マルチAZ構成との違いは、リードレプリカへのデータ更新は非同期で行われる点。
機能性
●RDS Performance Insights【DB負荷評価】
データベースの負荷を可視化し、負荷を発生させている SQL ステートメントとその理由を簡単に調べられるようにする。RDSのパフォーマンス分析ツール。データベースのワークロードを分析し、ボトルネックや遅延の原因を特定。
・設定もメンテナンスも不要で、現在は Auroraと RDSで利用可能。
・AWS API と SDK を使用すると、Performance Insights をオンプレミスやサードパーティーのモニタリングツールと簡単に統合できる。
[データの保存期間]
無料で 7 日間のパフォーマンス履歴を保存でき、多種多様な問題を簡単に突き止めて解決できる。もっと長い期間の保存が必要なときは、最大 2 年間のパフォーマンス履歴を有料で保存することもできる。
●RDSメンテナンスウィンドウ
週次で設定し、AWSによって行われる、変更やソフトウェアのパッチなどが実行されるタイミングをコントロールできる。アップデートが突然行われると、提供しているサービスがダウンしたりと障害につながるようなことを防ぐ。なお、設定しない場合は、デフォルトのメンテナンスウィンドウを指定される。
[オプション]
| ポイントインタイムリカバリー | 直前5分前から最大35日間までの任意のタイミングの状態のRDSを新規に作成することができる。 |
| バックトラック機能 | 指定した時間(上限は72時間)まで新しいDBクラスターを作成せずに、本番用データベースクラスターを巻き戻すことが可能。新しいDBクラスターを作成しないため、スナップショットからの復元やポイントタイムリカバリと比較すると迅速に復元できる。 |
| 拡張モニタリング有効化 | (Enhanced Monitoring) DBインスタンス上のさまざまなプロセスまたはスレッドがCPUをどのように使用しているかを常時モニタリングする。OSレベルのメトリクスをリアルタイムで提供(CPU,メモリ、ファイルシステム、ディスクI/O、プロセスリストなど) |
| クロスリージョンリードレプリカ | RDS のリージョン間リードレプリカを使用すると、ソース DB インスタンスとは異なるリージョンに MariaDB、MySQL、Oracle、PostgreSQL、または SQL Server のリードレプリカを作成することができる。 ※DR対策に有効 |
| Amazon RDS on Vmware | オンプレミスVMware 環境マネージド型データベースをデプロイできる。RDS同様に下記処理を自動化できる。 ・ハードウェアのプロビジョニング ・データベースのセットアップ ・パッチ適用 ・バックアップなど |
RDS Proxy

【可用性機能】
アプリケーションでデータベース接続をプールおよび共有して、アプリケーションのスケーリング能力を向上させる。「データベース接続のオーバーヘッド削減」、「コネクション管理」を主とする。RDS の前段に配置され、RDSのエンドポイントにプロキシとして接続するサービスでもある。
・アプリケーションがDBへの接続を失ったとしても、再起動することなく接続を再確立できる。
| 交通整備 | 接続プールからアプリケーション接続をすぐに提供できない場合、これらの接続の処理順番を決めたり、スロットリングを行う。 |
| スケーリング | レイテンシー増加時、データベースの障害や過負荷を発生させず、アプリケーションは継続して(RDSインスタンスが)スケーリングされる。 |
| 接続数管理 | 接続リクエスト数が指定した制限を超えると、アプリケーション接続を拒否 (負荷を削除) 。同時に、負荷に対してパフォーマンスを維持する。 |
| 接続プール再利用 | アプリケーションの接続を維持しながらスタンバイインスタンスに自動的に接続することができるように設定されている。これにより、アプリケーションはデータベースへの接続を失った場合でも、再起動することなく接続を再確立できる。 |
| フェイルオーバー | データベース接続プールを確立し、このプール内の接続を再利用することで、毎回新しいデータベース接続を開くことによるメモリと CPU のオーバーヘッドを回避できる。 (※認証情報を処理するオーバーヘッドを減らし、新しい接続ごとに安全な接続を確立できる。この作業の一部をデータベースに代わって処理できる) |
●RDSプロキシエンドポイント
アプリケーションがデータベースに接続する際に使用する、RDSプロキシというサービスの接続先。通常、アプリケーションは直接RDSデータベースに接続しますが、RDSプロキシを使うことで、その間にプロキシが入り、接続管理を効率化できる。
パラメータグループ
データベースに割り当てるメモリなどのリソースの量などの設定方法を指定できる。
※データベース接続時の SSL / TLS 暗号化を強制できる
DB インスタンスとマルチ AZ DB クラスターをパラメータグループに関連付けて、データベースの設定を管理する。
Amazon RDS は、デフォルト設定を使用してパラメータグループを定義する。カスタマイズした設定を使用して独自のパラメータグループを定義できます。
ストレージタイプ
※GBあたりの容量課金を実施
・汎用(SSDタイプ)
・プロビジョンドIOPS(SSDタイプ):汎用よりIOPSが高い
・マグネティック(HDDタイプ):[GBあたりの容量課金を実施]+IOリクエスト課金
暗号化
・SSL/TLSを使用してDBインスタンスへの接続を暗号化する
・保管時のデータリソースを暗号化する
・暗号化オプションの有効化はRDSインスタンス作成時のみ有効。
[作成後の暗号化]
スナップショットをコピー・暗号化し、新しいインスタンスとして復元することで可能。
[接続の暗号化(PostgreSQL)]
Amazon RDS for PostgreSQL ではカスタムパラメータグループを使用することで、データベース接続時のSSL/TLS暗号化を強制でき、通信内容を暗号化することができる。
[その他]
- AES-256暗号化
- AWS KMSによる鍵管理
- リードレプリカも同じ鍵管理を利用
- インスタンス作成時にのみ設定可能
- スナップショットのコピーの暗号化/リストア可能
[ストレージ容量の確認方法]
Webコンソールの「RDS」→「インスタンス」→「モニタリングを表示」で「Free Storage Space(MB)」が表示される。
[Lambda関数を使って、RDSに接続設定]
(Lambdaを利用したサーバーレス構成必須)
Lambda 関数用の Amazon RDS Proxy データベースを作成できる。 データベースプロキシは、データベース接続のプールを管理し、関数からのクエリを中継する。これにより、データベース接続を 使い果たすことなく、関数の同時実行レベルを高くすることができる。
Aurora

(RDSで使用できるデータベースの1つ)
MySQLとPostgreSQLと互換性がある分散型RDB。標準的なMySQL。データベースと比べて最大で 5 倍、標準的な PostgreSQL データベースと比べて最大で 3 倍高速。(※NoSQL非対応)※高頻度の書き込みの不向き
・Auroraリードレプリカは負荷削減として機能すると同時に自動フェールオーバー機能を備えているため、セカンダリデータバーストしても機能する。また、自己修復機能を備えている。
・DBインスタンスを作成すると、DBクラスタ(複数のDBインスタンス)が作成される(データ量:最大64TB)
・作成されたDBインスタンスは3つのAZにわけられる。1AZあたり2箇所、3AZに渡りコピー、つまり2×3=6箇所のストレージにコピーされる
(※3つのAZに6か所のデータをレプリケート)
・DBの冗長化構成(マスターデータベース/リードレプリカ)。スタンバイレプリカで読み取り処理は不可
・データベースインスタンスのトランザクションログを5分ごとにS3に保存している
機能性
●Amazon Aurora AutoScaling
Aurora DB クラスター用にプロビジョニングされる Aurora レプリカのみ (リーダー DB インスタンス) の数を動的に調整する。
・Aurora MySQL と Aurora PostgreSQL の両方で使用できる。
・使用する Aurora DB は急激な接続やワークロードの増加を処理できる。
・クラスターボリュームはDBエンジンのバージョンに応じて、128テビバイト(TiB)または64Tibまで自動的にスケールする
種類
●Aurora Serverless(※AZ規模のDR(Disaster Recovery)向け)
オンデマンドで自動スケーリングするデータベース。アプリケーションの負荷に応じて自動的に起動・(アクセスがなければ)停止し、容量も調整される。必要なときに必要なだけリソースを利用できる。処理負荷が一定ではない、予測困難なワークロードに適している。
・秒単位での従量課金制が採用されており、非アクティブ時はコストが抑えられる。
・セットアップはシンプルで、エンドポイントの作成と容量範囲の指定のみで使用可能。
・標準のAurora設定との切り替えも簡単で、数クリックで移行できる。
[構造]
・DB インスタンスクラスのサイズを指定せずにデータベースエンドポイントを作成して、最小と最大のキャパシティーを設定。
・データベースエンドポイントからプロキシフリートに接続される。(プロキシフリート=インスタンス群のグループ?)このフリート内で、最小と最大のキャパシティー設定に基づいてリソースを自動的にスケールして調整する。
[引用元サイト]
●Aurora Global Database
(※リージョン規模のDR(Disaster Recovery)向け)
複数のAWSリージョンにまたがる単一のAuroraデータベースを使って、グローバルに分散したアプリケーションを実行できる。データのマスターをプライマリリージョンに1つ、読み取り専用(最大5つ)をセカンダリリージョンに構成。書き込み操作は、プライマリAWSリージョンにあるプライマリDBクラスターに直接発行。
データベースのパフォーマンスに影響を与えずにデータをレプリケートし、各リージョンでレイテンシーを低減してローカル読み取りを 高速化し、リージョン規模の停止からの災害復旧を実現する。
※マルチマスター設定非対応
マルチマスター設定:複数のマスターノードが互いに連携して動作する構成
DBインスタンスごとに、読み取りオペレーションと書き込みオペレーションの両方を実行できる Auroraクラスターのアーキテクチャ。シングルマスターと比較するとmマルチマスタークラスターは、マルチテナントアプリケーションなどのセグメント化されたワークロードに最適。
●Aurora Serverless v2
・オンデマンドで自動的にスケーリングされる Aurora データベースの構成
・アプリケーションの負荷に応じて容量を自動的に調整
・使用したリソースに対してのみ課金されるため、コスト最適化に有効
・手動のキャパシティ調整が不要になり、運用負荷が軽減
Auto Scaling 機能を備えたリレーショナルデータベース。キャパシティは自動で調整される。
コンピューティングとストレージの分離がある。結果として、個別に独立してスケールすることが可能。
| ★2025 年 3月 31 日 サポート終了 Aurora Serverless v1 (Aurora サーバーレスバージョン 1) Aurora 用のオンデマンドオートスケーリング構成。頻度が低く、断続的、または予測が困難なワークロードを処理するための、比較的シンプルかつコスト効率の高いオプションを提供。 コスト効率が良いのは、アプリケーションの使用状況に合わせて自動的に起動してコンピューティング性能をスケールし、不使用時にはシャットダウンするためである。 Aurora Serverless v1 DB クラスターでは、クラスターのコンピューティング容量を、アプリケーションのニーズに対応して増減させられる。 ※リードレプリカや複数のライターインスタンスをサポートする機能を提供しない。 このため、リードレプリカの作成や複数のライターインスタンスを持つDBクラスターの設定は実現できない。 |
エンドポイント
エンドポイントを使用すると、ユースケースに基づいて各接続を対応するインスタンスまたはインスタンスグループにマッピングできる。
| クラスターエンドポイント | DB クラスターに対するすべての書き込みオペレーション (挿入、更新、削除、DDL の変更など) で使用する。DB クラスターへの読み取り/書き込み接続のフェイルオーバーサポートを提供。 |
| リーダーエンドポイント | すべての Aurora レプリカ間で接続バランシングを自動的に実行する。 |
| インスタンスエンドポイント | 特定の DB インスタンスの詳細を調べて、診断またはチューニングを行う。 |
| カスタムエンドポイント | DB クラスター上の DB インスタンスのさまざまなサブセットに接続する。 |
| Aurora Global Database ライターエンドポイント | 書き込みリクエストと読み取りリクエストの両方を処理する。 |
[公式参考ページ]
[RDS との比較]
| 特徴 | Aurora | RDS for MySQL |
|---|---|---|
| Multi-AZ 構成 | 3つのAZに2つずつの レプリケーションを デフォルトで構成 | 2つのAZを利用 |
| データベース ストレージサイズ | 最大64TiB | 最大32TiB |
| 最大リード レプリカ数 | 最大15 | 最大5 |
| レプリケーションタイプ | 非同期的 | MultiAZ構成:同期 リードレプリカ:非同期 |
| リードレプリカの フェイルオーバー ターゲットとしての機能 | はい (データ損失なし) | はい (数分間データ損失の可能性) |
| 自動フェイルオーバー | はい | いいえ |
[引用元サイト]
DynamoDB

※スナップショットなし【NoSQL型=ビックデータ向けDB】
パーティショニング(分散処理)で、ビッグデータ処理や大量データ処理、ストリーミングデータを利用したリアルタイムデータ集計・処理などに最適。セッションデータやメタデータなどのシンプルな高速処理をするサーバレスDB。マルチAZ 3か所のAZに保存される。ストレージの容量制限がない。
※DynamoDBにSaving Plansは提供されない
[料金]
コストはHTTPリクエスト(データI/O)の回数とリクエスト、レスポンスの量(データI/Oのサイズ)により計算される
[エラー]
・Provisioned Throughput Exceeded Exception:書き込み容量の不足
機能性
●Amazon DynamoDB Read OnlyAcess権限
AWSリソースにアクセスするための一時的な認証情報をEC2インスタンスに付与する安全な方法。
●Amazon DynamoDB 有効期限 (TTL)
項目ごとのタイムスタンプを定義して、項目が不要になる時期を特定できる。指定されたタイムスタンプの日付と時刻の直後に、DynamoDB は書き込みスループットを消費することなく、テーブルから項目を削除する。TTL は、ワークロードのニーズに合わせて最新の 状態に保たれている項目のみを保持することで、保存されたデータボリュームを削減する手段として、追加料金なしで提供される。
●DynamoDB AutoScaling
Application Auto Scalingサービスを使用して、実際のトラフィックパターンに応じて、プロビジョニングされたスループット容量を動的に 調整する。これは、コストを最適化するための最も効率的で費用効果の高いソリューション。 テーブルまたはグローバルセカンダリインデックスで、プロビジョニングされた読み込みおよび書き込み容量が拡張され、トラフィックの 急激な増加をスロットリングなしに処理できるようになる。ワークロードが減ると、Auto Scalingはスループットを低下させ、未使用の プロビジョニングされた容量の料金が発生しないようにする。
[テーブル関係]
●TrasactWriteItems
テーブル内の複数のアイテムに対する調整されたオールオアナッシングの変更をサポートする。
●オプティミスティックロック
データベースの書き込みは他のユーザーの書き込みによって上書きされないように保護する。
●ペシミスティックロック
編集されている間、レコードごとロックされる。
●FGAC(Fine Grained Access Control)
DynamoDB テーブルの所有者がテーブル内のデータに対して詳細なコントロールを行うための機能。具体的には、テーブル所有者は 誰(呼び出し元)がテーブルのどの項目や属性にアクセスでき、どのようなアクション(読み込み/書き込み)を実行できるか指定できる。IAMと組み合わせて使用され組織内のユーザーのアクセスを細かく管理することができる。セキュリティ認証情報および対応する アクセス権限の管理は、IAM で行う。
処理概要
・テーブル設計(テーブル>項目(アイテム)>属性)
・プライマリキーの値を指定して、テーブルの項目に高速アクセスしデータを迅速に取得する。
・多くのアプリケーションでプライマリキー以外の属性を使って、セカンダリ(または代替)キーを 1 つ以上設定することで、データに効率的にアクセス。(ホストを増やし(ホスト1 A/ホスト2 B,C)、テーブルを自動的にスケールアップ/ダウンして容量を調整し、大量の処理が可能になる)
・データ項目に制限在り(アイテム最大サイズ:上限400KB)増え続けるデータを永続的に保持する。
処理形式
[DB処理形式]
| スカラー型 | スカラー型は 1 つの値を表すことができます。スカラー型は、数値、文字列、バイナリ、ブール、および null |
| ドキュメント型 | ドキュメント型は JSON ドキュメントなどの入れ子の属性を持つ複雑な構造を表すことができる |
| セット型 | セット型は複数のスカラー値を表すことができます。セット型は、文字セット、数値セット、およびバイナリセット。 |
[書き込み形式]
| 条件付き書き込み | 複数のユーザーが同じ項目を同時更新することを防げる |
| アトミックカウンター | その他の書き込みリクエストを妨害することなく、無条件で増分される数値属性。 |
| バッチオペレーション | アプリケーションからDynamoDBへのネットワークラウンドトリップの数を減らす |
テーブル
テーブル上に複数のパーティション{パーティションキー(大枠)+ソートキー(分類など)}。
| パーティションキー | データをどのパーティションに配置するか決定する。各パーティションへのアクセスがなるべく均一になるようなパーティションキー設計を推奨。 |
| ソートキー | ソートキーによってデータはパーティション内で並べ替えられて物理的に近くなるように配置される。QueryAPIではソートキーを指定して取り出すデータの範囲をフィルタできる。ソートキーの設定は任意。 |
| プライマリキー(主キー) | 「パーティションキー」または「パーティションキーとソートキーの複合キー」のこと。プライマリキーによってデータは一意に識別される。 |
| キーバリュー型 | リレーショナルなしにバリュー1行にデータをまとめることで高速処理になる |
| 並列スキャン | スキャンパフォーマンスの向上。 |
| 乱数 サフィックス | 書き込みスループットを大幅に向上させることができる。 |
| 制限 パラメーター | 消費されるプロビジョニング済みのスループットを制限できる(読み込みキャパシティーユニットの半分でテーブル全体のスキャンを行う) |
| グローバル テーブル | 複数のリージョン間でのレプリケーション(同期)を自動化する。 マルチリージョンフェイルオーバー機能が提供される。 APIが利用するデータが常に最新の状態で 保たれるため、リージョン間でフェイルオーバーがスムーズに行われる。 |
キャパシティモード
【24時間に1回行える】
キャパシティモードの指定はテーブル毎に設定可能。読み取りおよび書き込みスループットの課金方法と容量の管理方法を制御する。読み取り/書き込みキャパティーモードは、テーブルを作成するときに設定できる。
●キャパシティユニット
パフォーマンスをどれだけ出せるかの設定であり、これが高いとコストがかかるがパフォーマンスが出せる。キャパシティユニットは2種類に分かれる。WCU(ライトキャパシティユニット)は書き込みできる量。RCU(リードキャパシティユニット)は読み取りできる量。
- キャパシティ
利用量のこと。DynamoDBは項目の読み込み、書き込みの量。
●プロビジョニングモード
(1時間辺りのキャパシティに対する課金)
テーブルに設定すると、1秒間あたりのテーブルの読み込み及び書き込み回数に制限を設ける必要がある。DynamoDBにおけるスループットキャパシティの単位として、テーブルに書き込みキャパシティユニットと読み込みキャパシティユニットを指定する。この制限をスループットと言う。
※スループット:テーブルが1秒間に許容できるデータの書き込み及び読み込み上限回数のこと
- 読み込みキャパシティユニット
項目の読み込みについて、基本的な消費キャパシティユニットの計算は以下の通り。
・1秒あたり4KBの項目の結果整合性読み込みを2回行う:1キャパシティユニット消費
・1秒あたり4KBの項目の強力な整合性読み込みを1回行う:1キャパシティユニット消費
・1秒あたり4KBの項目のトランザクション読み込みを1回行う:2キャパシティユニット消費
なお、4KB以下の項目の場合も4KBとして計算されます。5KBの項目の場合、8KBとしてサイズを4の倍数で切り上げて計算される。8KBの場合、消費キャパシティユニットも2倍。
- 書き込みキャパシティユニット
項目の書き込みについて、基本的な消費キャパシティユニットの計算は以下の通り。
・1秒あたり1KBの項目の書き込みを1回行う:1キャパシティユニット消費
・1秒あたり1KBの項目のトランザクション書き込みを1回行う:2キャパシティユニット消費
なお、1KB以下の項目の場合も1KBとして計算される。1.1KBの項目場合は2KBとして計算される。2KBの場合、消費キャパシティユニットも2倍になる。テーブルの項目を読み込む方法には、PutItem、UpdateItem、DeleteItem、BatchWriteItemがある。例えば、5ユニットの書き込みキャパシティ/読み込みキャパシティをテーブルに設定すると、
・1秒に5KBまでの書き込み (1KB × 5回)
・1秒に20KBまでの強力な整合性読み込み (4KB × 5回)
・1秒に40KBまでの結果整合性読み込み (4KB × 10回)
オンデマンドモード
オンデマンドモード(リクエスト数課金)
事前の容量設定が不要で、使用量に応じて課金される柔軟な課金モデル。トラフィックの増減に応じて自動でスケーリングし、突発的なアクセス集中にも高可用性を維持したまま対応できます。低レイテンシーやSLA保証、セキュリティ機能も通常モードと同様に提供されており、新規・既存テーブル問わず利用可能です。また、1秒あたり数千リクエストを処理可能で、読み書きキャパシティユニットの指定が不要な点も特徴です。
- 読み込みリクエストユニット
項目の読み込みについて、以下は1リクエストユニットが消費される。
・4KBの項目の結果生合成読み込みは2回
・4KBの項目の強力な生合成読み込みには1回
項目の読み込みについて、以下は2リクエストユニットが消費される。
・4KBの項目のトランザクション読み込みは1回 - 書き込みリクエストユニット
項目の書き込みについて、以下は1リクエストユニットが消費されます。
・1KBの書き込み1回
・1KBのトランザクション書き込み1回

セカンダリインデックス
テーブルからの「属性のサブセット」と、「Query オペレーションをサポートする代替キー」で構成されるデータ構造(検索速度が向上) 1つのテーブルで 1つ以上のセカンダリインデックスを作成して、それらのインデックスに対して Query または Scan リクエストを実行する。これにより、アプリケーションは複数の異なるクエリパターンにアクセスしインデックスからデータを取得できる。ベーステーブルの項目を追加、変更、削除すると、そのテーブルのインデックスも更新され、この変更が反映される。
・すべてのセカンダリインデックスは、DynamoDB によって自動的にメンテナンスされる。
・ローカルセカンダリインデックスは基本テーブルのキャパシティモードが 継承され、グローバルセカンダリインデックスは、ベーステーブルとは別のキャパシティモードの指定が可能。
※テーブルの項目を読み込む方法には、GetItem、BatchGetItem、Query、Scan(DynamoDB API)がある。
- セカンダリ(代替)キー
Primary Key以外の属性を使って、データに効率的にアクセスできるようにする。
- Scanオペレーション(全件走査のAPI)【全体スキャン】
常にテーブルまたはセカンダリインデックス全体をスキャンし、より多くのRCUを消費する。頭からすべてのデータを取得する。全件走査であるscanを行うと、このキャパシティを食いつぶしてしまう危険性がある。対策として、属性(Attribute)で結果を絞り込むオプションがある。
- クエリ(Query)オペレーション(scanと同じで、データを取得するAPI)
プライマリキー、複合プライマリキー、パーティションキー、セカンダリインデックスといったDynamoDBのキーを条件にデータ取得ができる。ただし、検索条件に使用できるのがkeyのみ。Attributeを条件にデータ取得できない。
※DynamoDBはkeyに指定できる項目数が限られている。通常は1つ、複合プライマリキーを使用すれば2つ設定できる。 また、セカンダリインデックスを使用することで、さらに増やすことができる。しかし、keyに指定できる項目数には限界があるため、なんでもかんでもqueryで取得するというわけにはいかない。
●(属性の)射影
テーブルからセカンダリインデックスにコピーされる属性のセット。アプリケーションのクエリ要件をサポートするために、 他の属性を射影できる。その属性が自身のテーブル内にあるかのように、プロジェクション内の任意の属性にアクセスできる。
(※テーブルのパーティションキーとソートキーは常にインデックスに射影される)
[種類]
※結果整合性とは
常に2倍の強力な整合性のある読み込み容量を提供する。「1つの強力な整合性のある読み込み」=「2つの結果整合性のある読み込み」
●グローバルセカンダリインデックス(GSI)【結果整合性】
大規模にスケールされたアプリケーション向け。多数の異なる値が存在する属性間の関係を追跡する場合に特に便利。そのため、再上限に抑えて別のテーブルを作成でき、取得されるデータの量が少なくなる。
・あるテーブルをベースに、パーティションキーやソートキーの対象を組み替えて、見やすいようにテーブルを作成すること
・インデックスに関する クエリが、すべてのパーティションにまたがり、表内のすべての項目を対象とする
・専用のプロビジョニングされたキャパシティーユニットで異なるパーティションキーとソートキーを持つ別のインデックスを作成するのに役立つ。これによりテーブル内のデータへの高速アクセスを提供し要件を満たすことができる。
●ローカルセカンダリインデックス(LSI)
【結果整合性】【強い整合性】
・すべてのパーティションの範囲が、同じパーティションキーを持つテーブルパーティションに限定される
・オリジナルのテーブルのパーティションキー・ソートキーだけでは不十分な場合、別のパーティションキー・ソートキーを 設定することができる。
・GSIのパーティションキーは固定したままでテーブルを作成すること。(テーブル作成時に作成する必要がある)
※一部のAPIを除き、基本的にデータの読み書きは「プライマリキー」を指定して行う
※データアクセスの特徴にあわせてパーティションキーとソートキーを設計すると良いでしょう
[引用元サイト]
連携サービス
| Lambda | DynamoDB は AWS Lambda と統合されているため、トリガー となるDynamoDB ストリーム 内のイベントによって実行される サーバレスアプリケーションを作成できる。DynamoDB ストリームを使用すると、DynamoDB テーブル内のデータ変更に対応する アプリケーションを構築できる。テーブルの項目が変更されるとすぐに、新しいレコードがテーブルのストリームに表示され、 Lambda は ストリームをポーリングし、新しいストリームレコードを検出すると、Lambda 関数を同期的に呼び出す。 |
DynamoDB Accelerator (DAX)

フルマネージド型高可用性インメモリキャッシュ。 レスポンスを向上させる。
Dynamo DB の読取りコストを大幅に削減する。
※永続的なユースケースではない
・DynamoDBの前段にキャッシュクラスタを設置する。
・読み取りキャパシティ(読み取り操作を実施する回数)の低減。コスト削減。最大10倍のパフォーマンスにする。
削除後に、不要なスナップショットを産まない仕組みを整備。
RedShift

【データ保管庫・分析】
クラウド内で完全に管理されたペタバイト規模のリレーショナルデータベース型DWH。列指向ストレージ、データ圧縮 「ノード」というコンピューティングリソースで構成されている。
※様々なデータを集計、統合、分析のための保管庫のようなもの
※シングル AZ 配置のみをサポート
・基本的にAWSネットワークにおけるその他のサービスへのトラフィックはインターネットを経由する
[分析力]
・複雑な分析クエリの対応が可能
・BIツールと簡単に統合できる標準SQLを使用
・標準的な Apache Sparkの3倍以上の速さで、ペタバイト規模の分析を実行できる
[データの取り扱い]
・データをキャプチャできない
・スナップショットがクラスターのプライマリAWSリージョンで作成されると、セカンダリAWSリージョンにコピーされる
[拡張された VPC のルーティング]
➡[監視サービスにて説明]
構造
複数のノードのまとまり(1つのリーダノード/複数のコンピュータノード)で構成されている。「ブロック」単位で ディスクにデータを格納。
※1ブロック=1MBブロック内の最小値と最大値をメモリに保存不要なブロックを読み飛ばすことが可能
[ノード付帯機能]
●MPP(Massively Parallel Processing)
1回の集計処理を複数のノードに分散する。ノードを追加するだけで実施できる仕組み
●シェアードナッシング
各ノードがディスクを共有せず、ノードとディスクセットで拡張する仕組み
[ノードの種類]
| リーダノード | SQLクライアントやBIツールからの実行クエリを受け付けてクエリ解析や実行プランを作成(司令塔) |
| コンピュートノード | リーダーノードからの実行クエリを処理する |
| ノードスライス | 分散並列処理を実施する最小単位 |
| ゾーンマップ | (各ブロックごとに最大・最小を持っているため高速にアクセス) |
バックアップストレージ
データウェアハウスのスナップショットに関連するストレージ。
24 時間未満のRedshift Serverless リカバリーポイントについては、課金されない。
スナップショットスケジューリング機能を使用して作成される Redshift 自動スナップショットに料金は発生せず、最大 35 日間保持できる。
[料金発生について]
使用料は、バックアップ保持期間の延長やスナップショットの追加取得を行うと増加する。
24 時間を超えてリカバリーポイントを保持することを選択した場合、RMS の一部として料金が発生する。
コンソール、アプリケーションプログラミングインターフェイス (API)、コマンドラインインターフェイス (CLI) を使って行うマニュアルスナップショット。
[参考公式サイト]
WLM(Work Load Management)
Redshiftに投げ込まれるクエリ処理を実施する際に、事前に用意したWLMキューに割り当て、クエリ処理に実行(優先)順序を定義することが可能。
[構造]
構成はパラメーターグループに含まれる。
カスタマーパラメーターグループを作成してグループ内の下記設定を編集しクラスターに関連付ける。
・キュー間でのメモリ配分
・あるキューにおけるクエリータイムアウト設定
・それぞれのキュー内でいくつのクエリーが同時に実行可能か
・クエリーがどのようにキューにルーティングされるか
・誰がクエリーを実行しているか、クエリーレベルは、などの基準
[キュー]
以下情報を指定できる。
・分析時のサイズ、メモリの割合
・並列度、タイムアウトの時間
(短くて実行速度の速いクエリが実行時間の長いクエリの後に留まらないようにできる)
動的マスキング
「動的データマスキングポリシー」を設定することで、データサイエンティストなどのユーザーが機密データにアクセスしようとする際に、クエリ(問い合わせ)を実行した時点で自動的にデータをマスキング(隠す)することができる。
[主なポイント]
- データの匿名化: ユーザーの権限に応じて、表示されるデータを動的に隠すことで、機密データを保護する。
- データ変更が不要: データベース内の元のデータを変更したり、移動したりする必要はありません。ポリシーを設定するだけで適用できる。
- 柔軟なアクセス制御: 特定のユーザーや役割(ロール)ごとに、異なるマスキングルールを適用できる。
- プライバシー要件への対応: SQLクエリを編集することなく、プライバシー要件の変更に迅速に対応することが可能。
要するに、最小限の作業で、データウェアハウス内の機密データを保護し、誰がどのようにデータを見られるかを柔軟に制御できる機能である。
その他機能
| 同時実行スケーリング機能 | 一貫した高速のクエリパフォーマンスで数戦の同時ユーザーと同時クエリをサポートできる。自動的に新たなクラスターキャパシティーを追加し、読み取りと書き込み両方でクエリの増加に対応する。 |
| Redshift Spectrum | S3のエクサバイトの非構造化データに対してSQLクエリを直接実行できる。取得されるデータに基づいてクエリの計算能力を自動的に スケーリングするため、データセットのサイズに関係なく、S3に対するクエリは高速に実行される。 既存でRedshiftを利用している場合のロード対象データ容量に対するノード課金を抑える用途や、データロードにかかるリソース負荷や 金額負担を抑えたい場合の移行対象として利用できる。 |
Elastic Cache

【キャッシュDB】
NOSQL型。キーバリュー(ストア)型で非常にシンプルなデータ構造をした、インメモリデータストア(インメモリキャッシュ)。
・高速のインメモリシステムで処理を実行するため、ウェブアプリケーションのパフォーマンスを向上し、セッション情報の管理に最適。
・データをノードのメモリに保存するため、高速なデータの出し入れできる。しかし、データに永続性がなく、再起動すると、データ消去される。
・サーバノードのデプロイおよび実行をクラウド内で簡単に実行できるウェブサービス
機能性
| レプリケーション | ノード間で同じデータを共有すること。 プライマリノードへの書き込みを、プライマリノードに紐づくすべてのリードレプリカへ非同期的に反映する。耐障害性の向上・読み込みの負荷分散を実現できる。 |
| シャーディング | 【水平分割(horizontal partitioning)】 データをシャード間で分割すること。データベース内の複数のテーブルにデータを分割するための一般的な概念。リクエスト増加などで単一のマスターDBの運用で限界がある場合、一定のルールに従いデータを複数のDBに振り分けることでアクセスを分散させ、読み書きの負荷分散・コストパフォーマンス向上を図ることができる。 ・小さめのノードを、複数のシャードに分割することで、データ容量を増やしつつ、クラスタ全体のコストを抑えることができる |
構造
(クラスタ>シャード>ノード)
| クラスタ | シャードをまとめる論理グループ。複数のシャードを作ることで、シャーディングができる。データはシャード間で分割される。 クラスタごとにキャッシュエンジン(Redis, Memcached)を設定でき、Redisエンジンのクラスタはクラスタモード無効、有効の2種類。 ・Redis (クラスタモード有効) は、クラスタ 1 つにシャード 1〜15 個持つことができる。 ・Redis (クラスタモード無効) は、クラスタ 1 つにシャード 1 個持つことができる。 |
| シャード | ノードをまとめるグループ。データはノード間で同期され、2つ以上のノードを用いることで、レプリケーションできる 。 1 シャードは、読み書きができるプライマリノード 1 個と、読み込み専用のセカンダリノード(リードレプリカ)0 〜 5 個を持つ。 |
| ノード | Elastic Cache の最小単位で、保存領域(RAM)を持つ。 設定したノードタイプによって CPU 性能や保存領域のサイズが異なる。 キャッシュエンジンは、クラスタごとに設定できるため、クラスタ以下のノードすべては、同じキャッシュエンジンで動作する。 |
メモリエンジン(クラスタ構成)
●Redis
多機能(バックアップなどの機能を持っている),シングルスレッドで動作, 全てのデータ操作は排他的である特徴
・ノード間のレプリケーション機能、フェイルオーバー機能、データ永続性機能、バックアップと復元の機能がある。
・複雑なデータ型を設定できる。複数のデータベースをサポートしている。
・インメモリデータセットのソートまたはランク付けが可能である。
・データをリードレプリカにレプリケートできる。
[ノードの種類]
シャード内で、1つのPriamryノードに対して、Replicaノードは5つまで追加可能。
●Priamryノード(読み書き)
●Replicaノード(読取り)
[クラスターモード]
クラスタモードを用いるとリードレプリカが追加できなくなる。
- クラスターモード無効
・シャーディング不可能
・クラスタ作成後、ノードタイプ、エンジンタイプの変更可能。
・S3へのバックアップ、S3からの復元に対応。
- クラスターモード有効
・シャーディング可能
・クラスタ作成後、構成の変更は基本的に不可能。
・クラスタレベルでのS3へのバックアップ、S3からの復元対応可能 - [推奨]リーダーボード作成
Redis はリーダーボードを実装する上で推奨されているサービス。
通常ユーザのレーティングの計算にはネストされたクエリが必要だが、Redisではソートセットによって、ネストせず少ない計算量でレーティングなどのリーダーボードの作成に必要なクエリを実施できる。
★リーダーボード:プレイヤーは互いのパフォーマンスを比較するために用いる
【使用例:引用サイト】
[pub/sub機能を提供]
publish/subscribe(発行/購読)モデルを実現するための機能。Redisに接続しているクライアント間で、メッセージを送信できる。WebSocketなどのリアルタイム通信に利用されることが多い。
[認証処理]
Redis認証トークンを使用すると、Redisはクライアントにコマンドの実行を許可する前にトークン(パスワード)を要求でき、 セキュリティが向上。データ転送時の暗号化、データ保管時の暗号化およびRedis Authによる認証を実施することが可能。
●Memcached(ノードタイプの変更ができない)
・シンプルで高速(データ暗号化機能はなし)
・データベースなどのオブジェクトをキャッシュできる
[メトリクスの種類]
⇒[引用元サイト]
キャッシュ方法
●レイジーキャッシング(遅延読み込み)
オブジェクトがアプリケーションによって実際に要求された場合にのみキャッシュにデータを入力。
- メリット
リクエストされたデータのみキャッシュするため、キャッシュがデータでいっぱいにならない。 - デメリット
データが更新された場合に、キャッシュミスが起こらないとキャッシュされたデータは更新されない。データが古くなる可能性。キャッシュミスした場合、データの取得に時間がかかる。
(※キャッシュへのリクエスト、DBへのリクエスト、キャッシュへの書き込みが行われるため)
●ライトスルーキャッシュ
データがDBに書き込まれると常にデータを追加するか、キャッシュがリアルタイムに更新される。(※DBとCache両方書き込みされる) システムでの需要の増減に応じてノードを追加または削除するスケールアウトおよびスケールイン機能が利用できる。キーストアの永続性はない、バックアップと復元の機能がない。また、複数のデータベースを利用できない
- メリット
キャッシュのデータが古くならなく、常に最新のデータの状態になる。 - デメリット
すべてのデータをキャッシュに書き込むためアクセスされないキャッシュで圧迫される可能性。
(「有効期限 (TTL) の値を追加する」を使用すると、無駄なスペースを最小限に抑えることができる)
[データの欠落]
ノード障害またはスケールアウトにより、新規ノードをスピンアップすると、データが欠落する。このデータは、DBで追加、更新されるまで失われ続ける。最小限に抑えるには、[遅延読み込み] を書き込みスルーで指定。
スケーリング方法
Redis クラスターのスケーリングは、CPU 使用率(PrimaryEngineCPUUtilization)などのメトリクスに基づいて自動で行われる。スケーリングは、ターゲット追跡ポリシーを使用して、指定されたしきい値に合わせてノード数を増減。xスケーリング後も、アプリケーションは同じエンドポイント(Configuration endpoint)を使い続けられる。スケーリング方法は2種類ある。
- 水平スケーリング(horizontal)
横方向にノード数を増減する方法。
- 垂直スケーリング(vertical)
縦方向にノードの性能をグレードアップ、ダウンする方法。
| 水平スケーリング | 垂直スケーリング | |
| Memcached | 同じAZ内で最大40個ノードを追加する。処理能力向上。 | 性能を向上させるだけ。 |
| Redis クラスター無 | ひとつのシャード内でスケーリング。シャードの追加はできない。 | 新しいクラスターに変更後、ノードが作成されてデータがコピーされる。数秒のダウンタイムが生じる。 |
| Redis クラスター有 | シャードの追加ができるようになる。 | ダウンタイムを発生させず、スケーリング可能。 |
セッション管理
[参考]
[ローカルセッションキャッシングを使用したスティッキーセッション]
セッションの有効性は、クライアント側のCookieや、リクエストをWebサーバーにルーティングするロードバランサーで設定できる 構成可能な期間パラメーターなど、さまざまな方法で判断できる。
- 利点
アプリケーションを実行している同じWebサーバーにセッションを保存しているため、費用対効果が高くネットワークの待ち時間がなくなり セッションの取得が高速である。 - 欠点
個々のノードで保存セッションを使用する場合、障害が発生時に障害が発生したノードに常駐するセッションが失われる可能性がある。さらに、Webサーバーの数が変更された場合、特定サーバーにアクティブなセッションが存在する可能性があり、トラフィックがサーバー 全体に不均等に分散される可能性がある。適切に軽減されない場合、アプリケーションのスケーラビリティを妨げる可能性がある。
●分散セッション管理
個々のWebサーバーからアクセスできるセッションに共有データストレージを提供。Webサーバー自体からHTTPセッションを抽象化できる。 RedisやMemcachedなどのインメモリキー/値ストアを活用する。(Key / Valueデータストアは非常に高速でミリ秒未満の遅延を提供する)
- 利点
HTTPセッションだけでなく、任意のデータをキャッシュするためにも利用できる。アプリケーションの全体的なパフォーマンスを向上。 - 欠点
ネットワーク遅延とコストの増加。
メトリクス
Memcached のメトリクス [参考公式サイト]
●Evictions
新しく書き込むための領域を確保するためにキャッシュが排除した、期限切れではない項目の数。
●Get Misses
キャッシュが受信したが、リクエストされたキーが見つからなかった get リクエストの数。
接続エンドポイント
[Redis]
| スタンドアロンノード | 読み取りオペレーションと書き込みオペレーションの両方にノードのエンドポイントを使用 |
| Redis OSS (クラスターモードが無効) クラスター | すべての書き込みオペレーションにプライマリエンドポイントを使用する。読み込みエンドポイントを使用して、すべてのリードレプリカ間でエンドポイントへの着信接続を均等に分割。個々のノードエンドポイント (API/CLI ではリードエンドポイント) を読み取りオペレーションに使用する。 |
| Redis OSS (クラスターモードが有効) クラスター | クラスターモードが有効なコマンドをサポートするすべてのオペレーションで、クラスターの設定エンドポイント[Configuration endpoint]を使用する。Redis OSS 3.2 以降の Redis OSS クラスターをサポートするクライアントを使用する必要がある。個々のノードエンドポイント (API/CLI ではリードエンドポイント) から読み取ることもできる。 |
[Memcached]
| ElastiCache サーバーレスキャッシュ | コンソールからクラスターエンドポイント DNS とポートを取得する |
DocumentDB(MongoDB互換)

ドキュメントデータベースであり、JSONデータの保存、クエリ、インデックス作成が簡単に行える。MongoDBのワークロードをサポートする。 ミッションクリティカルなMongoDBのワークロードを大規模に運用するときに自動レプリケーション、継続的なバックアップ、および厳格な ネットワーク分離、可用性を提供するためにゼロから設計された、非リレーショナルデータベースサービス。また、数分で低レイテンシーの リードレプリカを最大15個まで追加し、読み取り容量を1秒あたり数百万件のリクエストにまで増加させることができる。 データのサイズは関係なし。マルチAZをサポートしていない。
[特徴]
・コンテンツおよびカタログ管理
・プロファイル管理
・モバイルアプリケーションとウェブアプリケーション
DocumentDBの優位性は柔軟にクエリが書ける点。アクセスパターンが複数ある、もしくは読み切れない場合にはDocumentDBの方が便利。
※スケーリング性能でいえばDynamoDBの方が高い。
※MongoDBと互換性あり。
Timestream

高速かつスケーラブルなサーバーレス時系列データベースサービス。1日あたり数兆件規模のイベントを最大 1,000 倍の速度でより簡単に保存及び リアルタイム分析でき、行動傾向の特定に役立つ。
・数百テラバイトのデータを格納、保存
・容量とパフォーマンスを自動的にスケールアップまたはスケールダウン
・データ用のメモリストアと履歴データ用の磁気ストアにより、データライフサイクル管理を簡素化
※時系列データ:メモリやCPUなどの利用状況の推移や気温の移り変わりなど時間的に変化する情報をデータとする
| バッチ書込み | Timestreamへのデータ書き込み処理が高速化できる。複数のログイベントを1回の書込み操作で処理することができ、NW遅延や書き込み回数によりオーバーヘッドが軽減されるため、大量のデータ生成において効率的である。 |
| マルチメジャーレコード | ・1つのレコード内に複数のメジャー(項目)をまとめて書き込める形式 ・従来のシングルメジャーレコードは「1項目につき1レコード」のみ書き込み可能 ・1回のリクエストで書き込めるレコード数は最大100件の制限があり、101件以上は複数リクエストが必要 ・実装の手間やパフォーマンス効率を改善する |
[マグネティックストレージレイヤーへの書き込み]
・時系列データを長期保存するためにマグネティック層へ自動的に移行
・大容量データのコスト効率と耐久性を向上させる
[スケジュールドクエリによる格納と分析]
・定期的にクエリを実行し、データの集計やフィルタリングを自動化
・保存済みの時系列データを分析してダッシュボードやレポートに活用可能
QLDB

(Quantum Ledger Database)
フルマネージド型。台帳データベース(※台帳データベース:変更履歴などを残し、それらを履歴として検証可能なものとする)
Neptune

フルマネージド型。グラフデータサービス(「ノード」「エッジ」「プロパティ」要素から成り立つ)
Key spaces

フルマネージド型。Apache Cassandra互換のデータベースサービス。
CDC(変更データキャプチャ)
※継続的なレプリケーション
サポートされているターゲットデータストアへの初回(全ロード)の意向が完了した後、継続的な変更をキャプチャするタスクを作成できる。
ストレージサービス

基礎知識
●静的webサイトホスティング
・サーバなしにWebサイトを構築できる
・クラウドでウェブサイトとウェブアプリケーションを構築、デプロイ、管理するための無料のサービス
●IOPS(Input Output Per Second)
1秒あたりに読み書きができる回数を表したもの。値が大きいほど性能の高いストレージである。
◇ストレージについて
gp2 ストレージのベースライン I/O パフォーマンスは、1 GiB あたり 3 IOPS で、最低 100 IOPS 。
ボリュームが大きいほどパフォーマンスが向上することを意味する。
(例)100 GiB⇒300 IOPS / 1 TiB⇒3,000 IOPS
| ブロックストレージ 【頻繁な更新】【高速アクセス】 | (データベース,トランザクションログ)データを物理的なディスクにブロック単位で管理する。 |
| ファイルストレージ 【データ共有】【過去データ一括保存】 | (ファイル共有,データアーカイブ)ブロックストレージ上にファイルシステムを構成し、データをファイル単位で管理する。 |
| オブジェクトストレージ 【更新頻度が低い】【大容量】 | (マルチメディアコンテンツ,データアーカイブ)ファイルに任意のメタデータを追加してオブジェクトとして管理する。 |
インスタンスストア
・ホストコンピューティングに内蔵されたディスクでEC2と不可分のブロックレベルの物理ストレージ
・EC2の一時的なデータが保持され、EC2の停止・終了とともにデータがクリアされる
・無料
S3

※Simple Storage Service
ネットワーク上のオブジェクトストレージサービス(HTTP,HTTPSでアクセスする)。S3エンドポイントを使用してVPC内からS3にアクセスする。耐久性、可用性99%で、ストレージ容量は無制限であり、ユーザー側で設定する。データは3つのAZに保存される。
・S3ユーザーによって既に指定されている命名規則は使えない
・使用したストレージの容量に対して費用を支払い、使えば使うほど安くなる
・画像保存に適しており、アプリケーション用として使用することが多い
・データの初回のフルバックアップ以降は、追加のバックアップはすべて増分される
・DynamoDBよりレイテンシーが高いため更新が多いファイルはおすすめされない
※S3をWebサイトホスティング用にバケットを構成する場合
ウェブサイトエンドポイントのリソースレコードの名前が、S3バケットの名前と一致する必要がある。
●S3リクエスタ支払い
データのリクエスト者がデータ転送コストを支払う仕組み。
バケット>オブジェクト
バケット
| バケット | 最大5TB |
| バックアップ領域 | ・1ファイル(オブジェクト:メタデータで管理)5TBまで ・総計制限なし(5GBまでは無料) |
S3 に格納されるオブジェクトのコンテナ。すべてのオブジェクトはバケット内に格納される。 バケットへのアップロードは書き込みアクセス許可が必要。
- AWSユーザーの正規ID
他のAWSアカウントにアクセスを許可するために必要
[s3 Sync コマンド]
S3バケット間でデータを同期するために使用される。
※EFSやFSx for Windows File Server を転送先としてサポートしていない
オブジェクト
S3 に格納される基本エンティティ(ファイルデータ)。オブジェクト(ID)データとメタデータで構成される。キー (名前) とバージョン ID によってバケット内で一意に識別される。オブジェクト所有者はオブジェクトのアクセスコントロールリスト(ACL)を更新することによって、バケット所有者にオブジェクトのフルコントロールを付与できる。
・ファイルが保存されるグループに対して、それぞれにセキュリティーポリシーを適用する
[オブジェクトの取得方法]
- 1 回で取得
Amazon S3 に格納されているオブジェクトを 1 回の GET オペレーションで取得。 - オブジェクトを複数回に分けて取得
GET リクエストの Range HTTP ヘッダーを使用すると、 S3 に格納されているオブジェクトの特定のバイト範囲を取得できる。アプリケーションの準備ができた時点でいつでも残り部分の取得を再開でき、この再開可能なダウンロードは、オブジェクトデータの一部だけが必要な場合に便利。また、ネットワーク接続の状態が悪く、障害に対処する必要がある場合にも役立つ。
[オブジェクトのアップロード方法]
AWS SDK、REST API、または AWS CLI を使用して、
・1 回のオペレーションでオブジェクトをアップロード。
※1回のPUTオペレーションで、最大 5 GB の単一のオブジェクトをアップロード可能
マルチパートアップロード API を使用すると、最大 5 TB のサイズの単一の大容量オブジェクトをアップロード可能。
・Amazon S3 コンソールを使用して 1 つのオブジェクトをアップロード。
※Amazon S3 コンソールでは、最大 160 GB のオブジェクトをアップロード可能
・オブジェクト格納成功時、【HTTPステータスコード200】を返す。
キー
バケット内のオブジェクト固有の識別子。バケット内のすべてのオブジェクトは、厳密に 1 個のキーを持つ。
ポリシー
| アクセスコントロールタイプ | AWSアカウントレベルの制御 | IAMユーザーレベルの制御 | 形式 |
| ACL | 〇 | × | XML |
| バケットポリシー | 〇 | 〇 | JSON |
| IAMポリシー | × | 〇 | JSON |
※バケットポリシーでは、プリンシパルとして対象のアカウントIDが使用するIAMロールを指定してアクセス許可を付与することができる。
●ACL
バケットとオブジェクトへのアクセスを管理できる。各バケットとオブジェクトには、サブリソースとして ACL がアタッチされている。これにより、アクセスが許可される AWS アカウントまたはグループとアクセスの種類を定義。リソースに対するリクエストを受信時、S3 は該当する ACL を調べて必要なアクセス許可がリクエスタにあることを確認する。
[(バケットの)アクセス許可を付与する]
AWSユーザーの正規ID を設定することで対応可能。
[種類]
- Bucket ACL
手軽に基本的なアクセス権(バケット及び個々のオブジェクトへのアクセス権の設定)許可のみであり拒否はなし。 - Object ACL
オブジェクト単位で制御したいときに向いている。
[指定バケット > アクセス権限 > アクセスコントロールリスト],[指定オブジェクト > アクセス権限]
| READ | バケット内のオブジェクトをリストできる/オブジェクト、メタデータを表示 |
| WRITE | (※オブジェクトは使用不可)バケット内にオブジェクトを作成 |
| READ_ACP | バケットACL、オブジェクトACLを読み込むことが出来る |
| WRITE_ACP | バケットACL、オブジェクトACLを変更することが出来る |
| FULL_CONTROL | バケットACL、オブジェクトACLの読み込み、書き込みを実施できる |
●バケットポリシー
【S3への高度なアクセス制御を実施する】
S3オブジェクトへのアクセス許可。バケット単位でIAMユーザやグループのアクセス権、他のAWS アカウントを指定することが可能。BucketPolicyの方が強いが、設定されていない場合は、ACLによって制御される。
・サーバー側の暗号化を必要としないオブジェクトのアップロードを拒否できる
・バケットにアクセス権を付けただけではアクセスできないため、オブジェクトへのアクセス許可も必要。
| x-amz-server-side-encryption | ヘッダーに追加することで、S3 へオブジェクト保存時に暗号化を強制できる。 |
| bucket-owner-full-control ACL | オブジェクトをアップロードする際に使えるACL設定の一種で、バケットの所有者にそのオブジェクトへの完全なアクセス権を与える。 |
[エレメント]
- プリンシパル(Principal)
Principalエレメントは、リソースへのアクセスを許可または拒否するユーザー、アカウント、サービス、または他のエンティティを指定。
[参考公式サイト]
●ユーザー(IAM)ポリシー
別のAWSアカウントに自分が所有するS3バケットへのアクセス利用を許可したい時、バケットポリシー及びユーザーポリシーの 両方の許可設定が必要(特定のIAMユーザー、IAMロールだけ操作できるようにしたいとき)。レプリケーションを実施するためには、両方のS3バケットにおいてバージョン管理を有効化。
●被付与者
AWS アカウント または事前定義済みのいずれかの Amazon S3 グループ。
E メールアドレスまたは正規ユーザー ID を使用。AWS アカウント にアクセス許可を付与。ただし、付与のリクエストでメールアドレスを指定すると、Amazon S3 はそのアカウントの正規ユーザー ID を確認して ACL に追加する。その結果、ACL には AWS アカウント の E メールアドレスではなく、常に AWS アカウント の正規ユーザー ID が含まれる。
ストレージクラス
※IA はinfrequent access (低頻度アクセス) の略
| Standard (S3 標準) | デフォルトのストレージ、高耐久性(低レイテンシー、高スループット) |
| Standard – IA(低頻度) | 読み込みは早く、Standardよりも安価に利用可能。 アクセスが頻繁ではないマスターデータの長期保存に適している。データの読み込みに対し課金される。耐久性はスタンダードと同じ。 |
| One Zone – IA(低頻度) | アクセス頻度が低いが、すぐにデータを取り出せる。Standard-IA と比べて20%のコストを削減できる。単一AZ内にデータを複製する(データを少なくとも 3 つのAZ に保存する他の S3 ストレージクラスとは異なり、S3 1 ゾーン – IA はひとつのAZ にデータを保存する)データの耐久性は落ちるがコストは節約できる。 |
| 低冗長化(RRS) | 重要でない再生可能なデータ向けデータの耐久性は落ちるものの、コスト面はよい。 |
| Intelligent-Tiering | 参照頻度の判別がつかない時に使用。30日間使用されなければ、更に低頻度とする。アクセスパターンが変化するような状況でも、性能の影響なく利用料金を節約することができる。最もコスト効率の高いアクセス階層に自動的にデータを移動することで、コストを最小限に抑えるように設計されている。 |
暗号化
整合性検証
★Content-MD5 ヘッダーの役割と使用方法 / オブジェクトの整合性検証
[Content-MD5 ヘッダーの目的]
- Content-MD5 は、アップロード時のデータ整合性を検証するためのチェックサム。
- オペレーション(PUT、POST、COPYなど)で送信されたデータが、Amazon S3 に正しく保存されたかを確認する。
- エラーが発生した場合、Amazon S3 はリクエストを拒否し、整合性が保証されない。
[オブジェクトの整合性検証方法]
- オブジェクトの ETag(通常は MD5 ダイジェスト)を使って、アップロード後に整合性を確認できる。
- マルチパートアップロードでは、ETag は複数パートの組み合わせで生成されるため、ETag ≠ Content-MD5 になる。
- オブジェクトをダウンロード後、ローカルで MD5 を計算し、ETag と比較することで整合性を確認可能。
[注意点]
- Content-MD5 を使用する場合、Base64 エンコードされた MD5 ダイジェストをヘッダーに含める必要がある。
- ETag が MD5 であるとは限らず、暗号化やマルチパートアップロードでは異なる形式になる。
保護機能
| パブリックアクセスブロック機能 | デフォルトはパブリックアクセスブロックは無効化。AWSアカウント全体または各S3バケット単位、アクセスポイント単位での制御が可能となり、オブジェクトがパブリックアクセスを受けないようにする。 |
| S3 オブジェクトロック | (ログの上書き、削除防止) ・ガバナンス:特別なアクセス権限を持たない限り、オブジェクトの上書きや削除、ロック設定の変更ができない ・コンプライアンス:保持期間中はルートユーザーを含め誰もオブジェクトの上書きや削除、ロック設定の変更ができない |
| バージョニング機能 | |
| S3 MFA Delete | S3オブジェクトの誤削除を防止するセキュリティ機能の1つ。バケットからオブジェクトを削除する際にMFAデバイスによる二段階認証を必須にできる。 |
管理機能
| S3インベントリ | 正確なオブジェクトのリスト化ができる。暗号化できているか確認等できる。カンマ区切り値 (CSV)、Apache Optimized Row Columnar (ORC)、または Apache Parquet 出力ファイルを通じて、S3 バケットや共有プレフィックス (オブジェクト名の先頭が共通文字列) を持つオブジェクトについて、オブジェクトおよび対応するメタデータを毎日または毎週一覧表示する。 毎週のインベントリを設定すると、最初のレポートの後は毎週日曜日 (UTC タイムゾーン) にレポートが生成される。 |
| S3 RTC (Replication Time Control) | S3 に保存された新規オブジェクトの 99.99% を 15分以内に別リージョンへレプリケート可能。 (予測可能な時間内でのレプリケーションを保証する機能で、SLAに基づいている) ・レプリケーションの時間を可視化 ※「S3 API オペレーションの総数」、「オブジェクトの合計サイズ」、および最大レプリケーション時間をモニタリング ・レプリケートを完了次第、S3イベント通知を受け取ることができる ・デフォルトでS3レプリケーションメトリクスとS3イベント通知が含まれている |
| S3ライフサイクルポリシー | S3バケット内のオブジェクトを自動的に確認して、Glacerに移動させるか、S3からオブジェクトを削除することができる。Tierringにて削除まで実行する(保存期間に基づいて削除や移動を実施する)。オブジェクトのライフタイムでS3が実行するアクションを定義することができる。 |
| S3バッチオペレーション | S3オブジェクトに対して大規模なバッチ操作ができる。コンソールで数回クリックするだけでS3の数十億オブジェクトのリストに対して、1つのオペレーションを実行することができる。また、全てのオブジェクトタグを置き換えすることが可能。 |
| S3 Range Get | オブジェクト全体を読み取らず、必要な部分やバイトの身を読み取ることができる。 |
| Multi-Object Delete API | 単一の HTTP リクエストで最大 1,000 個のオブジェクトを削除。 |
| 破損検出 | Content-MD5チェックサムと周期的な冗長性(CRC)チェック。 |
共有(クロス)機能
| CRR(クロスリージョンレプリケーション) | リージョンを跨いで別のバケットにリアルタイムでオブジェクトをコピーできる。 障害発生時にデータを保護する観点から有効なサービス。 |
| SRR(同一リージョンレプリケーション) | 同じリージョン内のS3バケット間でオブジェクトをコピーする際に使用。 |
| CORS(クロスオリジンリソースシェアリング) | 1つのWEBサイトを複数のドメインでS3リソースを共有して利用できる、最新ウェブブラウザのセキュリティ機能。設定することで、特定のドメインに関連付けられたWEBアプリケーションが異なるドメイン内のリソースと通信する方法を定義する。 |
| クロスアカウントレプリケーション | S3バケットを別のアカウントに共有(コピーが生成)することができる。 |
| Mount Point for Amazon S3 | S3のデータ領域をEC2やECSにマウントして、共有ディスクのように利用できる。 ※各 EC2 と S3 間の最大100 GB/秒のデータ転送などと高スループット EC2上のアプリケーションは「開く・読み取る」などのファイルシステム操作を通じて S3に保存されているオブジェクトにアクセスできる。これらの操作はS3オブジェクト API 呼び出しに自動的に変換し、アプリケーションがS3のエラスティックなストレージとスループットにファイルインターフェイスを通じてアクセスできるようにする。 |
その他機能
●静的Webホスティング機能
バケットに格納した静的なファイルをウェブサイトとして公開することができる機能。
●S3イベント
「新しいオブジェクトの作成イベント」,「オブジェクト削除イベント」,「オブジェクト復元イベント」,「低冗長化ストレージ (RRS)。 オブジェクト消失イベント」,「レプリケーションイベント」発生時、イベントを通知発行する。
・S3へのアクションをトリガーにLambdaを呼び出すことができる。
[引用元サイト]
[S3のイベント発行トリガー]
①Amazon SNSトピック:S3をトリガーとしてメールなどを通知できる。
②Amazon SQSキュー:S3をトリガーとしてStandardキューを配信できる。
③AWS Lambda:Lambda関数を作成時、カスタムコードをパッケージ化してLambdaにアップロード。S3をトリガーにLambda関数を実行できる。
●S3アクセスポイント
S3 の共有データセットへの大規模なデータアクセスの管理を簡素化する機能。アクセスポイントはバケットにアタッチされた名前付きのネットワークエンドポイントで、S3 オブジェクトのオペレーション (GetObject や PutObject など) を実行するために使用できる。。同時書き込みのオブジェクトロックはサポートしない。2020年12月まで、結果整合性モデルを主だったが、現在は強い結果整合性モデル。
(アクセス制御に役立つが、プライベート接続の確立には不十分)
※VPCエンドポイントの接続先として利用されることもある
[引用元サイト]
●S3 アダプター
プログラムによるデータ転送とデータ転送を行うことができル。AWS Snowball EdgeAmazon S3 REST API アクションを使用するデバイス。AWS Snowball Edge デバイスにデータを転送する方法として利用される。
●ストレージクラス分析
ストレージアクセスパターンを分析し、適切なデータを適切なストレージクラスに移行すべきタイミングを判断できる。フィルタリングされたデータセットのアクセスパターンを一定期間監視することで、ライフサイクルポリシーを設定することができる。
●S3 Object Lambda アクセスポイント
S3オブジェクトにアクセスする際にLambda関数を使ってデータを動的に加工・変換できる仕組み。通常のS3 GET、HEAD、LISTリクエストに対して、カスタムコードを挟むことが可能。これにより、オブジェクトの内容やメタデータを動的に変更して返すことができる。
生データを直接変更することなく、各アプリケーション固有の処理要件に合わせたデータの動的変換が可能になる。
[主な用途]
- 画像の動的リサイズ(例:レスポンシブ対応)
- 機密情報のマスキング(例:個人情報の除去)
- CSVやJSONのフィルタリング(例:特定行だけ返す)
- カスタムビューの生成(LISTリクエストで特定条件のオブジェクトだけ表示)
エラー
●403 Access Denied
オブジェクトは存在するが、そのオブジェクトの読み取りアクセス許可が付与されていない。
[考えられる要因]
・リクエスタ支払いバケットに関するリクエストがすべて認証されていない場合、アクセスできない
・S3バケットからS3ブロックパブリックアクセスのオプションを削除していない
Glacier
アーカイブを目的としたストレージ。大容量のデータを安価に安全で耐久性が高く、非常に低コストのストレージクラス。S3と同じ耐久性をもち、また同様に複数AZにデータを保存するため回復性が高い。読み込みに時間がかかる。
・Glacierの最低保持期間は90日。3カ月以上保管されていたアーカイブを削除する場合は無料。
・1つのアーカイブの最大サイズは 40 TB。1カ月あたり10GBまで無料。保存可能なアーカイブ数とデータ量に制限なし。
[階層] ボールト/アーカイブ/インベントリ
[取り出しオプション] 高速、標準、バルク(大容量)
機能
●S3 glacier Select
S3 Graicerの保存データの参照。
●S3 Glacierボールト
| ボールトロックポリシー | 一度ロックされると変更できなくなる。保護されているアーカイブがなくなるまでロックされたポリシーを削除または変更できない。 |
| ボールトアクセスポリシー | ボールトに対するアクセス許可を管理する。 |
| ボールト通知 | ジョブが完了すると、メッセージがSNSトピックに送信されるように設定できる。 |
| 迅速取り出し | アーカイブの最大容量は250MBまで |
暗号化
保存時にSSLで実施。サーバー側ネイティブで暗号化される。キー管理とキー保護が自動的に行われ、AES-256が使用される。
ストレージクラス
| Instant Retrieval | 【高速引き出し】 アクセスされることがほとんどなく、ミリ秒単位で取り出すことが可能。取り出す期間が四半期に一度などと、長期間であると大幅にコストを削減することができる。 ・高速の復元が必要になるアーカイブ済みデータ ・ミリ秒単位で復元 |
| Flexible Retrieval | 一年に1~2回アクセスするなどと取り出し頻度が少なく、大量のデータを取り出すことができる。Instant Retrievalよりも最大10%安くコストを抑えられる。 ・予測不能だが復元が必要になるオブジェクト ・数分~数時間で復元 |
| S3 Express One Zone | 超低レイテンシー・高頻度アクセス向けのオブジェクトストレージクラス。AWSの新しいストレージクラスで、単一のアベイラビリティーゾーンにデータを保存し、高速で低レイテンシーなアクセスを実現する。通常のS3よりも読み書きが速く、リクエストコストは安いが、保存コストは高め。主にリアルタイム分析や頻繁にアクセスする小さなデータ向けで、低遅延を重視する用途に適している。ただし、単一AZのため、AZ障害が起きるとデータ損失のリスクがある点には注意が必要。 |
| Glacier Deep Archive | Flexible Retrieval より安く、取り出しに12時間~かかる。 ・復元される可能性が低いアーカイブデータ ・12時間以内で復元(オブジェクトを取得する度に、復元リクエストも必要になる) ◎オプション ・迅速 (250 MB 以上) を除く:1~5分 ・標準取り出し:3~5時間 ・大容量取り出し:12時間 (高い←→安) |
S3 Transfer Acceleration
【高速アップロード】※受信トラフィック用のサービス
クライアントとS3バケットの間で、長距離にわたるファイル転送を高速、簡単、安全にする。 ※Amazon CloudFront の世界中に点在するエッジロケーションを利用してアップロードレイテンシーを改善
➡レイテンシーを改善するわけではないため注意
マルチパートアップロード
パラレル形式で送信する。アップロード中に中断されたパートのアップロードを再試行するだけで済む 大容量オブジェクトをいくつかパートのセットとしてアップロードできるようになる。各パートはオブジェクトのデータを連続する部分。これらのオブジェクトパートは任意の順序で個別にアップロードできる。いづれかのパートの送信が失敗すると、他のパートに影響を 与えることなくそのパートを再送することができる。
ただし、地理的な遅延の対応としては適当ではない。
マルチアップロードはチャンクを並列でアップロードすることにより、サービスを実現している。
EBS

(Elastic Block Store)
EC2とEBS間に専用線をひくことで、EC2にアタッチされる永続的なブロックレベルのネットワーク接続型ストレージ。(外付けストレージのようなもの)データに素早くアクセスできる。サイズ(割り当てたボリューム分)と利用期間によって課金される。
●Amazon EBS 最適化インスタンス
最適化された設定スタックを使用し、EBS I/O に対して追加の専用の容量(帯域幅)を提供する。この最適化は、EBS I/O とその他のインスタンスからのトラフィック間の競合を最小化することで、EBS ボリュームの高パフォーマンスを提供する。
[ステータス]
- ok:通常状態
- warning:パフォーマンスが下回っている
- impared:致命的な被害
- insufficient-data:実行中
性能面
・初期化を必要としない
・ディスクの縮小は不可
・書き込みのスループットが高いアプリケーションに適する。[IOPS最大割合(GiB単位)500:1]
・他のリージョンにコピー可能(スナップショットから作成する)
・EBSボリュームが作成されるとすぐに最大パフォーマンスを発揮。
・セキュリティグループによる保護は対象外(全ポートを閉じても利用可能)
・NFSv4 プロトコルは利用していない
・保存世代や世代数は無制限
・RAID5,RAID6構成はIOPSがパリティ書き込みによって消費されるため推奨されない(RAID構成はRAID0 , RAID1)
[アタッチ・デタッチについて]
・複数のインスタンスを対象に接続はできない(他のインスタンスへ付け替えは可能)
・AZは跨げない(EBSマルチアタッチ:AZ内の複数のインスタンスにアタッチできる)
・インスタンスに EBSボリュームをアタッチ後に任意のファイルシステムでボリュームをフォーマットしてからマウントすることが必要
- DeleteOnTermination
属性を使用すると、EC2インスタンスが削除されても接続されたEBSとデータは保持される。
バックアップ
スナップショットによる、増分バックアップ。スナップショット中は読み書きが可能。
※EBSのスナップショットをS3にコピーすることはできない。
●EBS高速スナップショット復元機能
通常のスナップショット復元で発生するブロックの初回アクセス時におけるI/Oオペレーションのレイテンシーがなくなる。
●Data Lifecycle Manager (Amazon DLM)
EBSのバックアップであるスナップショットの作成、保存、削除を自動化。
また、スナップショットの管理に必要な許可を得るためには、IAMロールを使用する。
※リージョン間でコピーすることができる
●クロスリージョンコピー機能
一度作成するだけで、EBSスナップショットを少なくとも2つのリージョンへ毎日自動複製できる。
ボリュームタイプ
[SSD]
| 汎用SSD | EC2のブートボリューム、アプリケーションリソース向け。バースト機能で3000IOPSまで処理できる(ベースラインは300IOPS) |
| プロビジョンドIOPS | I/O負荷の高いデータベースのデータ領域向け⇒IOPSに対して課金あり、DBによく使われる。ボリュームサイズに対するプロビジョンド IOPS の最大割合(GiB 単位)は500:1。 |
[HDD]
| スループット最適化HDD | ログ分析、バッチ処理用大容量インプットファイル向け |
| コールドHDD | アクセス頻度が低いデータのアーカイブ向け |
| マグネティック | 旧世代のボリュームタイプ |
[EBS ボリューム拡張方法]
- EC2コンソールまたはCLIからEBSボリュームのサイズを増やす。
- オペレーティングシステムにマウントされたボリュームのファイルを拡張して、追加したストレージ容量をしようする。
暗号化
EBSボリュームやスナップショット作成時、KMSのCMKを使用して暗号化。
●EBS Encryption
EBSストレージ間でのデータ保存と転送中のデータの両方のセキュリティを暗号化し保証する。
ただし、新規作成されるボリュームに対してのみである。
※既存ボリュームの暗号化はConfigやEventBridgeなどを利用して暗号化すること
[ボリューム内の保存データも可能]
現世代のすべてのインスタンスタイプ、旧世代のインスタンスタイプ A1、C3、cr1.8xlarge、G2、I2、M3、R3 で使用可能。暗号化処理はインスタンスが稼働するホストで実施される(ストレージ自体の暗号化)。ボリュームから取得したスナップショットも暗号化は適用される(スナップショット数:デフォルト最大100,000)。スナップショットは基本的に自動的にS3に保存される。
[既存EBSボリュームを暗号化する手順]
- 既存EBSボリュームのスナップショットを取得
- 取得したスナップショットを、[EBS暗号化] を有効化しコピー
- コピーしたスナップショット(暗号化済み)から EBS ボリュームを作成
- EC2インスタンスから既存EBSボリュームをデタッチする
- EC2インスタンスに作成した EBSボリューム(暗号化済み)をアタッチする
EFS

※Elastic File System
リージョン、AZ、VPC間でファイルシステムにアクセスできる。Direct ConnectあるいはVPNを介して複数のEC2インスタンスやオンプレミスサーバー間でファイルを共有できる。
※Windowsファイルサーバーをサポートしていない
・POSIX準拠、耐久性、高可用性、MySQL・PostgreSQL
・マウントターゲット(エンドポイントのようなもの)はAZ内に作成しなくてはならない。
・自動的に3か所のAZに作成される。オンプレミスを含めて、複数のAZに跨ることが可能。
[暗号化]
「転送時の暗号化」と「保管時の暗号化」をサポートしている。
※EFSを作成する際は、「保管時の暗号化」を有効にすること。(暗号化するときに再度作成する羽目になる)
[料金表]
S3より少し料金が高くなる
●EFS CSIドライバー
Kubernetes(特にAmazon EKS)でAmazon EFSを使うためのストレージドライバー。
●amazon-efs-units
ファイルシステムにトラブルが発生した場合のトラブルシューティングに役立つログを記録できる。
機能性
・競合することなく部分的な変更もできる。
・大規模で並列の共有アクセスできる設計。
・アクセス頻度の低いストレージクラスに適している。
・強い整合性やファイルのロックなど が用意されている。
・インスタンス間で共有ストレージを頻繁に読み取ることができる。
※Windowsファイルサーバーはサポート外
[利用メリット]
・EFSの高可用性・スケーラビリティを活用可能
・Pod間でファイルを共有できる
・ステートフルなアプリに最適
[アプリケーション処理]
高レベルのスループットとIOPSを一定の低レイテンシーで実施。
中断することなく、ファイルの追加や削除に合わせて、自動的にペタバイトのオンデマンドにストレージ容量の拡張や縮小する。
[主なポイント]
| 項目 | 内容 |
|---|---|
| 目的 | KubernetesのPodからEFSをマウントしてファイル共有 |
| 利用方法 | Persistent Volume(PV)としてEFSを使う |
| 特徴 | 複数Podで共有可能、動的プロビジョニング対応(v1.2以降) |
| 導入 | EKSアドオンとして簡単にインストール可能 |
| 対応環境 | Amazon EKS、Fargate(一部制限あり)、Graviton |
構成要素
| ファイルシステム | ファイルを保存するための論理的なストレージ領域です。VPC内に作成され、複数のAZにまたがってデータを複製することで高可用性を実現します。 |
| マウントターゲット | ファイルシステムへのアクセスを提供するエンドポイントです。各AZにマウントターゲットが作成され、EC2インスタンスはそのマウントターゲットを介してファイルシステムにアクセスします。 |
ファイルシステム
●(推奨)EFSリージョナルファイルシステム
複数のAZにわたってデータを保存したりすることで、高レベルの耐久性と可用性を実現する。
●EFS One Zone
1つのAZ内にデータを冗長的に格納する。そのため、耐久性、可用性に脆弱性がある。
パフォーマンスモード
・汎用パフォーマンスモード(基本)
・最大I/Oパフォーマンスモード
・スループットモード
・バーストスループットモード
・プロビジョニングスループットモード
プロビジョンドスループット
ファイルシステムが駆動できるスループットのレベルを指定する
バックアップ
EFSデータの保護と復元が柔軟かつ効率的に行えるよう設計されている。
| AWS Backupとの統合 | 完全に管理されたポリシーベースのサービス「AWS Backup」とネイティブに統合されている。 |
| バックアップの種類 | ・継続的バックアップ:ある時点の状態(Point-in-time)への復元が可能 ・定期的バックアップ:長期的な保存目的で使用 |
| バックアッププランの管理 | 自動化されたスケジュール設定や保持ポリシーの指定が可能。以下の項目を管理できる。 ・頻度(どれくらいの間隔でバックアップするか) ・タイミング(いつ開始するか) 保持期間(バックアップの保存期間) ライフサイクル(保存・削除の自動管理) |
| 復元の柔軟性 | ・新しいファイルシステムへの復元 ・既存のファイルシステムへの復元 ・完全復元または項目レベルでの復元も選択可能 |
Fsx

※for Windows File Server
※NFSバージョン4 非対応
フルマネージド型ファイルサービス(Windows向け)【Windows File Serverと互換性あり】
・デプロイタイプは一度作成すると更新できない
種類

●for Windows
ファイルシステム当たり最大 2 GB/秒のスループット、数百万のIOPS、一貫したミリ秒未満のレイテンシーという高速パフォーマンスが実現可能な高性能なストレージ。
・HDDからSSDに変更することはできない

●for Lustre
ハイパフォーマンスコンピューティングなどで高速ストレージを必要とするアプリケーション向けに設計されている。Lustre ファイルシステムを簡単かつ費用効果の高い方法で起動して実行する。
※Lustre ファイルシステム
高速ストレージを必要とするアプリケーション向けに設計されており、ストレージがコンピューティングに対応できるように設計されている。リ秒未満のレイテンシー 最大数百 Gbps のスループット、および最大数百万のIOPS を提供。

●for OpenZFS
OpenZFS ファイルシステム上に構築され、NFS プロトコル (v3、v4、v4.1、および v4.2) を介してアクセスできるフルマネージド共有ファイル。

●for NetApp ONTAP
AWS 上でフルマネージドの NetApp ONTAP ファイルシステムを提供するストレージサービス。オンプレミスの NetApp 環境と同様の機能・API をクラウドで利用可能。
・NFS、SMB、iSCSI などの業界標準プロトコルに対応
・Linux、Windows、macOS からの広範なアクセスをサポート
・スナップショット、クローン、レプリケーション などの高度なデータ管理機能を簡単に利用可能
・圧縮・重複排除 によるストレージコスト削減
・フルエラスティックで実質無制限のストレージ容量
[(for NetApp ONTAP)SnapMirror によるレプリケーション概要]
- スケジュールされたレプリケーションによるデータ保護
・FSx for ONTAP 間、またはオンプレミスから AWS への定期的なデータ複製が可能。
・リージョン内・クロスリージョン両方に対応。
・最短 5 分間隔でレプリケーション可能(RPO/RTO/パフォーマンスを考慮して設定)。
- SnapMirror の技術的特徴
・高可用性と効率的な災害対策に有効。
・ONTAP の Snapshot 技術を活用。
・差分データのみを転送することで、ネットワーク帯域を節約し、高速なレプリケーションを実現。
デプロイタイプ
以下の2つのデプロイタイプを提供する。
コストを抑えたい用途にはシングル AZ。高い可用性・耐障害性が必要な業務にはマルチ AZ。
| シングル AZ (アベイラビリティーゾーン) | 構成:1つのAZにファイルサーバーとストレージを配置。 可用性:単一コンポーネント障害には自動復旧、ただし完全な可用性は保証されない。 ダウンタイム:メンテナンスや障害復旧時に約30分のダウンタイムあり。 リスク:稀に複数障害で回復できない場合があり、その際はバックアップから復元可能。 |
| マルチ AZ | 構成:2つのAZにまたがる高可用性クラスタ(WSFC使用)。 可用性と耐久性:AZ間での同期複製と自動フェイルオーバーにより、可用性とデータ保護が強化。 ダウンタイム回避:計画的/計画外の障害でも継続利用が可能。 |
snowball

ペタバイト規模のデータをAWSクラウドに高速かつ安全に移行できる物理的なデータ転送サービス。※[使用不可]snowball:(50~80TB)

●Snowball Edge Compute Optimized(42TB)
AWSが提供する物理デバイスで、ローカル環境で強力なコンピューティング処理が可能。限られたネットワークインフラストラクチャをもつ工場サイトでのアプリケーションホスティングに適している。このデバイスはエッジロケーションでのコンピューティング、データ転送、ストレージのタスクを処理する能力を持っており、同時に一貫したAWS開発者エクスペリエンスを提供する。
| 項目 | 内容 |
|---|---|
| vCPU | 104コア |
| メモリ | 416 GiB |
| GPU | オプションで NVIDIA Tesla V100 を搭載可能 |
| ストレージ | 28TB(NVMe SSD)で S3 互換または EBS 互換として利用可能 |
| インスタンスタイプ | sbe-c(C5, M5a 相当)、sbe-g(G3, P3 相当) |
●Snowball Edge Storage Optimized(HDD:80 TB/NVMe 容量:210 TB)
大容量データ(例:200TB)をネットワークに頼らず迅速かつ安全にオンプレミスから Amazon S3 へ移行できる専用デバイス。特に帯域が限られた環境で、時間とセキュリティの面で大きな利点がある。

Snowcone ※[2025年11月12日までサポート]
エッジコンピューティングとデータ転送のためのポータブルで堅牢かつ安全なデバイス。デバイスをAWSに発送してオフラインで、またはDataSyncを使用してオンラインでデータを収集、処理し、AWSクラウドに移動できる。
自動化サービス



基礎知識
●データストア
コンピュータシステムに情報を格納して保護するデジタルリポジトリ。
情報テーブルなどの構造化データと、E メール、画像、動画などの非構造化データの両方を保存できる。
●Puppet
サーバーの環境設定やインストールなどを自動化する設定管理ツール。Ruby で実装されており、各種操作の実行を行うためのフロントエンドであるpuppetコマンドと、各種機能を実装した Ruby ライブラリから構成される。
Lambda

【処理の自動化】
サーバやアプリケーションを立てずに、実行したい処理をコードで実施できるコンピューティングサービス(アプリケーションをデプロイする)。Lambda API を使用して関数の呼び出し、Lambda を使用してその他の AWS サービスからのイベントをトリガーにして関数を実行できる。再帰的な(自己の行為の結果が自己に戻ってくる)なコードの使用は避けること。
機能性
| オートスケール | 処理件数に対して、自動的に実行ユニットを増やして並列にスケールアウトする。 |
| Lambda のクォータ | ・最大実行時間:900秒(15分) ・メモリの割り当て:10,240MB ・エフェメラルディスク:512MB(/tmpディレクトリのストレージ上限) ※メモリの量に比例して、CPUパワーを割り当てる。 |
| デプロイパッケージ | 「コンテナイメージ」、「zip ファイルアーカイブ」の 2 種類ある。 [デプロイパッケージのサイズ] ・50 MB(zip 圧縮済み、直接アップロード) ・250MB(解凍、レイヤーを含む) ・3 MB(コンソールエディタ) 依存パッケージをまとめて、libフォルダー内にライブラリーとして配置すると解凍時間を短縮できる。 |
| コンテナイメージ | コンテナイメージからLambda関数を作成できる。 |
| 実行ロール | AWS サービスおよびリソースにアクセスする許可を関数に付与するIAM ロール。他のAWSサービス(S3など)からファイルを取得する時、その権限が含まれるIAMロールをLambda関数に割り当てる必要がある。CloudWatch にログを送信し、トレースデータをX-Ray にアップロードするためのアクセス許可をもつ開発用の実行ロールを作成できる。 [参考] |
●Monitor 設定
パフォーマンスメトリックやオペレーショナルな監視に関連する設定。
●デッドレターキュー
正常に処理できなかったイベントをSQSキューやSNSのトピックにリダイレクトしてエラーを監視・分析する。
・2回の再試行の後にイベントを処理することを失敗したイベントをキャプチャできる。その際、最初の 2 回の試行の間に 1 分間、2 回目と 3 回目の間に 2 分間の待機時間がある。
・関数エラーには、関数のコードによって返されるエラーと、タイムアウトなど関数のランタイムによって返されるエラーが含まれる。
●エクスポネンシャルバックオフ
【許容可能なリトライ】
リクエスト処理が失敗した後のリトライで、現実的に成功しそうな程度のリトライを許容可能な範囲で徐々に減らしつつ継続するアルゴリズム。再試行する度に、1秒後、2秒後、4秒後と指数関数的に待ち時間を加えていく。全体のリトライ回数を抑え効率的なリトライを実現。
●Lambda Layer
【Lambdaコード共有】
コードやライブラリ、共通のビジネスロジックをZIPアーカイブをLayerに追加し、複数のLambda関数で、外部ライブラリやビジネスロジックを共有できる仕組み。主には異なるLambda関数間で、同じ処理を使いたい場合に利用する。
・デプロイパッケージの容量を少なくなるためLambdaのソースコードの管理が楽になる。
★これまでは同じライブラリを利用する関数が複数あった場合、全ての関数に対してライブラリを含めてパッケージングすることが必要だった。ライブラリをLayerとしてアップロードしておくことで、個々の関数はLayerを使用することができる。
- レイヤー
追加のコードまたはデータを含むことができる .zip ファイルアーカイブ。
●Lambda エイリアストラフィックシフティング
【面倒なデプロイ簡素化】(※エイリアス:Lambda関数のバージョンを参照するポインタ)
エイリアスの追加バージョンの重みを更新することで、呼び出しトラフィックは指定された重みに基づいて新しい関数のバージョンにルーティングされる。これによってLambda関数の2バージョン間でシフトを行う場合、Lambda関数のエイリアスに重み付けを行うことが可能になり、カナリアデプロイやブルーアンドグリーンデプロイメントといった方法が使用できるようになった。
●Lambda SnapStart
Lambda 関数の初期化処理が終わった後に、実行環境のスナップショットを取って、コールドスタートに該当する起動の場合にスナップショットからのリストアを行うことでコールドスタートの場合の起動時間を短縮する。ゼロから初期化するのではなく、キャッシュされたスナップショットから新しい実行環境を再開するため、起動時のレイテンシーが短縮される。
※一意の ID を生成するコードを Lambda ハンドラーに移動することで、スナップショット時に不要な初期化が防げる。
[仕組み]
①関数バージョンを発行するときに関数を初期化
②初期化された実行環境のメモリとディスク状態の Firecracker MicroVM スナップショットを作成
③スナップショットを暗号化して、低レイテンシーアクセスのためにキャッシュする
※Lambda SnapStart for Java
レイテンシーの影響を受けやすいアプリケーションの起動パフォーマンスを追加のコストなしで最大 10 倍 向上させることができ、通常は関数コードの料金もかからない。
●Lambda トランスフォーマー
API GatewayとAWS Lambdaを連携させる際に、リクエストやレスポンスのデータ形式を変換するための機能。
これは主に、API Gatewayが受け取ったJSON形式のデータを、Lambdaが処理しやすい形式(例えば、シンプルなJSONや特定のデータ構造)に変換したり、逆にLambdaからのレスポンスをAPI Gatewayのクライアントが期待する形式に変換したりする際に使われる。
Lambda関数ハンドラー
[呼び出し関数]
Lambdaがコードを実行する際に呼び出す関数名。関数が呼び出されると、Lambda はハンドラーメソッドを実行。関数はハンドラーが応答を返すか、終了するか、タイムアウトするまで実行する。
[ハンドラー外の実行について]
Lambda 関数内の処理は関数が再度呼び出された際に追加で最適化されない限り、初期化状態が維持される。グローバル領域(ハンドラー外)の処理は初期化されないため、キャッシュのように処理が最適化される。そのため、Lambda関数のグローバル領域(ハンドラー外)に動的な処理は書かない方が良く、リソースへの接続などのワークロードが適切。
グローバル領域(ハンドラー外)に何か書くときは以下の点を意識する。
・コールドスタート時はグローバル領域(ハンドラー外)の処理が実行される。
・ウォームスタート時はグローバル領域(ハンドラー外)の処理が実行されない。
[引用サイト]
処理実行
利用できる同時実行コントロールには、次の2種類がある。
●予約された同時実行
Lambda関数に必要な同時実行数の上限と下限を設定し、リソースの優先確保や過負荷防止を可能にする仕組み。ある関数が予約済同時実行数を使用している場合、他の関数はその同時実行数を使用できない。スケーリングの制御と安定した処理性能の確保に役立つ。設定に追加料金は発生しない。
[同時実行数を下げるメリット]
システム全体の安定性と効率を高めるための「負荷制御」が働くため。同時に大量のリクエストを処理しようとすると、CPU・メモリ・ネットワーク帯域などのリソースが奪い合いになる。実行数を制限することで、各プロセスが十分なリソースを確保でき、安定して処理できるようになる。
●プロビジョニングされた同時実行
関数に割り当てる、事前に初期化された実行環境の数。(関数のレイテンシーを下げる場合に最適)
これらの実行環境は、受信した関数リクエストに即座に対応できるように準備される。プロビジョニングされた同時実行を設定すると、AWS アカウントに料金が請求される。
※予約済同時実行数の設定
同期呼び出し(invoke)
関数が呼び出しを受けると、その関数の処理にインスタンスを割り当てて処理を実行する。完了次第、別のリクエストの処理に移ることができる。なお、処理中に別のリクエストが呼び出されると別のインスタンスを割り当てて、別リクエストの同時実行になる。
●同期的処理
エラーが発生した場合、処理が成功するか、データの有効期限が切れるまでLambdaはバッジを再試行する。
※Kinesis Streamと比較
Data Streamからレコードを読み取り、ストリームレコードを含むイベントを使用して関数を同期的に呼び出す。
●非同期呼び出し
関数の非同期イベントキューを管理しエラー発生時に再試行を行う。
関数からエラーが返された場合、関数エラーを 2 回再試行する。
- リクエストデータ
以下が含まれる。(ただし、リクエストパラメータの順序は保持されない)
・リクエストヘッダー
・クエリ文字列パラメータ
・URL パス変数
・ペイロード
・API 設定データ
※現在のデプロイステージ名、ステージ変数、ユーザー ID、または承認コンテキスト (存在する場合) を含める。
| リソース | リソースパスを介してアプリがアクセスできる論理エンティティを表す。 |
| メソッド | APIユーザーによって送信されるREST APIリクエストやユーザーに変えるレスポンスに対応。 (※リクエスト、レスポンスで構成) |
| ステージ | タグに似ている。ステージは、デプロイ環境からアクセス可能なパス経路を定義する。 |
[API Gatewayの統合タイプ5種]
| AWS_PROXY | Lambdaプロキシ統合の場合に選択。 |
| AWS | Lambdaカスタム統合およびその他すべてのAWS統合の場合に選択。 |
| HTTP_PROXY | バックエンドのHTTPエンドポイントを公開するかつ、統合リクエストと統合レスポンスの両方を特別に設定する必要がない場合。 |
| HTTP | バックエンドのHTTPエンドポイントを公開するかつ、統合リクエストと統合レスポンスの両方を指定したい場合。 |
| MOCK | このタイプの統合はリクエストをバックエンドに送信することなくレスポンスを返すため、テストを行う場合に選択する。 |
[バッチ分割]
大量のデータを小さなグループ(バッチ)に分割し、それぞれのバッチを個別に処理する手法。これにより、処理効率の向上やリソースの最適化が期待できる。
また、関数がエラーを返した場合、再試行する前にバッチを2つに分割し処理をすることができる。元のバッチサイズ設定は変更されない。
[rate または cron を使用する式をスケジュール]
[参考公式サイト]
連携サービス
| SQS 非同期処理(疎結合) | ・サーバレスアーキテクチャ ・Lambdaを使用するにはトリガーとして全段にサービスが必要(SQS、APIGateway・・・など) ・Lambdaの処理が失敗した場合(デッドレターキュー)、再実行できる |
| Kinesis Data Stream 高速処理 | ⇒該当ページへ遷移 |
| API Gateway 非同期処理 | ●プロキシ統合タイプ シームレスに統合し、サーバーのプロビジョニングや管理を行うことなく、拡張性の高いアーキテクチャを提供する高速なメカニズム。クライアントが API リクエストを送信すると、API Gateway は統合されたLambda関数にイベントオブジェクトを渡すための「玄関(トリガー)」として機能する。 ・RESTful API および WebSocket API を作成することができる。 ●REST API リソースとメソッドで構成。リアルタイム双方向通信アプリケーションを実現する。 |
Amplify

【WebApp自動構築】
AWSのクラウドサービス上にモバイルアプリケーションを構築するための最も速く、簡単な方法。ポピュラーなバックエンドの構成とそれを利用するためのフロントエンドの統合を自動で構築できる。
Amplify を使って、オブジェクトストレージの S3 とCDN (コンテンツ配信ネットワーク)の CloudFront を利用したスケーラブルな Web サイトホスティングを始め、ユーザー認証機能や RESTful API や GraphQL API の作成・管理など、豊富な機能が自動的にセットアップされて、簡単に利用できる。
例えば、 Amplify を通じて Web アプリを公開すると、オブジェクトストレージの S3 や CDN (コンテンツ配信ネットワーク) の Cloudfront が自動的にセットアップされスケーラブルなバックエンドが自動的に構成される。
また、アプリにログイン機能を実装したいときは、 Amplify でアプリケーションにユーザ認証機能を追加すれば、アイデンティティおよびデータ同期の Cognito が透過的にプロビジョニングされる。
[引用元サイト]
CloudFormation

【リソース構築自動化】
YAML という形式で記載された Template ファイルを読み込む事で、Stack という1 つの単位で(リソースの設定含めて)環境を構築する。利用は無料。
- CloudFormation デザイナーのチェック機能でエラーが出ないかを確認すること
- ユーザーデータを使用するとアプリケーションのデプロイと構成を自動化できる
- AWS上のインフラ構成をコード化して管理したり、ユーザー間で共有することが可能
- パッケージはアーティファクトをS3にアップロードし、アーティファクトのパスが更新されたテンプレートを返す。
- CloudFormation で作成したAWSリソースは、CloudFormation 以外の方法で変更してはいけない
ヘルパースクリプト
| cfn-signal | 【インスタンス作成シグナル】 インスタンスが正常に作成または更新されたかどうかを示すシグナルを CloudFormation に送信する。インスタンスにソフトウェアアプリケーションをインストールして設定する場合、ソフトウェアアプリケーションが使用できる状態になった時にCloudFormation にシグナルを送信できる。 |
| cfn-init | スタックのメタデータを読みこみ、パッケージのインストール、ファイルの書き込みなどのセットアップタスクを実行する。 AWS::CloudFormation::Init キーからテンプレートメタデータを読み取り、次の状況に応じて操作を行う CloudFormation のメタデータの取得と解析 パッケージをインストールする ディスクへのファイルの書き込み サービスの有効化 / 無効化と開始 / 停止 |
| cfn-hup | メタデータの変更を監視し、変更があるたびに指定されたアクションをトリガーするため、テンプレートの変更が適用されることを保証する。リソースメタデータの変更を検出し、変更が検出された場合に、ユーザーが指定した操作を実行するデーモン。これにより、UpdatesStack API アクションを介して、実行中の EC2 インスタンスに構成を更新できる。 |
テンプレート
Cloud Formationの設定ファイル。(JSON/YAMLフォーマット:形式)AWS リソース(またはプロパティ)を作成する際の設計図として使用。
※YAML はインデント(左から右へ寄せた量)で階層を判断する形式。
※YAML は「記法」となる為、プログラミングのような分岐処理や繰り返し処理の記述はできない。
| 論理ID | VPC など AWS リソースにも作成された瞬間に ID(リソース ID)が付与されるので、それと区別するための名称。 |
| AWS:Include | S3上に置かれたファイルの中身をCloudFormationのテンプレート内に読み込むためのマクロ。 |
| Fn::GetAZs | 【組み込み関数】 指定したリージョンのアベイラビリティーゾーンをアルファベット順にリストした配列を返す。 アベイラビリティーゾーンへのアクセス権は顧客ごとに異なり、テンプレート作成者は組み込み関数 Fn::GetAZs を使用することで、呼び出し元のユーザーのアクセス権にうまく適応するテンプレートを作成する。 特定のリージョンのすべてのアベイラビリティーゾーンをハードコーディング(情報の書き換え)する必要はなくなる。 ※組み込み関数はリソースプロパティ、出力、メタデータ属性、更新ポリシー属性で使用できる |
| Fn::ImportValue | 組み込み関数は、同じリージョン内でエクスポートされた値のみインポートできる。 ※エクスポート(オプション) |
[テンプレートセクション]
| セクション名 | 役割・説明 |
|---|---|
AWSTemplateFormatVersion | テンプレートのバージョンを指定(任意) |
Description | テンプレートの説明(任意) |
Metadata | テンプレートに関する追加情報(任意) |
Parameters | スタック作成や更新時にテンプレートへ渡す値。 (例:インスタンスタイプなど) |
Mappings | 条件付きパラメータ値に使用するキーと値の対応表(検索テーブルのようなもの)。Resources や Outputs セクションで Fn::FindInMap 組み込み関数を使って値を取得する(例:リージョンごとのAMI ID) |
Conditions | 条件付きリソース作成やプロパティ設定(例:Prod環境のみ作成) |
Resources | 実際に作成する AWS リソースを定義(必須) |
Outputs | スタック作成後に表示する情報(例:URLやARN) |
Rules | パラメータの検証ルール(例:特定の組み合わせのみ許可) |
Transform | マクロや AWS SAM を使う場合に指定(例:AWS::Serverless-2016-10-31) |
[(一例)基本テンプレート]
| テンプレートの様式バージョン テンプレートの説明 | AWSTemplateFormatVersion: 2010-09-09 Description: sample template |
| カスタマイズ可能な論理ID | Parameters: NameBase: #←これが名前用変数の論理ID Description: this is base name. Type: String Default: Test |
| 作りたいリソース EC2の論理ID | Resources: Ec2Instance1: Type: AWS::EC2::Instance Properties: KeyName: key-raisetekkun ImageId: i-hogehogehogehogeyo InstanceType: t2.micro SecurityGroupIds: - !Ref Sgrp1 |
| ユーザーデータ | UserData: !Base64 | !/bin/bash -xe yum update -y yum install -y httpd service httpd start chkconfig httpd on |
| Tags: – Key: Name Value: !Sub ec2-${NameBase} | |
| スタック内のリソース ID をほかのスタックから呼び出し可能にさせるため | Outputs: |
スタック
【リソース定義】
関連リソースはスタックと呼ばれる単一のユニットとして管理できる AWS リソースのコレクション。
※「承認されたテンプレートの強制」や「開発者によるテンプレートの制限」を実装する機能はない
・スタックを作成、更新、削除することで、リソースのコレクションを作成、更新、削除できる。
・「エラー時のロールバック」機能が有効であると、失敗しても作成されずロールバックする。
スタックの更新には2つの方式がある。
| 直接更新 (in place) | 変更を送信するとCloudFormationによって即時にデプロイ。 更新を迅速にデプロイするには直接更新を使用する。 |
| 変更セット(blue-green) | 更新されたスタックなど実際に実装する前に検証できる。影響度を確認するためのスタック。そのため、安心したスタック更新が可能。スタックの変更案が実行中のリソースに与える可能性がある影響を確認できる。 |
- スタックセット
1つのテンプレート内に AWS リソースの設定を定義して、複数の AWS アカウントやリージョンにスタックを作成・管理、展開することができる。
スタックセットを定義したら、スタックセットはリージョンのリソースである。
※自動デプロイを有効にすると、今後ターゲットの組織または組織単位(OU)に追加されるアカウントにStackSetsが自動デプロイを行う - スタックポリシー
重要なスタックリソースを保護して、意図しない更新でリソースが中断されたりするのを防ぐJSONドキュメント。
●カスタムリソース
【使用できないリソース】
CloudFormationのリソースタイプとして使用できないリソースをプロビジョニングするためのカスタムリソースの作成をサポートする。
テンプレートにカスタムのプロビジョニングロジックを記述し、ユーザーがスタックを作成、更新(カスタムリソースを変更した場合)、削除するたびにそれを実行。リソースは、カスタム リソースを使用して含めることができる。この方法により、すべての関連リソースを 1 つのスタックで管理できる。
LambdaとZipFikeを使用するカスタムリソースはインラインの nodejs リソース構成を可能にする。
[EC2のAMI IDを自動取得する方法]
CloudFormationテンプレートでEC2インスタンスを作成する際、通常は手動でAMI(Amazon マシンイメージ)IDを指定する必要があります。AMI IDは、インスタンスタイプやリージョン、またはソフトウェアの更新によって頻繁に変わるため、その都度テンプレートを修正する必要がありました。しかし、カスタムリソースとAWS Lambdaを使うことで、テンプレートの実行時に最新のAMI IDを自動で取得できるようになります。これにより、AMI IDのマッピングを手動で管理する手間が不要になる。
●クロススタック
スタック間でリソース情報を共有する仕組み。1つのスタックで作成したリソース(例:VPCやSubnet)を、別のスタックから参照できます。
| ステップ | 内容 |
|---|---|
| Export | スタックAで Outputs に値を定義し、名前を付けてエクスポート |
| Import | スタックBで |
・複数のスタックにリソースを分散させ、それらを相互に連携させる方法。
・リソースを1つの巨大なテンプレートに詰め込まず、機能単位で分割して再利用性や保守性を向上。
[ネストされたスタック]
他のネストされたスタックが含まれているため、スタックが階層を成す構造になる。ルートスタックはネストされたすべてのスタックが最終的に属する最上位スタック。さらにネストされたスタックにはそれぞれ、直接の親スタックが存在する。
ネストされたスタックを使用して共通コンポーネントを宣言することがベストプラクティスとみなされている。
[参照の仕組み]
・出力(Output) を使って、スタック A が持つリソースの情報を外部に公開。
・スタック B が、その出力を ImportValue 関数で参照し、スタック A のリソースを利用。
[ 例 ]ネットワークスタックとアプリケーションスタック
- ネットワークスタック → VPC・サブネット・セキュリティグループなどを定義。
- アプリケーションスタック → ネットワークスタックのサブネットやセキュリティグループを参照して Web アプリを構築。
- この方法により、アプリ担当者はネットワークの詳細を気にせずに利用可能。
ドリフト
【乖離】CloudFormationテンプレートとそれによって展開したリソースとの間の乖離(変更点)。スタックでドリフト検出オペレーションを実行すると、スタックが予想されるテンプレート設定からドリフトが発生しているかを検証される。
属性
| DeletionPolicy | 【削除対策】 スタックが削除された際にリソースを保持またはバックアップができる。 ・Retain リソースの削除防止。スタックが削除された際にリソースを保持するには、そのリソースに対して Retain を指定する。 ・Snapshot リソース削除前にスナップショットを作成する。 |
| DependsOn | 【依存関係】 特定のリソースが他のリソースに続けて作成されるよう(依存関係)に指定できる。依存関係のエラーが発生した場合、テンプレート内の他のリソースに依存するリソースに DependsOn属性を追加する。 |
| Creation Policy | 【作成管理】 CloudFormationが指定数の成功シグナルを受信するかまたはタイムアウト期間が超過するまでは、ステータスが作業完了にならないようにする属性。 ・Wait Condition リソースの作成を詳細に調整できる。 |
| UpdatePolicy | 特定のリソースに対する更新処理の挙動を制御する。この仕組みにより、CloudFormation スタックの更新時にインスタンスの置き換えやローリング更新を制御でき、運用中のサービスへの影響を最小限に抑えながら変更を反映することが可能。 |
[(UpdatePolicy)対象リソースと適用可能なポリシー]
| 対象リソース | 利用可能なポリシー |
|---|---|
AWS::AutoScaling::AutoScalingGroup | AutoScalingReplacingUpdate / AutoScalingRollingUpdate / AutoScalingScheduledAction |
AWS::ElastiCache::ReplicationGroup | UpdatePolicy |
AWS::Elasticsearch::Domain | UpdatePolicy |
AWS::Lambda::Alias | UpdatePolicy |
パラメーター
- NoEcho
値をtrueに設定すると、機密データのパラメーターをマスクできる。パラメーター値はアスタリスクでマスクされる。データーベースのパスワードなどに有効。呼び出された時にパスワードが表示されないようにすることができる。
●リクエストパラメータ
「カスタム名」をもつIAMリソースがある場合は、CAPABILITY_NAMED_IAM を指定する必要がある。
| 項目 | CAPABILITY_IAM | CAPABILITY_NAMED_IAM |
|---|---|---|
| 機能 | IAMリソースを作成・更新する際に使用される機能 | カスタム名をもつIAMリソースを作成・更新する際に使用される機能 |
| 使用用途 | 自動生成された名前のIAMリソースの作成 | 明示的に指定した名前を持つIAMリソースの作成 |
| 適用範囲 | 通常のIAMリソース(ロール、ポリシーなど) | カスタム名を持つIAMリソース(カスタムロール、カスタム下ポリシーなど) |
| 指定が必要なシナリオ | 一般的なIAMロールやポリシーの作成 | 特定の名前をもつIAMロールやポリシーの作成 |
| エラーメッセージの発生 | カスタム名を指定したIAMリソースを作成しようとした場合にエラーが発生 | 正しい機能が指定されていれば、エラーは発生しない |
エラー
・InsufficientInstanceCapacity エラー
AZ内の「インスタンス容量の不足」を意味する。インスタンスを起動したり、停止したインスタンスを再起動したりする際にこのエラーが発生する場合、使用するAWS に十分なオンデマンドキャパシティーがないことを意味する。
・選択されたインスタンスタイプが一時的に利用できない。
・特定のAZにおいてインスタンスの容量不足が発生している。
補助サービス
●CloudFormation Hooks
CloudFormation スタックの操作(作成・更新・削除)前に カスタムロジックを実行できる仕組み。スタック、リソース、変更セット、Cloud Control API などを対象にスタック操作前、リソース作成前などにリソースの構成を事前に検証し、非準拠な操作を防止できる。
[CodePipeline を使用した継続的デリバリー]
CloudFormationはCodePipelineと統合されている。
[参考公式サイト]
[既存リソースをCloudFormation 管理に取り込む]
CloudFormation 管理外のAWSリソースを作成した場合、resource import を使用して既存のリソースをCloudFormation 管理に取り込むことができる。
[スタックへ既存リソースをインポート]
[参考サイト]
●CloudFormation サービスロール
AWS CloudFormation にユーザーに代わってスタック内のリソースを呼び出すアクセス権限を許可する IAM ロール。スタックリソースの作成、更新、または削除を許可するIAMロールを指定できる。デフォルトの場合、CloudFormationはユーザー認証情報からスタック操作に対して作成される一時的セッションを使用する。
●Mapping
【キーと値の関連性】
キーと名前付きの一連の値とが対応付けられる。たとえば、リージョンに基づく値を設定する場合、リージョン名をキーとして必要な値を保持するマッピングを作成する。具体的なリージョンごとに必要な値を指定する。
●Cloud Former
【JSONへ変換する】現在の構成をJSONフォーマットに変換でき、構成のコピーや雛形の作成が楽になる。アカウントに既に存在するAWSリソースからCloudformationテンプレートを作成するテンプレート作成用のβツール。アカウントで実行中のサポートされているAWSリソースを選択すると、CloudFormerはS3バケットにテンプレートを作成する。
●SAM
【テンプレート集】※SAM:Serverless Application Model
CloudFormationの拡張機能とされる。サーバーレスアプリケーションの開発やデプロイを簡単にするための簡略化された独自のモデリング構文を提供する。YAMLを使用して、サーバレスアプリケーションのするLambda関数、API、データベース、イベントソースマッピングをモデリング。
・迅速に記述可能な構文で関数、API、DB、イベントソースマッピングを表現できる。
・デプロイ中、SAMがSAM構文をCloudformation構文に変換および拡張することで、サーバーレスアプリケーションの構築を高速化することができる。
(CloudFormationの拡張機能であり、CloudFormationの信頼性の高いデプロイ機能を利用できる)
・SAM CLI を使用して、開発ライフサイクルの作成、構築、デプロイ、テスト、モニタリングの各フェーズを通じてサーバーレスアプリケーションを管理
[参考]
[SAMについて]
連携サービス
【併用:Code Commit】
CloudFormationのテンプレートをCodeCommitでバージョンなど管理できる。
①CodeCommitリポジトリを作成し、そこにCloudFormationテンプレートファイルを保存。
②CloudFormationのスタック作成時に、テンプレートの場所としてCodeCommitリポジトリのURLとファイルパスを指定
【併用:Auto Scaling】
CloudFormationでAuto Scalingグループの起動設定(Launch Configuration)を更新方法について。
要するに、起動設定を変更したい場合は、既存のものを上書きするのではなく、新しい設定を作成して置き換え、必要に応じてローリングアップデートを行うことが重要。
主な内容は以下の通りです。
- 起動設定そのものは作成後に変更できませんが、新しい起動設定を作成して、Auto Scalingグループに適用することで更新できます。
- AWS CloudFormationで起動設定を更新すると、古いリソースが削除され、新しいリソースが作成されます。
- 新しい起動設定を適用しても、既存のインスタンスは変更されず、古い設定のまま維持されます。新しいインスタンスのみが新しい設定で起動します。
- AutoScalingRollingUpdateポリシーを使うと、Auto Scalingグループ内のインスタンスを段階的に新しいインスタンスに置き換えることができます。これにより、サービスへの影響を最小限に抑えながら更新が可能です。
CDK

【コードで環境構築】※Cloud Development Kit (CDK)
既存のスクリプトを使用して CloudFormation テンプレートを作成するため、CloudFormation を学習する必要がない。プログラミング言語を使ってクラウドインフラをコードで定義・管理できるフレームワーク。テンプレートやスクリプトに頼らず、より柔軟で再利用可能な構成が可能。
- 対応は AWS のみではある。
- 複数のプログラミング言語で記述が可能。
- コードから CloudFormation テンプレートが生成され、実際の作成処理はCloudFormation で行われる。
- コンストラクトという仕組みで、ベストプラクティスに基づく構成が簡単に作れる。
- 背後では CloudFormation が使われ、安全にリソースをデプロイできる。
- 独自のカスタムコンストラクトを作成・共有することで、開発の効率を向上できる。
- Terraform(cdktf) や Kubernetes(cdk8s) にも対応し、多様な環境で利用可能。
アサーションモジュール
CDKのアサーションモジュール(aws-cdk-lib/assertions)は、AWS Cloud Development Kit(CDK)で作成したスタックに対してユニットテストを行うための専用ライブラリ。これは、CDKが生成するCloudFormationテンプレートの内容を検証するために使われる。
[概要]
| 項目 | 説明 |
|---|---|
| 主な目的 | CDKスタックから合成されたCloudFormationテンプレートに対して、リソースの存在やプロパティを検証する |
| 使用場面 | リファクタリング時の回帰テスト、TDD(テスト駆動開発)、構成の正当性確認 |
| 主なクラス | Template(スタックをテンプレートとして扱う) |
| 主なメソッド | hasResourceProperties(), resourceCountIs(), resourcePropertiesCountIs() など |
Elastic Beanstalk

【APPデプロイの自動化】※Beanstalk:豆の木
コードのアップロード、容量のプロビジョニングや負荷分散、アプリケーションのヘルスモニタリングなどのアプリケーションをデプロイするために必要なインフラストラクチャ(サーバーやネットワーク)やリソースの設定をコードを書くだけで自動構築してくれる。また必要に応じてアプリケーションのスケールアップ、ダウンを実施するため、運用面での管理は不要となる。
・モニタリングやセキュリティーに必要なパッケージのみ使用するため、不要なコストを削減できる
・WEBアプリケーションのデプロイを容易にする、タスク時間の長いワークロードの展開に有効
・本サービスの環境内にはEC2インスタンスを管理するAuto Scalingグループが含まれている
・開発言語は、Java / PHP / Python / Python(with Docker) / Node.js / Go / NET / Ruby
・OSとデーターベースの管理ができる
[注意点]
・アプリケーションのバージョンを更新時にインプレース更新を実行するため、アプリケーションはわずかな期間、ユーザーに利用不可になることがある。
[ログ保存機能]
・アプリケーションファイルと、オプションでサーバーログファイルが S3 に保存される。
・サーバーのログファイルを 1 時間おきに S3 にコピーするように設定することもできる。
[通知機能]
通知の仕組み
- デプロイの状態変化や問題発生時に、指定されたメールアドレスへ自動で警告が送信されます。
- これにより、アプリケーションチームがデプロイ失敗を即座に把握できるようになります。
作成機能
●設定ファイル(.ebextensions)
環境を設定し、環境に含まれる AWS リソースをカスタマイズできる。この設定ファイルを .ebextensions というフォルダ内に配置してアプリケーションソースバンドルにデプロイする。
※Webサーバ構成:(ELB+AutoScaling+EC2) / Batchワーカー構成:(SQS+AutoScaling+EC2)
※ファイル拡張子を .config とするYAML 、 JSON 形式のドキュメント。
- BlockDeviceMappings
インスタンスにブロックデバイスを追加できる。
●コンソール
【リソース設定】
環境とそのリソースに関する多数の設定オプションを表示し、デプロイ時の環境動作のカスタマイズ、追加機能の有効化、環境作成時に選択したインスタンスタイプやその他の設定を変更することができる。
●共有機能
開発者は単にそのアプリケーションをアップロードするだけで、展開できる。複数のユーザーや企業が同じアプリケーションを共有し、各々でカスタマイズすることが可能。
デプロイ機能
●ワーカー環境 SQS デーモン(※Elastic Beanstalk 内)
長期間実行される可能性があるタスク(例えば、画像処理やEメール送信、ZIP生成など)は、ワーカー環境にオフロードさせることができる。
| ワーカー環境 | ・Elastic Beanstalk から提供されるプロセスデーモンを実行する。 ・アプリケーションが成功を返さない場合、プロセスデーモンはメッセージをキューに戻す。 ・Auto Scalingグループ、1 つ以上のEC2 インスタンスおよび IAM ロールが含まれている。 ・ワーカー環境にSQS キューがない場合、Elastic BeanstalkによってSQS キューが作成され、プロビジョニングされる。 |
| デーモン | ・デーモンは定期的に更新され、機能の追加とバグの修正が行われる。 ・デーモンの最新バージョンを取得するには、プラットフォームバージョンに更新。 |
[オフロード]
ある特定のデータ処理に特化したハードウェアをコンピュータに装着し、CPUの処理を肩代わりして負荷を軽減し、システム全体の処理性能を向上させる。
[200 OKレスポンスについて]
- ワーカー環境内のアプリケーションが 200 OK レスポンスを返す。
①リクエストを受信して正常に処理したことを確認する。
②デーモンが DeleteMessage 呼び出しを Amazon SQS キューに送信し、そのメッセージをキューから削除。 - アプリケーションが 200 OK 以外の応答を返した場合
①設定済みの Error Visibility Timeout 期間の経過後にメッセージをキューに戻す。
②応答がない場合、処理中の別の試行でそのメッセージを使用できるように、InactivityTimeout 期間の経過後にメッセージをキューに戻す。
デプロイの種類
| All at once | (既存のインスタンス) 同時に全ての既存インスタンスに新しいバージョンをデプロイするポリシー。最も迅速なデプロイ方法。環境内のすべてのインスタンスは、デプロイが実行される間、短時間サービス停止状態になる。 |
| Rolling | (既存のインスタンス) バッチに新しいバージョンをデプロイするポリシー。複数インスタンスに対し、少しづつデプロイ。デプロイが終わると全てのインスタンスでデプロイしたバージョンのアプリケーションが起動。ダウンタイムを回避できるが、デプロイ時間が長い。サービスの完全停止を防ぐアプリケーションのログ保持向き。 |
| Rolling with additional batch | (既存・新規のインスタンス) デプロイの対象となるインスタンス分、新しくインスタンスを起動させて、100%の状態を保つ。インスタンスがサービス停止する前に、インスタンスの新しいバッチを起動するように環境を設定してデプロイ中に総容量を維持できる。 |
| Immutable | (変更不可):新規のインスタンス 低速のデプロイ。常に新しいアプリケーションバージョンを新しいインスタンスにデプロイ。失敗しても迅速に安全にロールバック可能。(Blue/Greenは新しく環境を立てるが、Immutableは既存環境に新規インスタンスを構築・デプロイ) |
| Traffic splitting | 残りのトラフィックを古いアプリケーションバージョンで処理され続けるようにする。(※Canaryリリース形式) |
| Blue/Green | (Swap Environment Deployment) 新バージョンのアプリケーションを公開するにあたり、現バージョン(ブルー)と新バージョン(グリーン)の両方を並行して稼働させ、切り替えにより公開する。仕組みとして、個別の環境に新しいバージョンをデプロイして、2つの環境のCNAMEを入れ替え、すぐに新しいVerにトラフィックをリダイレクト。 ・切り替えは一瞬でできるため、稼働停止時間なしに公開できるのがメリット。 ・1つの環境で2つの異なる環境層をサポートすることはできない。 ・ワーカー環境層とウェブサーバー環境層はそれぞれAuto Scalingグループを必要とする。 ・ElasticBeanstalk は環境ごとに一つのAuto Scalingグループしかサポートしていない。 ●環境URLのスワップ 新旧環境間でCNAMEレコードを交換する機能を提供する。これにより、新しい環境にデプロイされたアプリケーションにユーザーのトラフィックを素早くかつ無停止でリダイレクトすることができる。 |
アプリケーションバージョンライフサイクル
Elastic Beanstalk コンソールまたは EB CLI を使用してアプリケーションの新しいバージョンをアップロードするたびに、アプリケーションバージョンが作成される。使用しなくなったバージョンを削除しないと、AWSクォータ(制限)に到達し、アプリケーションの新しいバージョンを作成できなくなる。
[領域管理]
ライフサイクルポリシーを使って、古いバージョンを削除するか、アプリケーションの合計数が指定した数を超えた場合にバージョンを削除すること。デフォルトでは、データの損失を防ぐために、バージョンのソースバンドルを Amazon S3 に残す。ソースバンドルを削除すると、領域を節約できる。
[参考]
●ソースバンドル
ソースのパッケージとして機能する。アップロードされたソースバンドルはElasticBeanstalk内で管理され、以前のバージョンに戻すことができる。
ウェブアプリケーションを Docker コンテナからデプロイ
Elastic Beanstalkを使えば、Dockerの柔軟性とAWSの運用自動化を組み合わせて、効率的にアプリケーションを展開できる。
| Dockerコンテナの利点 | ・独自のランタイム環境を定義可能 ・他プラットフォームでサポートされない言語やツールも使用可能 ・必要なソフトウェアや設定情報をすべて含む自己完結型 |
| Elastic Beanstalkの機能 | ・コンソールで定義した環境変数をコンテナに渡せる ・容量のプロビジョニング、負荷分散、スケーリング、状態監視など自動化 |
[参考公式サイト]
- オプション:Swap Environment URLs
既存のアプリケーション環境(ブルー環境)と新しい環境(グリーン環境)のURLが交換される。これにより、トラフィックは新しい環境にシームレスに移行され、古い環境はスタンバイ状態になる。
[container_commandsキー]
デプロイ時のタイミングに応じて適切に処理が実行されるように構成できるという内容。
アプリケーションのソースコードに影響を与えるコマンドを記述できる。アプリケーションおよびウェブサーバーの設定後、アプリケーションバージョンアーカイブが展開された後に実行される。アプリケーションのバージョンがデプロイされる直前にコマンドが走る。その他のカスタマイズ操作は、アプリケーションのソースコードが展開される前に実行される。
[Dockerコンテナの活用]
- Dockerを使うことで、独自のランタイム環境を構築できる。
- 他のプラットフォームでサポートされていない言語やツール・パッケージマネージャも使用可能。
- コンテナは自己完結型で、必要な設定やソフトウェアをすべて含む。
[環境変数の扱い]
- Elastic Beanstalk コンソールで定義されたすべての環境変数はコンテナに渡される。
[インフラの管理自動化]
- Dockerコンテナを用いた Elastic Beanstalk では、以下のようなインフラ管理が自動化される
- 容量のプロビジョニング
- 負荷分散
- スケーリング
- アプリケーションの状態監視
[他のAWSサービスとの統合]
- VPC、RDS、IAM などの AWS サービスとも柔軟に統合可能。
全体として、Elastic Beanstalk × Docker の組み合わせにより、高い柔軟性と自動化された管理の両立が可能になることを示している。
[引用元サイト]
連携サービス
【併用:外部の Amazon RDS for MySQL】
アプリケーションのスケーリングとデータベースの持続性を別々に管理できる。Elastic Beanstalk 環境が再構築されても、外部 RDS インスタンスは影響を受けずにデータを保持できる。これは、データベースに保存されたデータが重要で、アプリケーションスタックの状態に関係なく保持される必要があるという要件に直接対応できる。
【Amazon SNSとの連携】
環境の作成時や後からでも、通知先のメールアドレスを指定することで、エラーやヘルス状態の変化をメールで受け取れます。Elastic Beanstalkは、Amazon SNS (Simple Notification Service) を使って、環境に影響する重要なイベントを通知します。
Ops Works

【ミドルウェアの自動化】
Chef や Puppet(構成定義ファイル)に基づいて、サーバーのさまざまな設定を自動的に行うソフトウェア、設定管理サービス。
・ソフトウェアの設定
・パッケージのインストール
・データベースのセットアップ
・サーバーのスケーリング
・コードのデプロイが自動的
・サポート範囲は、EC2、EBS ボリューム、Elastic IP、CloudWatch メトリクスなど、アプリケーション志向のリソースに限られる
●自動ヒーリング
インスタンスが Amazon EC2 ヘルスチェックに合格した場合でも、スタック内にある異常なインスタンスまたは失敗したインスタンスを再起動する。スタックのレイヤー設定では、自動ヒーリングがデフォルトで有効化されている。
スタック
【管理枠】
OpsWorksの管理対象をまとめたコンポーネントで、属する全員インスタンスの構成を管理する。
※スタック(大枠)の中にレイヤー。レイヤー内に各インスタンス(インスタンスにOpsWorksのエージェント必須)
⇒別のリージョンにコピーできる(DR環境対策)
| スタックインスタンス | 【スタックのリンク】 ・スタックインスタンスはひとつのスタックセットのみ関連付けられる。 ・リージョン内のターゲットアカウントのスタックへのリファレンス(参考)。 ・スタックなしで存在できる。 ・スタックの作成失敗理由を保持する。 |
| レイヤー | 1つ以上の Layer を追加することにより、スタックのコンポーネントを定義する。 |
Chef(シェフ)
【注文ファイル】
ファイルに記述した設定内容に応じて自動的にユーザーの作成やパッケージのインストール、設定ファイルの編集などを行うツール。「Cookbook(クックブック)」や「Recipe(レシピ)」と呼ばれる設定ファイルの再利用がしやすい構造になっている点が特徴。Ruby と Erlang で記述。
●Chef ログ
特にレシピをデバッグする際の主要なトラブルシューティングリソースの 1 つ。レシピが失敗した場合、ログには Chef スタックトレースが含まれる。Chefログを使用して失敗したレシピをデバッグ。実行はデバッグモードであり、ログには Chef 実行の詳細(stdout や stderror に送信されたテキストなど) が含まれる。OpsWorksスタックは各コマンドの Chef ログをキャプチャし、各インスタンスの最新 30 個のコマンドのログを保持可能。
カスタムクックブック
Chefを使って、サーバーにどんな設定をするかを細かく指定することができる。
[カスタムクックブックの有効化]
「Use custom Chef cookbooks」オプションを有効にすると、カスタムクックブックの使用が可能になる。
[リポジトリ情報の設定]
クックブックの保存先(Gitリポジトリなど)のURLや**認証情報(パスワードなど)**を設定する必要がある。
[自動インストール]
スタック設定後、新しく起動するすべてのインスタンスには、カスタムクックブックが自動でインストールされる。
[更新コマンドの利用]
すでに存在するインスタンスには、Update Custom Cookbooks コマンドを実行することで、新しいクックブックや更新されたクックブックを適用できる。
[バージョン互換性の確認]
使用するカスタム/コミュニティクックブックが、スタックで採用されているChefのバージョンと互換性があることを事前に確認する必要がある。
Configureイベント
OpsWorks スタック内で以下のような変更が起きたとき、すべてのインスタンスで Configure イベント がトリガーされる。
- インスタンスがオンライン状態になった/オンライン状態から外れた
- Elastic IPアドレスの関連付け/解除
- ELB(Elastic Load Balancing)の Layer へのアタッチ/デタッチ
configure stack commandを使えば、手動でも Configure イベントを起こすことができる。
[イベント発生例]
・インスタンス A・B・C が稼働中に、新しいインスタンス D を追加すると、A~Dすべてで Configure イベントが発生。
・D のセットアップ完了後に A を停止すると、残りの B・C・D に再び Configure イベントが発生。
[Configureレシピの役割]
レイヤーごとに定義された Configure レシピが実行され、最新のオンライン構成に基づいて設定ファイルを再生成。
ベストプラクティス: アクセス権限の管理
・リソースやアクションの制限により、不要なアクセスを防止
・ユーザーごとに個別のIAMユーザーを作成
・必要な操作だけを許可する最小権限のポリシーをアタッチ
[引用元サイト]
APP Runner

【自動デプロイ】
・ソースコードがコードリポジトリにプッシュされる
・新しいコンテナイメージバージョンがイメージリポジトリにプッシュされる
・ソースコードまたはコンテナイメージから、ウェブアプリケーションをスケーラブルかつセキュアにデプロイ可能。
・ユーザーはインフラの知識や構成不要で、迅速・簡単・コスト効率の高いアプリケーション実行環境を利用できる。
・フルマネージドな運用、高パフォーマンス、オートスケーリング、セキュリティが提供される。
下記イベントに対し、イメージリポジトリに直接接続して、プッシュされたコードを自動的にデプロイまたは配信する。
[インテグレーションとCI/CD]
・コードまたはイメージリポジトリ(例:GitHub、ECRなど)に直接接続可能。
・自動的に統合と配信のパイプライン(CI/CD)を構築。
Batch

【バッチ自動化】
開発者、科学者、エンジニアは、数十万件のバッチコンピューティングジョブをAWSで簡単かつ効率的に実行。コンピューティングリソース(CPUやメモリ最適化インスタンスなど)を自動的にプロビジョニングし、ワークロードの量と規模に基づいてワークロードのディストリビューションを最適化する。
・ジョブを実行するためのバッチコンピューティングソフトウェアやサーバークラスターを扱う必要がなくなる。
※Lambda関数をトリガーにすることはできない

Back up

【リソースのバックアップ】
組織内の Backup ジョブを管理(バックアップ保護)およびモニタリングできるサービス。(Organizationsの管理アカウントから実施可能)
大規模なデータセットのバックアップには不向き。オンプレミスのデータを直接同期する仕組みを持っていない。
・オンプレミスのVMのバックアップを作成するためには、BackUpゲートウェイが必要
[バックアップ]
・バックアップポリシーを設定することでサービス全体のアプリケーションのデータをバックアップ。
・復元されたインスタンスは、すべてのインスタンスメタデータを含め元のインスタンスと同じ。
・デフォルトの動作は「再起動なし:no-reboot」でEC2バックアップを取得する。
- クロスアカウント管理機能
バックアップポリシーを一元管理できるだけでなく、AWS Organizations の AWS アカウント間で、バックアップと復元、コピージョブをモニタリングできる。
Back Up プラン
どのリソースをいつどのようにバックアップするかを定義する。JSON でポリシーのように設定することもできれば、GUI で設定することもできる。
[リソース割り当て]
どのリソースに対してバックアップを実行するかは、リソースの割り当て(Resource assignment)によって定義する。バックアップ対象となる「リソースの指定」、対象リソースのバックアップの「スケジュール」を指定する。
一つのバックアッププラン内で複数のリソースの割り当てを設定できる。
●Backupボールト
バックアップを整理するために、EC2 のバックアップである AMI 、RDS のバックアップであるスナップショットなどをまとめて管理する。
※S3 バケットの継続的バックアップと定期的バックアップは、どちらも同じバックアップボールト
- 復旧ポイント
個々のバックアップは復旧ポイントという単位で管理される。復旧ポイントは、各サービスのバックアップと 1 対 1 で紐づけられる。 - アクセスポリシー
復旧ポイントに対するアクセス制御を行う。特定のリソースタイプのバックアップのみ参照を許可したり、特定のユーザーに対してのみリストアを許可するといったことが可能となります。
Back Up vs Data sync
Backup は「AWSリソースの保護」向け、DataSync は「ファイルベースの転送・バックアップ」向け。
- Backup:EC2やRDSなど、AWSサービスの状態を丸ごとバックアップ・復元したいときに最適。
【例】EFS を毎晩自動でスナップショット取得 → 障害時に復元 - DataSync:オンプレミスや他リージョンのストレージから、ファイル単位で柔軟にバックアップ・同期したいときに便利。
【例】DataSync:社内NASのログを毎晩 S3 にコピー → 分析や保管用
| 項目 | AWS Backup | AWS DataSync |
|---|---|---|
| 目的 | AWSリソースのバックアップと復元 | ストレージ間のデータ転送・同期 |
| 対象 | EBS, RDS, DynamoDB, EFS, FSx など | オンプレ/NFS/SMB → S3/EFS/FSx など |
| スケジュール | ポリシーで自動化(毎日◯時など) | cron式で柔軟に設定可能 |
| 復元機能 | バックアップから直接復元可能 | コピー先から手動で復元 |
| クロスリージョン対応 | 一部対応(EFSなど) | 柔軟に対応(S3→S3など) |
| ユースケース | AWS内のリソース保護 | オンプレ→AWS、AWS間の転送・バックアップ |
Control Tower

【安全なマルチアカウントのセットアップ】
マルチアカウント環境におけるガバナンス、コンプライアンス、セキュリティのベストプラクティスを自動化し、中央管理を容易にする。(検出処理が主)必要なサービスとネットワークを備えたアカウントを作成できる。
安全なマルチアカウント AWS 環境のセットアップと管理。新規または既存のアカウント設定の統制できる。 組織のセキュリティとコンプライアンスのニーズを維持しながら、ユーザーに代わって複数の AWS サービスをオーケストレーションすることで、 AWS エクスペリエンスを簡素化する。
・適切に設計されたマルチアカウント環境を 30 分以内にセットアップ。
・組み込みのガバナンスで AWS アカウントの作成を自動化。
・事前に構成されたコントロールを使用して、ベストプラクティス、標準、規制要件を適用。
・サードパーティーソフトウェアを大規模にシームレスに統合して、AWS 環境を強化。
[画像引用元]
機能性
●Landing Zone
【最適なマルチアカウント作成】
Well-Architected によるAWSのベストプラクティスに基づいたセキュアなマルチアカウント AWS 環境を提供する仕組みの総称。 ID、フェデレーティッドアクセス、アカウント構造のためのベストプラクティスのブループリント(テンプレートと同等)を使用して、新しい ランディングゾーンのセットアップを自動化。ランディングゾーンを展開することで環境内のAWSアカウントのリソースに対して一元的に 管理/監視が可能になる。
●Account Factory
【組織垢自動配置】
組織内の新しいAWSアカウントを自動的に作成・設定・管理するための仕組み。設定可能なアカウントテンプレートとして、Control Tower の事前承認済み アカウントブループリントとデフォルトのリソース、設定、または VPC 設定を使用して、新しいアカウントのプロビジョニングを標準化するのに役立つ。
| 機能 | 説明 |
|---|---|
| アカウントの自動作成 | AWS Organizations配下に新しいメンバーアカウントを作成可能 |
| ガードレールの自動適用 | CloudTrailやAWS Configなどの監査・ログ機能を自動設定 |
| OU(組織単位)への配置 | 作成したアカウントを指定したOUに割り当て可能 |
| SSOユーザーの設定 | AWS IAM Identity Center(旧SSO)と連携してユーザーを発行 |
| VPC構成の選択 | 必要に応じてVPCを自動作成(無効化も可能) |
| カスタマイズ対応 | Account Factory Customization (AFC) により、独自のCloudFormationテンプレートを適用可能 |
[主な機能と特徴]
・事前に承認されたアカウント設定に加えて、独自のカスタムアカウントリソースと要件を定義して実装もできる。
・事前に承認されたネットワーク設定と AWS リージョンの選択を使用して Account Factory を設定することで、ビルダーが新しいアカウントを 設定してプロビジョニングするためのセルフサービスを有効にする。
●About Account Factory for Terraform (AFT)
Terraform 用 Account Factory などの Control Tower ソリューションを 利用して、Terraform の Control Tower が管理するビジネスポリシーとセキュリティポリシーを満たすアカウントのプロビジョニングとカスタマイズを 自動化してからエンドユーザーに配信できる。
[Account Factory for Terraform (AFT)との違い]
| AFT | Terraformを使ってコードベースでアカウント作成・管理が可能。CI/CDパイプラインとの統合にも向いている。 |
| Account Factory | GUIベースで操作。Control Towerコンソールから利用。 |
●CfCT(Customize Control Tower)
新しいアカウント作成時に、カスタムリソースや設定を自動的に適用できる仕組み。AWS CodeCommit リポジトリに保存された CloudFormation テンプレートや SCP(Service Control Policies)JSON ドキュメントを使って、カスタムセットアップを実行。
[動作の流れ]
- ユーザーが新しいアカウントを作成。
- OU(組織単位)やアカウントに対して、CloudFormation テンプレートや SCP を自動適用。
- アカウント作成後に、自動でカスタムリソースがデプロイされる。
[適用可能なカスタマイズ例]
・CloudFormation によるリソース作成(例:VPC、IAM ロール、ログ設定など)
・SCP によるアクセス制御ポリシーの適用
・AWS Config や CloudTrail の設定強化
●包括的なコントロール管理
最小特権の適用、ネットワークアクセスの制限、データ暗号化の適用など、最も一般的な制御目的を果たすために必要な制御の定義、 マッピング、管理にかかる時間を短縮するのに役立つ。
[コントロール(ガードレール)のカテゴリ]
| 必須のガードレール | Control Tower が作成する重要なリソースの整合性とセキュリティを守るために存在する。無効化できない。 Control Tower の運用に不可欠な保護機能で、特に「Security OU」に適用される。 ・ログアーカイブ用の S3 バケットの暗号化設定の変更を禁止 ・バケットポリシーやライフサイクル設定の変更を禁止 ・ログバケットの削除を禁止 ・パブリックアクセスの検出 |
| 強く推奨されるガードレール | セキュリティ違反の兆候を早期に検出し、対応を促すためのもの。デフォルトでは無効だが、有効化を推奨。ベストプラクティスに基づいたセキュリティ・運用管理の強化を目的としている。 ・ルートユーザーの使用を検出 ・暗号化されていないリソースの検出(例:S3バケット、EBSボリューム) ・パブリックアクセスが有効なリソースの検出 ・CloudTrail の無効化を検出 |
[コントロール(ガードレール)種類]
| 予防 | ポリシー違反につながるアクションを禁止するため、アカウントはコンプライアンスを維持する。 予防コントロールのステータスは適用または無効である。 |
| 検出 | ポリシー違反など、アカウント内のリソースの非準拠を検出し、ダッシュボードを通じてアラートを提供する。 検出コントロールのステータスは、クリア、違反、無効 |
| プロアクティブ | プロビジョニング前にリソースをスキャンし、リソースがそのコントロールに準拠していることを確認する。準拠していない場合はプロビジョニングされない CloudFormation フックによって実装され、CloudFormationによってプロビジョニングされるリソースに適用される。 ステータスは、PASS(合格)、FAIL(不合格)、SKIP(スキップ) |
ワークフロー
SWF
※SWF: Simple Workflow Service
クラウド内の完全マネージド型の状態トラッカーおよびワークフローシステム。
商品の発注/請求処理のワークフロー(処理の流れ)のような、重複が許されない厳密に一回限り順序性が求められる処理を定義する。
タスクの保管、実行可能になったタスクのワーカーへの割り当て(1回のみで重複しない)、およびタスクの進行状況の監視も行う。
| ワーカー | SWFと相互作用してタスクを受け取り、そのタスクを処理して結果を返すプログラム。 |
| ディザスター | 複数のタスクの連携を制御するプログラム。 |
※EC2インスタンスを利用したサーバーベースの機能であるためサーバーレスオーケストレーションを提供しない
Step Functions

複雑な処理の流れを“見える化”しながら、確実に実行管理できるツール。グラフィカルなコンソールを使って、複数のAWSサービスや機能を連携させるサーバーレスワークフローを作成・管理して、プロセス処理を実行するアプリケーションを構築できる。 ワークフローは一連のステップで構成され、ステップの出力が次ステップへの入力になる。
※SWFと違い、可視化できる
※ストリームデータのリアルタイム処理に不要な複雑性を追加するため、不適切
・各ステップは自動的にトリガー、追跡される。
・ステップの状態が記録されるため、問題の診断やデバッグが容易。
・エラーがあれば再試行されるため、アプリケーションが意図したとおりの順序で実行される。
・失敗したステップのみを再処理することが可能。
※人間による操作を必要とするような長時間実行される、半自動化されたワークフローを作成することもできる。したがって、ワークフローに手動アクションを必要とするいくつかのタスクが存在する可能性がある
Express WorkFlow
短時間で大量のイベントを処理するユースケースに最適なワークフロータイプ。
・冪等性(同じ処理を複数回しても結果が変わらない)が担保できる処理
・リアルタイム性が求められる処理
・高頻度で繰り返されるイベント処理
・短時間で完了するタスクのオーケストレーション
[Standard Workflow との違い]
| 比較項目 | Standard Workflow | Express Workflow |
|---|---|---|
| 実行時間 | 最大 1 年 | 最大 5 分 |
| 実行セマンティクス | Exactly-once | At-least-once / At-most-once |
| 課金 | 状態遷移数ベース | 実行回数・時間・メモリベース |
| スループット | 数千件/秒未満 | 数万件/秒以上 |
| ユースケース | 長期処理、監査が必要な処理 | 短期・高頻度処理 |
エラーメッセージ
| “ErrorEquals”:[“States.ALL”] | 実行中に発生するすべてのエラータイプをCatchする。 ※States.ALL:あらゆる既知のエラー名に一致するワイルドカード |
| “ErrorEquals”:[“States.Runtime”] | 実行中の特定のエラータイプだけをCatchする。 |
連携サービス
【併用:Lambda】
ワークフローの個々のステップにビジネスロジックを持つ Lambda 関数 を実装しワークフローを構成する一連のステップのビジネスプロセスを構築する。
[引用サイト]
Resource Groups
【リソース整理】多数のリソース上のタスクを一度に管理および自動化できるサービス。
AWS リソースのグループに対して、セキュリティパッチや更新の適用などのタスクを同時に自動化する。

